辅助标题-定屏幕上
埋点引导:以点带面引导面试官走入自己擅长领域,不要让面试官带着跑。
逻辑清晰:答题开口就是“总分总”思维逻辑清晰。
声音洪亮:普通话标准,声音洪亮,避免长时间 嗯.….,开口必核心,避免"是这样吗 可以吗"
有自信心:我有多年开发经验,能够为公司解决问题并创造价值,技术扎实。
亲和力强:积极倾听,产生互动。
态度适中:适当强硬,尊重并说服面试官自己的答案是正确的。
关联经验:不会的,不能说还要学习,自我否定,应该承认知识盲区→展示解决思路→关联已有经验。
1. 项目负责人
主要的⼯作是参与 前端⼯程化 ,基础设施建设 ,⽐如,三库⼀架 、 多包仓库 、 私有仓库 、 ⽂档系统 、 监控统 、 CI/CD 的开发, 三库⼀架, 也就是公司内部组件库、Hooks库、插件库 ⾃定义脚⼿架,除此之外,也负责了 5个0到1的项⽬开发 以及现有项⽬多条业务线的⼆次开发迭代和维护, 参与落地20多个项⽬开发 , 涉及医疗、物流、⼈⼯智能、⾦融、新能源的ToB ToC项⽬,其中也会参与项⽬需求评审,项⽬评估,⻛险规避 跨部⻔合作沟通,项⽬整体把控,需要说明的是,我作为前端项⽬负责⼈,主要⼯作还是负责公司业务线的项⽬开发落地⼯作,项⽬的基建,项⽬0到1的开发,带过3个前端开发,主要负责项⽬的开发,落地,技术攻关,并没有参与团队的绩效管理。
1. 大前端
概述
大前端通常指的是涵盖从前端界面到服务端的一系列技术栈和开发实践,旨在提供一致且高效的用户体验。它不仅仅局限于传统的网页前端(HTML、CSS、JavaScript),还扩展到了移动端应用开发、桌面应用开发等多个领域。以下是大前端涵盖的主要方面:
| 领域 | 技术栈/工具示例 | 描述 |
|---|---|---|
| Web前端 | HTML、CSS、JavaScript、React、Vue.js、Angular | 构建动态交互式的用户界面,使用现代框架提升开发效率和用户体验。 |
| 移动端开发 | iOS、Android原生开发、Flutter、React Native、Weex | 覆盖iOS和Android平台上的应用开发,通过跨平台工具实现一套代码覆盖多个平台的应用开发。 |
| 桌面端开发 | Electron | 使用Web技术(HTML、CSS、JavaScript)构建Windows、MacOS和Linux应用程序。 |
| 全栈开发 | Node.js | 前端开发者利用Node.js参与后端开发,实现从前端到后端的全流程开发工作。 |
| PWA | 渐进式Web应用技术 | 运用现代Web能力渐进式地改善应用体验,使Web应用具有类似原生应用的功能如离线访问等。 |
| Serverless架构与云服务 | 各类云服务(AWS Lambda, Azure Functions等) | 利用云服务减少后端开发的工作量,专注于前端功能实现,同时更高效地管理资源和服务。 |
强调以用户为中心,通过多种技术手段提供最佳的用户体验,并涵盖了从客户端到服务端的广泛技术领域。
趋势
| 趋势维度 | 核心内容 | 关键技术/代表 | 挑战与机遇 | 行业影响 |
|---|---|---|---|---|
| 跨平台开发演进 | 从Hybrid到原生渲染的技术升级,追求更高性能与一致性 | Flutter、React Native、Tauri、Qwik | 挑战:不同平台特性适配与性能优化; 机遇:降低开发成本,提升多端一致性 | 推动"Learn Once, Run Anywhere"理念,加速中台化建设 |
| 工程化与工具链 | 构建工具智能化与标准化,低代码平台提升开发效率 | Vite、webpack、Turbopack、Monorepo、Joker框架 | 挑战:工具链碎片化; 机遇:自动化程度提升,开发体验优化 | 推动企业级项目交付效率,前端研发进入工业化阶段 |
| 全栈能力融合 | 前端向服务端延伸,BFF层与边缘计算深度结合 | Next.js、Remix、Edge Functions、tRPC | 挑战:前后端职责边界重构; 机遇:端到端开发效率提升,数据流优化 | 驱动全栈工程师需求增长,技术架构向"端到端优化"演进 |
| AI驱动开发 | AI从代码生成到自动化测试全链路渗透,重构开发者工作流 | GitHub Copilot、Cursor、AI监控系统 | 挑战:技术可靠性验证; 机遇:研发效率提升,重复劳动减少 | 催生"AI+前端"研发模式,开发者向逻辑设计与AI协作转型 |
| 新交互范式突破 | 3D/XR/语音交互普及,高性能图形与计算技术开放 | WebGPU、Three.js、WebXR、WebAssembly | 挑战:设备兼容性与性能瓶颈; 机遇:差异化用户体验,开拓电商/教育新场景 | 推动Web进入空间计算时代,重塑数字化体验 |
| 性能优化革命 | 从加载速度到交互流畅度的全链路优化,建立科学指标体系 | Web Vitals、懒加载、CDN、虚拟化渲染 | 挑战:性能与功能平衡; 机遇:通过体验优化直接提升业务转化 | 用户体验成为核心竞争力,驱动技术向"用户价值"转型 |
| 低代码/无代码化 | 平台降低开发门槛,开发者转向复杂逻辑与架构设计 | 钉钉宜搭、腾讯微搭、AI辅助低代码工具 | 挑战:开发者价值重构; 机遇:业务快速迭代,释放创造力 | 推动技术平权,企业研发重心转向业务逻辑与创新 |
| Web3.0与去中心化 | 区块链技术融合,智能合约与去中心化存储应用 | IPFS、智能合约、MetaMask、Web3.js | 挑战:技术门槛高与安全性风险;机遇:构建透明、安全的去中心化应用 | 推动金融、内容领域革新,催生新型去中心化商业模式 |
| 安全与合规升级 | 数据隐私保护与GDPR合规要求倒逼技术升级 | CSP策略、代码混淆、自动化合规检测工具 | 挑战:安全与效率的博弈;机遇:建立可信技术体系 | 提升企业技术合规能力,安全成为架构设计首要考量 |
2. 行业业务
| 行业 | 业务场景 |
|---|---|
| 金融行业 | 1. 资产管理平台:用于投资组合管理、自动化风险评估、收益分析、智能化的财务报表生成。 2. 支付清算系统:支持实时支付、跨链支付、交易清算和自动对接功能。 3. 移动支付应用:包括用户账户管理、转账、支付、消费记录管理等,提供便捷的移动端支付体验。 4. 保险服务平台:保险产品推荐、保单管理、在线保费计算、理赔服务,支持用户个性化定制保险方案。 5. 金融风控系统:整合大数据和 AI 技术,实时监控和预测金融风险,进行贷款风控、信用评估。 |
| 医疗行业 | 1. 电子病历系统(BIM):涵盖患者健康档案管理、病历存储、历史治疗记录,支持数据共享及与医生间的协作。 2. 远程医疗平台:医生可通过平台提供在线诊疗、健康监测、视频会诊、处方开具等服务。 3. 医疗设备管理系统:用于追踪设备状况、维护历史、使用效率,确保设备正常运作并降低医疗事故发生率。 4. 预约挂号与排队管理系统:患者可线上预约医生、查看就诊时间,支持智能排队提醒,提升患者就医体验。 5. 医疗保障平台:整合医保报销流程,支持患者在结算时自动抵扣医保费用。 |
| 物流行业 | 1. 运输管理系统(TMS):提供物流调度、运输路线规划、车辆管理、货物跟踪,优化运输效率并减少成本。 2. 仓储管理系统(WMS):自动化库存管理、订单处理、商品分拣、出入库优化,确保仓库运转高效。 3. 供应链管理系统(SCM):涵盖从采购、库存到物流配送的全链路管理,确保供应链流转顺畅,降低供应链风险。 4. 快递物流管理平台:提供包裹配送、配送状态更新、签收确认、运输路径优化等功能,提升用户体验。 5. 智能货运匹配平台:基于 AI 和大数据进行智能匹配,帮助货主与承运商高效对接,实现智能调度与运输优化。 |
| 新能源汽车业 | 1. 智能电网管理系统:用于电力资源分配、电力调度、负荷预测、电力使用的实时监控与优化,保障电网运行的稳定性和可持续性。 2. 充电桩管理平台:管理充电桩的分布、使用情况,支持充电记录查询、实时电量展示,优化电动车用户充电体验。 3. 光伏发电管理平台:监控太阳能光伏设备的发电情况,分析发电效率,支持设备状态监控与异常告警,推动绿色能源发展。 4. 能源交易平台:支持企业和个人参与能源交易,提供绿色电力交易、碳排放配额交易,助力新能源市场化发展。 5. 新能源车队管理系统:包括新能源车队的调度、路线规划、实时监控、充电站信息查询,帮助企业降低能耗和运营成本。 |
| 电商行业 | 1. 商品管理系统:支持商品上架、分类管理、定价、库存更新、销售分析,帮助商家管理商品全生命周期。 2. 订单管理系统:包括订单生成、支付处理、发货管理、售后服务,提供一站式订单管理服务。 3. 客户关系管理(CRM)系统:分析用户行为,提供个性化营销策略、忠诚度计划、积分管理等,帮助电商平台提升用户粘性。 4. 营销推广系统:通过数据分析进行精准广告投放,支持优惠券发放、折扣促销、限时抢购等营销活动,提升平台营销效果。 5. 多渠道分销系统:支持 B2B、B2C 业务,打通线上线下销售渠道,实现多平台商品与库存管理。 |
| 教育行业 | 1. 在线教育平台:提供课程学习、考试系统、作业提交、视频直播、录播课程等功能,帮助学生随时随地进行学习。 2. 校园管理系统:包括学生信息管理、排课系统、考勤记录、成绩管理,优化学校日常运营效率。 3. 远程教育系统:支持教师与学生实时互动授课,提供多种互动方式和答疑、打分、作业批改功能。 4. 在线考试系统:提供考试报名、自动阅卷、成绩分析、排名统计功能,实现高效考试管理。 5. 培训机构管理系统:帮助机构管理学员报名、课程安排、收费处理、培训进度跟踪,提高管理效率。 |
| 零售行业 | 1. 会员管理系统:通过积分系统、会员等级、消费记录管理、个性化推荐,帮助零售商提高会员粘性和复购率。 2. 库存管理系统:支持实时库存更新、商品入库出库管理、库存预警,帮助商家优化补货策略。 3. 收银系统:支持多种支付方式的 POS 收银系统,自动生成销售报表和财务报表,提升门店运营效率。 4. 促销活动管理系统:支持优惠券发放、折扣活动、会员特惠、满减促销等多种促销活动,结合用户行为数据进行精准推送。 |
| 制造行业 | 1. 生产管理系统:支持多工厂的生产计划、工艺流程、产能分析,实时跟踪生产进度,确保生产效率。 2. 供应链管理系统:帮助企业管理原材料采购、供应商协作、物流调度,优化供应链环节,确保物料及时供给。 3. 质量管理系统(QMS):涵盖产品质量检测、质量追溯、异常处理,确保产品符合标准。 4. 设备管理系统:对生产设备进行实时监控,管理设备的运行状态、保养计划、维修记录,降低设备故障率。 5. 成本控制系统:跟踪每个生产环节的成本,帮助企业优化成本控制策略,提高生产效率和资源利用率。 |
| 房地产行业 | 1. 房产交易平台:提供房源发布、在线看房、价格评估、合同签署、交易撮合等功能,提升房产交易的便捷性与透明度。 2. 租赁管理平台:支持租赁合同签订、租金支付、租期管理、租金缴费提醒,提升房东和租客的租赁体验。 3. 物业管理系统:提供物业费缴纳、维修申请、社区公告、住户服务等功能,提升社区物业管理的智能化水平。 4. 房屋销售管理系统:支持楼盘信息展示、销售数据统计、客户预约、意向跟踪等功能,帮助房产公司提升销售业绩。 5. 房地产金融平台:提供房贷申请、审批、还款管理、利率计算等功能,打通购房与金融服务链条。 |
3. 项目0到1
| 阶段 | 优化方案与深入总结 | 权威性与备注 |
|---|---|---|
| 1. 路由设计 | 1. 拆分路由: 一级路由包括 注册、登录、layout 布局、404 页面,确保页面结构清晰可维护; 二级路由为 layout 下的所有功能模块,减少路由嵌套,提升用户体验。 2. 权限设计: Vue 采用 RBAC 权限控制,通过用户角色动态加载路由和权限; React 通过封装高阶组件 AuthRouter,判断 token 进行鉴权,未登录用户自动重定向至登录页。 | 路由设计与权限管理 是确保前端应用结构合理与访问安全的核心,避免了不必要的权限设置与性能损耗。 |
| 2. 状态设计 | 1. Vuex/Pinia:将状态模块化处理,将 mutations, actions 和 getters 按照业务逻辑进行拆分,确保状态管理清晰、可维护。 2. Redux:拆分 store, action, reducer,结合 Redux-thunk 处理异步状态,提升数据流的灵活性和可追踪性。 | 状态管理 是项目的核心之一,通过模块化拆分和异步状态管理,确保应用的灵活性与可扩展性。 |
| 3. axios 二次封装 | 1. 请求拦截:在请求头中自动添加 token,确保每次请求都带有身份验证信息,防止无授权请求。 2. 响应拦截:简化响应数据,统一处理 401 错误(未授权),自动清除用户信息和 token,并重定向到登录页。 3. 请求重试机制:为网络请求添加重试机制,设置最大重试次数(如 3 次),在请求失败时自动重试,增强请求的健壮性。 4. 设置统一 baseURL 和请求超时机制,确保请求时长受控,避免长时间卡顿。 | axios 重试机制 增强了网络请求的稳定性,特别适用于网络不稳定或 API 请求频繁的场景。 |
| 4. 区分环境与全局变量 | 1. 环境区分:使用 .env.development 和 .env.production 文件定义不同环境变量,确保开发和生产环境中使用的变量各自独立,避免误用。 2. 全局变量:通过 process.env 定义全局 baseURL 和其他配置,保证项目能够根据不同环境加载正确的资源。 3. 根据环境变量 动态调整日志输出,开发环境打印详细调试日志,生产环境仅记录错误和关键信息,减少不必要的日志输出。 | 环境区分 和 全局变量管理 是前端项目中必不可少的部分,确保项目在不同环境中的行为一致且可控。 |
| 5. 主题定制与动态换肤 | 1. UI 框架主题定制:在 theme.less 中定义自定义 CSS 变量,覆盖 Element UI、Ant Design 或 Vant 等组件库的默认样式,实现个性化品牌定制。 2. 动态换肤:通过 CSS 变量实现动态换肤功能,用户可以在应用中自由切换主题,无需重新加载页面。 | 动态换肤 提升了用户体验和项目的灵活性,确保组件库主题能够适配多种场景。 |
| 6. 代码规范与风格统一 | 1. 使用 ESLint 和 Prettier 进行代码风格检查和自动格式化,在代码提交前校验代码符合项目规范。 2. 配置 Husky 和 lint-staged,确保每次提交代码前自动进行风格检查和格式化,防止低质量代码进入主分支。 | 代码规范化 是保证团队协作和代码可维护性的关键,避免了风格不一致和代码混乱问题。 |
| 7. Gitflow 工作流管理 | 1. Gitflow:使用 Gitflow 工作流管理分支,按照 master、develop、feature、release 和 hotfix 进行分支管理,确保开发和发布过程条紊有序。 2. 在每个功能开发的最后阶段,合并到 develop 分支进行集成测试,确保在发布之前解决潜在的合并冲突和问题。 | Gitflow 是大型项目标准的版本管理模式,确保多团队协作和项目迭代顺畅。 |
| 8. 跨域问题解决方案 | 1. CORS:在后端服务器配置 CORS 头,允许前端不同域的请求访问资源,确保跨域数据交互安全。 2. Nginx 反向代理:通过 Nginx 配置反向代理,将所有前端请求转发到同一域名下,规避浏览器的跨域限制。 3. 在开发阶段通过 webpack-dev-server 配置跨域代理,简化本地开发和调试中的跨域问题。 | 跨域处理 是前端部署分离项目的关键,通过反向代理和 CORS 配置,确保数据交互的安全性和兼容性。 |
| 9. 部署与自动化构建 (CI/CD) | 1. 手动部署:通过 npm run build 打包项目,将打包后的静态文件手动上传到服务器,适用于简单项目或小规模团队。 2. CI/CD 自动化部署:通过 Jenkins 或 Github Actions 配置持续集成与持续部署流程,每次提交代码后自动运行测试、打包,并将构建结果自动部署到服务器。 3. Docker 和 Kubernetes:在生产环境中采用容器化部署,使用 Docker 构建镜像,并通过 Kubernetes 实现集群管理和自动扩容,确保系统的高可用性和扩展性。 | CI/CD 自动化部署 和 容器化部署 提升了项目发布的稳定性和效率,适合大型项目的持续交付需求。 |
| 10. 性能监控与错误捕获 | 1. 使用 Sentry 或 LogRocket 监控项目的线上性能和错误,实时捕获用户侧的异常情况,便于及时修复。 2. 结合 Google Lighthouse 进行性能监控,定期评估项目的加载速度、交互响应等性能指标,确保项目处于最佳状态。 | 性能监控 和 错误捕获 是生产环境中保证项目稳定运行的关键,确保问题能够在第一时间被发现和修复。 |
4. 场景题
1. 页面滑动时越滑动越慢,如何最快速定位问题
| 步骤 | 操作描述 |
|---|---|
| 1. | 打开 DevTools,切换到 Performance 面板。 |
| 2. | 点击 Record 开始录制,进行滑动操作。 |
| 3. | 停止录制后,查看 FPS(帧率) 和 长任务(Long Tasks)。 低于 60FPS 表示页面渲染有问题。 长任务 会暴露出导致页面卡顿的具体原因,比如 JavaScript 执行过慢、频繁的重排、内存泄漏等。 |
2. 项目亮点和难点
1. 前端工程化
作为项⽬负责⼈,经过多个项⽬迭代需不断总结的前端⼯程化⽅案 ⼯程化是⼀套解决问题的思想 涉及前端的开发、测试、部署为了 降本 和 增效两个⽅⾯
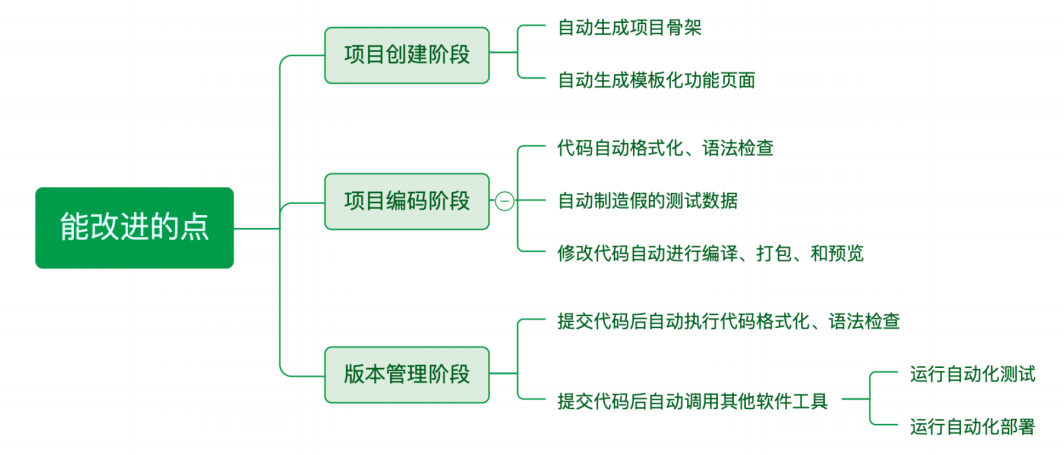
使⽤ Node.js 构建脚⼿架⼯具,通过 Commander.js 或 Inquirer.js 实现命令⾏交互,并结合 Yeoman 或 Plop.js 进⾏项⽬模板⽣成,通过命令⾏参数快速⽣成标准化的项⽬结构、⽂件模板、依赖管理和构建⼯具 ,在短时间内搭建基础架构,确保项⽬的规范统⼀ ,还集成了Git Hooks 和 CI/CD 流程,⽀持⾃动化构建、测试和部署,覆盖项⽬创建、运⾏、测试、提交和发布。
| 搭建基础-公司内部自定义脚手架详细步骤 | 实现步骤 | 备注 |
|---|---|---|
| 1. 项目初始化 | 1. 使用 npm init 或 yarn init 创建项目,定义 package.json,合理配置依赖、脚本。2. 配置 .gitignore,并引入 Git 分支管理规范 Gitflow,确保分支管理规范性,使用 master(生产)、develop(开发)、feature(功能)、release(发布)和 hotfix(修复)等分支。3. 引入 Commitizen(cz-cli)强制执行 Git 提交规范,规范化提交信息,自动生成 changeLog。4. 采用 Monorepo 和 pnpm workspaces 管理多组件库和插件的代码,确保各包间的依赖管理和版本控制高效。 | Gitflow 和 Commitizen 是主流的版本管理和提交规范,pnpm workspaces 与 Monorepo 实现高效的多包管理。 |
| 2. 配置开发环境 | 1. 使用 Webpack 或 Vite 构建工具,确保构建速度和编译效率,使用 Babel 处理现代 JS 特性。2. 引入 ESLint 和 Prettier 进行代码检查和格式化,保证代码质量。3. 利用 Husky 和 Lint-staged 配置 Git 钩子,确保代码提交前轻自动化格式化和检测。4. 引入 Storybook,为组件库提供独立的开发和测试环境,使开发者能高效开发、测试每个组件。 | pnpm workspaces 可以高效管理多个组件库的依赖,Storybook 提供了可视化的组件开发和展示环境,提升开发体验。 |
| 3. 模块化设计 | 1. 使用 模块化架构 设计脚手架,允许开发者按需选择模块,最大化灵活性,确保功能模块粒度细。2. 提供统一的 API 接口 和钩子机制,使模块之间的通信和组合更加便捷。3. 使用 pnpm workspaces 配合 Monorepo 模式,将各功能模块和组件化封装,确保可维护性和可扩展性。4. 确保每个模块设计为 低耦合、高内聚,使组件库和插件能独立开发、测试,并实现高效复用。 | pnpm workspaces 高效管理模块依赖,提升复用性,Monorepo 提供了模块和组件的统一管理架构。 |
| 4. 项目模板创建 | 1. 在 templates 文件夹中准备多种技术栈模版(React、Vue、Node.js 等),并确保每个模版符合最佳实践。2. 使用 Inquirer.js 实现交互式命令行选择框架、状态管理工具、组件库等。3. 提供 模版生成脚本,根据用户选择自动生成项目结构,自动安装依赖。 | 模版系统 和 用户交互式 提升了脚手架的易用性,生成脚本提高了开发效率。 |
| 5. CI/CD | 1. 使用 Jenkins 或 GitHub Actions 实现 CI/CD 流程,确保每次提交自动化测试、构建和部署。2. 自动化打包、优化、上传构建的静态资源,提升性能。 3. 将打包的结果发布到 npm 或私有仓库,确保用户通过命令行便捷安装:npm install -g <your-cli>。 | CI/CD 流程是现代开发标准,自动化测试、构建、发布提高了团队的开发效率。 |
| 6. 文档与测试 | 1. 提供详尽的 README 和 API 文档,通过 docsify 或 VuePress 自动生成文档页面。2. 使用 Jest 或 Mocha 编写单元测试,确保各组件和功能模块的稳定性。3. 通过 Storybook 展示每个组件的使用方法,并结合 pnpm workspaces 管理组件的依赖和共享测试环境,确保模块化开发和测试无缝进行。 | Storybook 为组件库提供了独立开发和测试环境,pnpm workspaces 实现了多个包之间的依赖管理和共享测试环境。 |
| 7. 发布脚手架 | 1. 发布到 npm 或私有仓库,使用 SemiVer 管理版本,并提供长期支持(LTS)。2. 持续迭代、修复问题,并通过 changelog 记录版本更新,确保用户了解新版本内容。3. 定期维护和更新脚手架,结合社区反馈,优化功能和用户体验。 | SemiVer 版本管理和 changelog 是项目长期维护的重要工具,确保用户了解更新内容。 |
2. 监控系统
1. 市面主流3款
| 监控系统 | 主要功能 | 应用场景 | 缺点 |
|---|---|---|---|
| Sentry | 提供前端错误监控和性能分析,能够捕捉 JS 错误、分析崩溃信息、进行源映射解析,还支持实时报警。集成简单、覆盖面广,支持各种前端框架,如 React、Vue 和 Angular。 | 适用于各类前端项目,尤其是生产环境中需要快速定位和修复问题的场景,帮助开发者减少用户影响并提升应用质量。 | 对于小型项目,某些高级功能需要付费,复杂项目的自定义化功能较少,依赖第三方服务的限制也较大。 |
| LogRocket | 通过会话回放和前端性能监控,重现用户操作,捕捉页面渲染问题、API 请求、JS 错误等。开发者可以清楚了解用户行为,定位问题根源并加以修复。 | 前端用户体验监控的最佳选择,适合需要跟踪用户操作并复现问题的场景,特别在处理用户反馈和分析性能瓶颈时表现出色。 | 存储大量用户会话数据可能增加成本,长时间会话可能对性能有影响,数据量大的情况下对存储和管理要求较高。 |
| New Relic Browser | 全栈监控中的前端模块,提供全面的页面加载、JS 错误、AJAX 请求监控,结合后端监控,提供端到端的性能分析,帮助企业级应用实现从前端到后端的全面监控和优化。 | 适用于大型复杂项目,尤其是前后端监控需要联动的场景,帮助企业级应用实现从前端到后端的全面监控和优化。 | 对中小型团队来说,费用较高且设置较复杂,过度依赖第三方工具,定制化能力有限,不适合非常灵活的监控需求。 |
2. 自己实现监控系统
| 模块 | 详细设计思路 |
|---|---|
| 1. SDK架构设计 | 1. 高内聚低耦合设计:各功能模块(如错误监控、性能监控、用户行为追踪等)之间通过消息机制解耦,每个模块内部事件通过进程间通信,避免直接调用,使得模块独立并可扩展。 2. 插件化与按需加载:核心功能通过插件机制动态加载,用户可根据项目需求下载特定功能插件,减少SDK体积。 3. 兼容性与框架无关:确保多种前端框架(如Vue、React、Angular)无缝集成,避免使用特定框架的生命周期或事件机制,采用浏览器API提供通用能力。 |
| 2. SDK初始化配置 | 1. 动态配置与环境感知:SDK初始化时提供一个统一的init()方法,接受配置项(如监控级别、日志上报策略、数据加密策略等),并可根据环境变量(如开发、生产)自动调整配置,适配不同环境需求。2. 自动化配置优化:SDK默认配置针对常见场景优化,开发者可通过minimal配置快速完成,适合小型项目快速使用,高级用户可自定义每个模块的行为,调整监控密度与日志细致度。 |
| 3. 错误监控设计 | 1. 全量堆栈捕获与分类:不仅通过window.onerror捕捉DOM错误,还要通过try-catch捕获业务代码中的异常,并提供错误类别(如脚本资源加载失败、Promise异常、跨域请求等),让开发者快速定位问题源头。2. 错误堆压缩及错误摘要聚合:使用 Error.stack提供详细的堆栈信息,便于复现错误进行分析拆分,减少同质错误的冗余上报。堆维信息通过后端计算生成错误摘要,并来源映射生成(如Source Map),实现错误堆栈的还原,方便调试。 |
| 4. 用户行为追踪设计 | 1. 高效事件监听与行为优化:通过事件委托方式绑定click, input等用户交互事件,减少性能开销。对用户行为追踪做智能采样,避免在频繁操作下记录大量冗余数据;当操作频率过快时,进行数据去重或合并处理,避免影响性能和传输压力。2. 操作序列化与防抖节流:记录用户操作序列,将用户行为序列化为帧数据压缩,支持后台还原重现用户操作场景,结合错误监控和性能监控的数据,还原用户出现的问题的具体操作步骤。 |
| 5. 性能监控设计 | 1. Web Vitals指标扩展:基于Performance Web Vitals 监控核心Web Vitals指标(如FCP, LCP, CLS, FID),支持自定义性能指标扩展,开发可监控业务关键节点的性能(如首屏渲染时间、自定义交互延迟)。 2. 长任务检测与报警:监控页面中执行时间超过50ms的长任务,并分析生成性能瓶颈的原因(如阻塞渲染层、脚本执行耗时等),帮助开发者优化并优先化页面加载问题。 3. 性能数据智能化分析与报告:自动生成性能报告,包括资源加载分析、交互率、页面卡顿等数据分析,定期将报告发送至开发团队,帮助优化页面性能。 |
| 6. API请求监控设计 | 1. API请求监控与链路跟踪:通过重写XMLHttpRequest 和 fetch 的原型方法捕获所有HTTP 请求,并记录每个请求的详细信息(如请求方法、耗时、状态码、响应大小、错误等),支持跨域跟踪,通过traceId 或 spanId 将请求串联起来,帮助开发者追踪完整的前后端服务调用链。 2. API 健康度监控:监控API的成功率、失败率、超时等指标。生成健康度报告,并在API 出现问题时及时报警,帮助运维团队保证服务稳定性。 |
| 7. 崩溃与内存监控 | 1. 内存泄漏监控与崩溃分析:通过 Performance.memory 定期采集内存使用情况,结合页面运行时的DOM 操作频率、数据变化、分配与释放等维度,通过监控页面的内存占用,发现内存增长导致浏览器崩溃的情况,开启开发者提前定位问题。 2. 崩溃快照与恢复机制:当页面崩溃或未响应时,自动保存崩溃快照,捕捉页面状态(如DOM 结构、内存快照、当前任务队列等),帮助分析崩溃原因,SDK 提供恢复机制,允许用户重启加载页面后恢复未保存的数据,减少用户流失。 |
| 8. 日志与报警设计 | 1. 日志存储与智能上报:通过LocalStorage 或 IndexedDB 缓存用户操作日志和错误日志,确保日志不会因网络问题而丢失。当网络恢复时,SDK 自动进行批量上传,避免频繁上报带来的网络压力。 2. 分级缓存与优先级管理:对于重要日志(如JS 错误、重大错误),日志会分级处理,高优先级日志(如崩溃、重大错误)立即上报,低优先级日志则缓存或延时上报,确保日志的实时性与时序。 3. 自定义预警规则与频限限制:支持开发自定义报警规则(如JS 错误过多、API 超时、内存泄漏等),并通过邮件、短信、Webhook 等方式进行报警,为避免过度报警,SDK会对报警频率进行控制,确保每个问题只报警一次,减少开发者维护负担。 |
| 9. 数据隐私与安全 | 1. 监控数据加密与传输安全:所有收集的数据(如用户行为、错误日志、性能报告等)在传输时都将进行AES 或RSA 加密,防止数据拦截或篡改。同时,所有的存储也都经过加密处理,确保敏感信息的安全。 2. 隐私合规与用户同意:确保SDK 收集的数据符合GDPR 等法律法规,用户需明确同意后方可进行数据收集。支持用户撤回同意时自动停止数据上报,并清除已有的用户数据,确保数据合规。 |
3. GA埋点方案
| 方案类型 | 实现步骤 | 优点 | 缺点 | 适用场景 | 优化策略 |
|---|---|---|---|---|---|
| 手动埋点 | 1. 引入 GA SDK: <script async src="https://www.googletagmanager.com/gtag/js?id=GA_TRACKING_ID"></script>2. 手动调用 GA API: gtag('event', 'action', {'event_category': 'category', 'event_label': 'label'}); | 1. 精准追踪 2. 灵活控制 3. 数据准确 | 1. 工作量大,易遗漏 2. 难以维护,扩展性弱 | 小型项目,关键行为跟踪(如注册、订单) | 1. 封装埋点函数:减少重复逻辑 2. 配置化管理:集中管理埋点,简化维护 3. 结合 A/B 测试:提升用户体验优化 |
| 自动化埋点 | 1. 全局监听用户行为:如 click 事件2. 自动解析 DOM 元素,动态上报埋点 | 1. 快速部署 2. 覆盖全局行为,减少手动工作量 | 1. 容易误报 2. 对 DOM 结构敏感,性能影响大 | 复杂页面、大量行为跟踪(如电商平台) | 1. 事件代理:优化性能 2. 黑/白名单机制:精准过滤无关数据 3. 分区域监听:提高数据质量,减少误报 |
| 无埋点方案 | 1. 引入第三方 SDK(如 Hotjar) 2. 自动捕捉所有用户行为并上报分析 | 1. 减少开发成本 2. 全局实时监控 | 1. 数据冗余大 2. 精准度低,依赖外部服务 | 大型项目,全面监控所有行为(如社交平台) | 1. 数据去重与过滤:提升数据质量 2. 结合手动埋点:保证关键行为追踪 3. 选择最优 SDK:降低成本,提升分析效率 |
3. 组件库封装
| 组件库架构能力维度 | 实现思路 |
|---|---|
| 1.Monorepo 管理模式 | 1. Monorepo 优势:通过 Monorepo 管理多个包,优化了依赖共享、代码复用、统一配置的开发体验,解决了多仓库管理带来的维护复杂性。可根据项目规模灵活选择 Lerna(轻量场景)或 Nx(适合大型项目),尤其在 Nx 的任务缓存和分布式任务执行下提升构建速度。 2. Monorepo 实践中的挑战与解决方案:解决跨包依赖复杂性,采用集中管理与版本发布策略,防止版本号紊乱。自动化构建和发布脚本与 CI/CD 集成,实现跨库协作。 |
| 2. pnpm workspace 使用 | 1. 高效依赖管理与缓存机制:相比 npm 和 yarn,pnpm workspace 提供了更高效的依赖管理,支持软链接机制,并解决了模块间 Hoisting 冲突,大幅减少磁盘占用。特别是在 Monorepo 场景下,pnpm workspace 通过共享依赖优化了构建时间和空间占用。 2. 一致性与性能保障:确保各子项目依赖版本统一,避免多个版本冲突问题,尤其是在微前端架构中,能确保各模块无缝集成与运行。 |
| 3.Changelog 自动生成 | 1. 标准化版本发布与变更记录:通过 semantic-release 实现 Git 提交自动生成 changelog,确保版本发布的规范性和一致性,支持多包的自动化变更日志管理。根据 Conventional Commits 标准化提交记录,自动生成详细的版本发布说明,提高团队协作效率。 2. 复杂 Monorepo 场景的 Changelog 管理:在组件库中,每个子包都有独立的日志和 changelog 管理,清晰跟踪每个包的变更历史。 |
| 4. 版本管理与发布策略 | 1. 独立版本 vs 统一版本:根据组件库间的依赖关系,选择独立版本或统一版本策略。在依赖较少的情况下,独立版本管理更灵活;而强依赖组件则需要保持统一版本号,简化管理流程的简洁性。 2. 自动化发布与语义化版本控制:通过 CI/CD 集成,实现自动化发布,在主分支合并时自动触发测试、构建和发布,采用 Semantic Versioning (Semver) 规范,明确区分修复、功能添加与破坏性更新。 |
| 5. 组件库封装设计 | 1. 按需加载与 Tree Shaking:确保组件库支持按需加载,避免全量引入组件,使用 babel-plugin-import 配置按需加载,确保与 Webpack 或 Rollup 的 Tree Shaking 配合使用,移除未使用代码,提升构建性能。 2. TypeScript 类型支持:提供全局和按需加载的 TypeScript 类型声明,确保开发者获得完备的类型推断支持,提升组件库的可维护性与开发体验。 |
| 6. 文档与测试 | 1. 文档自动化与展示平台:通过 Storybook 或 Docusaurus 生成高度交互的组件文档,展示各组件的状态、交互效果,提升组件库的可用性与开发体验。 2. 测试覆盖率与自动化测试:使用 Jest 进行单元测试,确保组件功能的完整性;使用 Cypress 进行端到端测试,保证在实际业务中的可靠性。使用 codecov 或 coveralls 监控测试覆盖率,确保组件库的高质量输出。 |
| 7. 版本兼容与升级策略 | 1. 严格遵循 Semver 规范:采用 Semantic Versioning,确保版本号清晰区分功能更新、修复和重大变更。对于破坏性更新,提供详细的迁移指南,确保用户可以平滑升级。 2. 向后兼容策略:为常用 API 保持向后兼容,避免小版本更新时对用户造成困扰。提供渐进式迁移策略,帮助用户快速适应新版本变化。 |
| 8. 组件库的架构演进 | 1. 从基础组件到业务组件的扩展:组件库的架构支持从基础 UI 组件扩展到业务组件,保证各模块的独立性和复用性。业务组件通过组合基础组件,提供更高层次的封装。 2. 微前端与分布式开发支持:组件库设计要适应微前端架构,支持跨项目共享组件,结合 Module Federation 或 Qiankun 进行分布式组件管理,支持多个项目共同使用组件库而不产生本地冲突。 |
| 9. 多端适配与性能优化 | 1. 响应式设计与跨端支持:组件库需要支持响应式设计,确保在不同屏幕尺寸和设备上的一致性表现。使用 CSS 变量和媒体查询,实现灵活的样式适配,支持 PC、移动和大屏应用场景。 2. 性能优化与动态加载:通过 lazy loading 优化性能,按需加载组件;对于大数据量展示,使用虚拟滚动(Virtual Scrolling)优化渲染性能。确保组件库在高性能场景下依然流畅运行。 |
| 10. 国际化与本地化支持 | 1. 国际化(i18n)策略:组件库要支持多语言配置,使用 vue-i18n 或 react-intl 等插件,实现文案的动态加载与切换,确保组件库能够在全球化项目中使用。 2. 多地域本地化支持:组件库需支持本地化的 时间、货币、单位等格式,通过配置实现自动化处理,确保业务在不同地区和文化下的正确使用。 |
1. Monorepo工具对比
| 工具 | 定义及功能 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Rush | 微软主导的企业级Monorepo管理工具,专为大规模项目设计,提供增量构建、全局缓存、依赖管理和CI集成。 | 1. 增量构建和全局缓存,大幅提高构建效率。 2. 版本锁定,依赖管理清晰,确保一致性。 3. 适合大团队,支持复杂CI/CD流程。 | 1. 学习成本高,初次配置复杂,需要深入理解工具机制。 2. 小型项目不推荐,复杂度过高。 | 超大规模企业项目,团队协作密集、复杂依赖和构建场景,如企业级平台、跨团队开发。 |
| Lerna | 轻量化Monorepo工具,支持多个包的版本管理、发布和增量构建,适合快速迭代。 | 1. 易于上手,轻量灵活,适合中小团队。 2. 支持常用包管理工具,如npm、Yarn,兼容性强。 | 1. 缓存机制弱,大型项目性能有限,构建速度慢。 2. 复杂项目中依赖管理效率较低,难以处理跨项目依赖。 | 中小型项目,版本发布频繁,需求变动大,快速交付的场景。 |
| Yarn Workspaces | Yarn扩展功能,支持多个包依赖共享及快速安装,简化依赖管理流程。 | 1. 与Yarn深度集成,安装速度快,依赖共享方便,减少重复安装。 2. 操作简便,配置轻量,适合小团队快速上手。 | 1. 不适合复杂项目,灵活性有限,构建能力较弱。 2. 缺少复合构建和依赖优化的支持,难以应对大型项目。 | 中小型项目,依赖管理简单,注重开发效率的场景;或已有Yarn生态的项目。 |
| pnpm Workspaces | 使用硬链接实现高效依赖共享,优化磁盘空间占用,提升依赖安装速度,适合大规模依赖管理。 | 1. 安装速度快,磁盘占用小,硬链接机制提高依赖共享效率。 2. 严格依赖管理,避免版本冲突。 | 1. 相较于Yarn,社区支持较弱,复杂项目集成难度较高。 2. 初次配置复杂度较高,需要时间适应。 | 适合需高效依赖管理和磁盘优化的大型项目,特别是依赖多且重,性能要求高的项目场景。 |
| Nx | 全面性的Monorepo解决方案,支持前后端协同开发,适用于微前端、微服务架构,具备增量构建和缓存机制。 | 1. 增量构建和缓存机制显著提升构建效率。 2. 支持微前端、微服务及多语言开发,适应复杂项目需求。 3. 提供可视化工具,便于监控依赖关系和任务流。 | 1. 学习曲线陡,初次配置复杂,依赖管理难度大,需结合具体项目细节配置。 2. 大型项目下的依赖分析和任调度可能产生额外管理成本。 | 适用于大型项目,涉及前后端协作、微前端或微服务架构,尤其需要高效构建和复杂依赖管理的场景,如企业级应用和技术平台。 |
4. 复杂万能表单组件
| 万能菜单 | 全面优化与深入总结 |
|---|---|
| 1. 需求背景 | 1. 业务场景与挑战:传统场景中功能复杂且难以满足需求,尤其在后台管理系统、大型 ToB 项目中,表单字段复杂、动态配置多、联动逻辑频繁等场景对系统灵活性提出更高要求。 2. 调用用户信息存储模式:组件需通过配置驱动实现系统应用,以最小开发成本应对复杂业务场景,避免手动编程的瓶颈和维护难度。 |
| 2. 技术流程 | 1. React-Hook-Form + useReducer:React-Hook-Form 是轻量且高性能的表单管理库,尤其适合含复杂多表单项场景,减少不必要的渲染流量,确保性能稳定;通过 useReducer 处理复杂表单状态,结合 useContext 实现跨组件状态共享与通信。2. 数据自动缓存与渲染优化:动态生成表单项,结合 React.memo 进行深度性能优化,避免表单驱动时的重复渲染,确保性能有效控制。3. TypeScript 全覆盖:为表单系统提供类型支持,确保复杂项目中稳定性和开发体验,减少运行时错误。 |
| 3. 配置驱动表单实现方案 | 1. 动态配置与结构定义:通过 JSON 或 JS 对象定义表单结构(字段类型、验证规则、联动逻辑),避免手动编程;配置文件包含核心信息:字段类型(如 input、select)、验证规则(必填、正则匹配)、联动逻辑(dependencies)、数据源(dataSource)等。2. 字段生成与联动机制:使用混合模块处理复杂表单,结合 useEffect 实现字段动态联动,确保表单实时响应数据变化。3. 动态配置与异步加载:通过 setValue 和 trigger 动态调整规则,支持异步数据加载和表单回调。 |
| 4. 复杂状态管理与联动机制 | 1. useReducer 管理复杂状态:通过 useReducer 组织表单状态,清晰管理多层数据和字段类型,通过 dispatch 实现状态变更,确保表单值、验证信息等完整性。2. 字段间联动通道:基于 dependencies 定义表单项依赖关系,允许字段变化动态调整其他字段的显示状态、验证规则和数据源,通过 useEffect 监测变化并触发更新。3. 数据转换与性能平衡:结合输入实时数据转换机制,减少不必要计算,确保性能与用户体验平衡。 |
| 5. 异步处理与渲染优化 | 1. 局部渲染与防抖机制:使用 lodash.debounce 实现防抖处理,避免频繁触发渲染逻辑,仅在必要时更新表单状态。2. 虚拟化渲染技术:大规模表单中采用按需渲染和虚拟滚动技术,避免一次性渲染全部表单项。 3. 异步数据加载优化:支持异步加载 select、checkbox 等数据源,通过 Promise.all 同步加载多数据源,提升加载速度。 |
| 6. 可扩展性设计 | 1. 自定义表单元素与接口扩展:支持传入自定义组件(如日期选择器、富文本编辑器),通过开放接口实现组件注册与上下文集成。 2. 多语言与图形化支持:通过配置文件传递多语言内容,结合 i18next 实现多语言切换;提供图形化布局配置工具。3. 响应式布局适配:支持弹性布局、栅格布局和自定义布局,满足多终端适配需求。 |
| 7. 文档与测试支持 | 1. Storybook 交互文档:生成交互式文档展示表单元素的使用场景和状态,结合 Docusaurus 自动生成技术文档。 2. 单元测试与 E2E 测试:通过 Jest 和 Cypress 进行单元测试和端到端测试,覆盖复杂交互逻辑。3. 测试覆盖率与 CI/CD:使用 Codecov 监控测试覆盖率,结合 GitHub Actions 实现持续集成与自动化发布。 |
| 8. 版本管理策略 | 1. Semver 版本规范:遵循语义化版本控制(Major/Minor/Patch),提供详细迁移指南,确保 API 向后兼容。 2. 自动化发布与 Changelog:通过 semantic-release 自动化版本发布,根据提交记录生成 Changelog,提升版本管理透明度。 |
| 9. 微前端与分布式开发 | 1. 微前端集成支持:通过 Module Federation 或 qiankun 实现跨应用表单组件共享,减少重复开发成本。2. Monorepo 协作模式:使用 Lerna 或 Nx 管理多包仓库,结合 Yarn Workspaces 优化依赖管理与构建流程。 |
| 10. 性能监控与优化 | 1. 线上性能监控:集成 Sentry 或 LogRocket 实时捕获表单异常和性能瓶颈。2. 性能优化策略:结合代码分割(Code Splitting)、缓存策略和懒加载技术,持续优化表单渲染与交互性能。 |
5. 低代码
1. 市面低代码框架
1.收费产品
| 平台名称 | 所属公司 | 使用场景 | 框架/技术栈 | 特点和优势 |
|---|---|---|---|---|
| 宜搭 | 阿里云 | 企业级业务管理、流程自动化,适用于中大型企业的业务应用开发,如财务管理系统、人力资源系统、项目管理工具等。 | 基于 Ant Design 的前端框架,后端主要使用 Java 和 Spring Boot,支持与阿里云其他产品集成。 | 拥有强大的数据管理功能和丰富的业务组件库,支持多种外部系统集成,适合复杂的企业应用场景。 |
| 飞书多维表格 | 字节跳动 | 适用于中小型企业内部的协作办公场景,如数据报表生成、简单的工作流审批、团队协作工具等。 | 使用 React 技术栈,后端基于字节跳动的云端服务,支持与飞书其他产品无缝集成。 | 界面简洁,适合轻量级业务需求,结合飞书的协作能力,提供了强大的团队协作与数据处理能力。 |
| 轻流 | 轻流科技 | 适用于中小企业的业务流程自动化、客户关系管理(CRM)、企业数据管理(ERP)等场景,尤其适合自定义表单与工作流审批场景。 | 前端基于 Vue.js,后端使用 Node.js 和 Express 架构,数据库为 MySQL。 | 强调表单自定义与流程自动化,用户可以通过拖拽方式快速构建业务流程,支持第三方系统集成(如企业微信、钉钉等)。 |
总结:
开源性:⽬前国内主流的低代码平台⼤多为闭源软件,提供的主要是 商业化产品 和 企业解决⽅案。这些平台提供⾼度的可定制性和业务⽀持,但在源码⽅⾯不公开,⽤户只能在平台上进⾏业务开发,⽽⽆法获取或修改平台底层代码。
2.免费产品
| 平台名称 | 所属公司 | 使用场景 | 技术栈/框架 | 特点和优势 | Github链接 |
|---|---|---|---|---|---|
| Formily | 阿里巴巴 | 专注于复杂表单开发,适合后台管理系统、数据驱动应用、动态表单构建。 | 前端:React、Vue | 强大的表单生成器,支持跨框架使用,灵活的表单布局和数据绑定,支持动态生成和复杂验证逻辑,广泛应用于企业内部系统。 | Formily |
| Lowcode Engine | 阿里巴巴 | 复杂组件拖拽式开发,适用于中大型企业内部系统(如 CRM、ERP、业务流程管理)。 | 前端:React、Vue,基于 Ant Design 组件库 | 支持低代码构建企业应用,提供拖拽式 UI 和业务逻辑开发,集成度高,灵活性强。 | Lowcode Engine |
| Appsmith | Appsmith 公司 | 企业内部应用开发(如仪表盘、业务管理工具、报表生成),支持 API 集成 和数据库管理。 | 前端:React,后端:Java、Spring Boot、MongoDB | 强调与 API 和数据库集成,支持多数据源,拖拽快速开发数据密集型应用,组件丰富。 | Appsmith |
2. 手写低代码组件库
React组件库 核⼼组件实现思路总结:
- 组件化开发:每个核⼼组件均通过⾼度可配置的 props 实现⽤户⾃定义内容、交互和样式,确保组件具备灵活性和复⽤性。
- 动态数据绑定与联动:表单、图表等组件需要⽀持动态数据绑定和联动逻辑,确保在复杂业务场景中能够根据⽤户输⼊和业务逻辑进⾏动态渲 染。
- 拖拽与布局灵活性:拖拽容器、布局组件通过使⽤拖拽库和布局系统,⽀持⽤户⾃由组合⻚⾯结构,提升⻚⾯构建效率和灵活性。
- 响应式设计与权限控制:响应式设计组件确保⻚⾯在不同设备下有良好的显示效果,权限控制组件则保障了不同⻆⾊⽤户的访问限制。
| 核心组件名称 | 组件描述 | 实现思路(细化) |
|---|---|---|
| 1. 表格组件 | 提供基础表单元素(输入框、选择框、日期选择框等),支持动态生成和表单标题。 | 1. 集成表单元素(Input、Select、DatePicker 等),通过 props 动态配置属性(默认值、校验规则)。2. 使用 onChange 事件实时更新状态。3. 通过 FormContext 管理全局表单状态,支持联动校验和全局错误提示。 4. 支持动态添加字段和统一 API 提交/重置操作。 |
| 2. 布局组件 | 支持网格布局、弹性布局、响应式布局,快速搭建页面结构。 | 1. 封装 Grid、Row、Col 布局组件,通过 props 控制间距和对齐模式。2. 使用 Flexbox 或 CSS Grid 实现响应式布局。 3. 支持拖拽调整布局结构,记录组件位置及尺寸。 4. 提供边距、对齐方式等属性配置。 |
| 3. 数据展示组件 | 展示动态数据(表格、图表、列表),支持可视化数据模型。 | 1. 封装 Table、Chart、List 组件,通过 props 传递数据源和列配置。2. 支持异步 API 数据加载和动态刷新。 3. 集成 ECharts 实现图表渲染,支持柱状图、折线图等类型。 |
| 4. 按钮组件 | 提供多种样式按钮(提交、重置、操作按钮),支持异步操作。 | 1. 封装 Button 组件,通过 type 区分按钮类型(submit/reset/button)。2. 使用 onClick 事件处理异步逻辑。3. 支持自定义颜色、大小和禁用状态。 |
| 5. 拖拽容器组件 | 支持拖拽生成页面布局,动态管理组件交互。 | 1. 基于 react-dnd 实现拖拽功能。 2. 封装 DropContainer 组件,记录拖拽组件位置和交互逻辑。 3. 支持复杂组件(图表、表格)的拖拽布局。 |
| 6. 动态表单生成器 | 允许用户拖拽生成表单,支持动态校验和配置导出。 | 1. 基于表单组件扩展生成器,支持拖拽添加字段。 2. 通过 props 动态配置字段属性(label、required)。3. 自动生成表单配置 JSON,支持提交校验。 |
| 7. 模态框组件 | 提供弹窗对话框,支持自定义内容和操作。 | 1. 封装 Modal 组件,通过 visible 控制显示/隐藏。2. 提供标题、内容、底部插槽(slot)自定义。 3. 支持 onOk 和 onCancel 回调事件。 |
| 8. 图表组件 | 数据可视化组件(柱状图、折线图、饼图),支持动态数据源。 | 1. 集成 ECharts 或 D3.js 实现图表渲染。 2. 通过 props 传递数据源和图表类型配置。3. 支持图表交互(缩放、提示框)。 |
| 9. 页面导航组件 | 实现页面导航功能(顶部导航栏、侧边栏)。 | 1. 封装 Navbar、Sidebar 组件,支持自定义导航项。 2. 集成 React Router 实现路由跳转。 3. 结合权限控制限制导航访问。 |
| 10. 条件渲染组件 | 根据业务逻辑动态渲染内容,支持复杂场景。 | 1. 封装 ConditionalRender 组件,通过 props 传递条件表达式。2. 支持 v-if/switch 逻辑判断。3. 结合数据模型实现动态内容切换。 |
| 11. 富文本编辑器 | 提供富文本编辑功能(格式化、图片上传、数据链接)。 | 1. 集成 Quill 或 Slate.js 实现编辑器。 2. 支持文本格式化、图片上传和实时内容获取。 3. 通过 onChange 事件同步编辑器内容。 |
| 12. API 数据源组件 | 动态加载 API 数据,支持分页和筛选。 | 1. 封装 DataSource 组件,通过 props 配置 API 地址。2. 支持加载状态和错误处理。 3. 集成分页、搜索、筛选功能。 |
| 13. 响应式设计组件 | 适配多端(PC/移动端)的响应式布局。 | 1. 封装 Responsive 组件,基于 CSS Media Queries 动态调整布局。 2. 监听窗口大小变化,自动重新渲染。 3. 支持开发者自定义断点配置。 |
| 14. 权限控制组件 | 基于角色控制页面访问和操作权限。 | 1. 封装 AuthControl 组件,通过 props 传递权限列表。2. 结合 React Router 实现路由拦截。 3. 支持动态角色权限配置。 |
6. 鉴权
1. 鉴权所有方案
| 授权方案 | 业务场景 | 优点 | 缺点 | 具体解决措施 |
|---|---|---|---|---|
| 1. Token授权 (JWT) | 单页面应用(SPA)、移动端应用,如电商平台、社交媒体。 | 1. 用户完成登录后,服务端生成包含用户ID、角色权限的JWT并发送给前端。 2. 前端将JWT存储在HttpOnly Cookie或localStorage中,避免XSS攻击。 3. 每次请求时,在Authorization Header中携带Token发送至后端。 4. 服务端验证Token的有效性,并解析信息进行处理。 | 1. 无状态,适合分布式架构和跨域需求。 2. 加密签名,无需依赖服务器证书验证。 3. 适用于大团队,支持复杂CI/CD流程。 | 1. Token一旦泄露,存在被盗的风险。 2. 无服务端主动注销Token机制。 |
| 2. Session授权 | 传统Web应用,如企业管理系统、CRM系统。 | 1. 用户完成登录后,服务端生成唯一的Session ID并发送给前端。 2. 前端将Session ID存储在HttpOnly Cookie中,避免XSS攻击。 3. 服务端每次通过Session ID验证用户身份,检查权限返回数据。 | 1. 高安全性,所有身份信息存储在服务端,前端只存储Session ID。 2. 支持服务端主动注销Session。 | 1. 需要服务端持续存活,扩展性有限,无法支持分布式架构。 2. 复杂项目中依赖管理效率较低,难以处理跨项目依赖。 |
| 3.OAuth 2.0授权 | 社交平台、SaaS应用,如Github、Slack,支持第三方登录。 | 1. 用户点击第三方登录按钮,跳转重定向到授权服务。 2. 授权服务验证用户并返回Authorization Code。 3. 客户端使用Authorization Code向授权服务请求Access Token。 4. 客户端通过Access Token向资源服务器请求资源,验证通过Token提供资源。 | 1. 用户体验好,支持免注册登录。 2. 利用第三方平台的现成用户信息,降低用户注册门槛。 3. 依赖第三方服务的稳定性。 | 1. 实现复杂,涉及回调、授权码交换等。 2. 依赖第三方服务的稳定性。 |
| 4. 双因素认证 (2FA) | 金融系统、支付平台、旅行网站。 | 1. 用户登录后输入用户名和密码,服务端初步验证身份。 2. 发送一次性验证码(OTP)并通过短信或邮件发送给用户。 3. 用户输入OTP,服务端根据其发送至服务端进行验证,确保验证码正确且未过期。 4. 服务端验证通过后返回访问权限。 | 1. 高安全性,即使密码泄露,仍需OTP验证,进一步保障账户安全。 2. 提升用户体验。 | 1. 短信用于登录重复度高,可能影响用户体验。 2. 使用Google Authenticator实现OTP生成和验证。 3. 在后台设置有效时间,防止OTP重用。 4. 通过备份代码提供OTP失效后的替代方案。 |
| 5. RBAC (基于角色的访问控制) | 企业级应用、后台管理系统,如ERP系统、项目管理工具。 | 1. 用户登录后,服务端根据用户身份分配对应的权限(如管理员、普通用户)。 2. 根据每个角色定义不同的权限,服务端根据用户角色显示相应的功能块,隐藏无关权限。 3. 服务端每次请求数据时,后端验证用户角色是否具备相应权限,决定是否允许访问。 | 1. 细粒度权限控制,支持复杂的业务场景,灵活应对权限变动。 2. 角色的复杂性和权限设计增加了实现难度和维护成本。 | 1. 设计角色-权限映射表,定期审查权限分配,防止过度赋权。 2. 在后端增加权限校验逻辑,避免越权操作。 3. 提供动态角色管理,支持权限的实时更新。 |
| 6. SAML授权 | 企业级单点登录(SSO),如大型企业内部部署多个子系统的统一认证。 | 1. 用户通过SSO完成首次登录,SSO系统生成会话票据,并将其返回到服务端。 2. 服务端通过会话票据验证用户身份,并开放对应访问权限,用户无需在各个子系统中重复登录。 3. SSO系统集中管理用户身份,支持在多个子系统中进行无缝切换。 | 1. 高安全性,适合企业级多站点登录需求,避免重复登录。 2. SSO系统集中管理用户身份,支持在多个子系统中进行无缝切换。 | 1. 实现复杂,依赖XML协议和SAML协议的实现,适配各大企业内部需求。 2. 使用HTTPS传输SAML消息,防止中间人攻击。 3. 提供集中管理的SSO平台,支持多个系统的身份验证。 |
| 7. API Key授权 | 开放API平台,第三方开发集成,如Google Maps API、Weather API。 | 1. 开发者通过申请获得API Key。 2. 开发者通过HTTP请求或URL参数携带API Key请求数据。 3. 服务端验证API Key的有效性后给予访问权限,一般用于简单的公开API访问,不涉及敏感信息进行控制。 | 1. 实现简单,适用无需高度安全性的场景。 2. 方便第三方集成,支持开放API的访问。 | 1. 依赖性低,API Key容易被滥用。 2. 实现细粒度访问控制,只对全局API进行控制。 3. 对敏感操作单独增加认证(如IP白名单或单次认证)。 |
2. RBAC权限
菜单权限 按钮权限 接⼝权限(axios ⼆次封装 请求头带token)
1.Vue项⽬RBAC权限
| 序号 | 权限应用 | 详细步骤/要点 |
|---|---|---|
| 1 | 拆分静态路由与动态路由 | 1.1 静态路由:系统启动时即加载,无需权限控制,常用于登录页、404等公共页面。 1.2 动态路由:根据用户权限动态加载,需在获取用户权限后通过角色筛选路由。 1.3 配置文件:分离静态路由(直接加载)与动态路由(需通过 router.addRoutes 动态添加)。 |
| 2 | 动态添加路由 | 2.1 获取权限信息:登录后通过接口获取用户 roles 和 menus。 2.2 筛选路由:使用 Array.filter() 按 roles.menus 筛选有权限的路由。2.3 添加路由:通过 router.addRoutes([...filterRoutes, { path: '*', redirect: '/404' }]) 注入路由表。2.4 更新路由:使用 next(to.path) 强制刷新路由,解决 VueRouter 缓存问题。 |
| 3 | 权限拦截机制 | 3.1 路由守卫:通过 router.beforeEach() 拦截路由跳转。3.2 Token 校验:检查是否存在有效 token。 3.3 获取用户信息:无用户信息时调用 store.dispatch("user/getUserInfo")。3.4 权限匹配:通过 roles.menus 与路由 name 匹配权限。 |
| 4 | 动态显示左侧菜单 | 4.1 权限筛选:基于 roles.menus 过滤可见菜单项。4.2 菜单配置:菜单项需包含与权限匹配的 name 属性。4.3 渲染控制:仅渲染用户有权限的菜单项。 |
| 5 | 退出登录重置路由 | 5.1 重置路由:调用 resetRouter() 清除动态路由。5.2 清除用户信息:通过 context.commit('removeToken') 和 context.commit('setUserInfo', {}) 清空 Token 和用户数据。 |
| 6 | 按键权限控制 | 6.1 自定义指令:使用 v-permission 控制按钮显隐。6.2 权限判断:通过 roles.points 校验操作权限。6.3 应用示例: <el-button v-permission="add-employee"> 无权限时自动移除按钮。 |
| 7 | 自定义指令控制操作权限 | 7.1 指令实现:注册 v-permission 指令,在 inserted 钩子中校验权限。7.2 权限校验:对比 binding.value 与 roles.points,无权限则移除 DOM 元素。7.3 实际场景:如员工管理页面的“添加”按钮控制。 |
2.React项⽬RBAC权限
| 序号 | 权限应用 | 详细步骤/要点 |
|---|---|---|
| 1 | 拆分静态路由与动态路由 | 1.1 静态路由:系统启动时即加载,无需权限控制,通常用于公共页面(如登录页、404等)。 2.2 动态路由:根据用户权限动态加载,通常需要在获取用户权限信息后,根据用户角色进行筛选和添加。 3.3 配置文件:静态路由与动态路由分离,静态路由直接通过 React Router 的 <Route /> 组件加载,动态路由通过 useEffect 和 useState 动态控制。 |
| 2 | 根据用户权限动态添加路由 | 2.1 获取用户权限:在用户登录后,通过 API 获取用户权限信息,例如 roles.nenus。2.2 筛选动态路由:通过 roles.nenus 的权限数据,使用 Array.filter() 筛选出用户有权限访问的动态路由。3.3 使用状态管理路由:通过 useState 保存动态路由信息,在路由组件中使用 useEffect 监听权限变化,并使用 <Switch> 和 <Route> 渲染筛选出的动态路由。4.2 动态更新:确保在权限信息发生变化后,页面能够根据新权限信息重新渲染动态路由。 |
| 3 | 权限拦截机制 | 3.1 路由守卫:使用 React Router 的 useHistory() 和 useEffect() 进行权限拦截,在每次路由跳转时,判断用户是否拥有访问目标页面的权限。3.2 Token 校验:首先检查用户的 token,如果没有 token 则跳转到登录页面。 3.3 获取用户信息:如果用户没有 userInfo,则调用 API 获取用户信息,并存储到全局状态中(如通过 useContext 或 Redux)。3.4 权限校验:在 useEffect 中,判断 roles.menus 是否包含目标路由的 name,决定是否允许用户访问该页面。 |
| 4 | 根据权限显示左侧菜单 | 4.1 获取权限:通过用户权限数据 roles.nenus 获取用户有权限访问的菜单项。4.2 菜单设置:每个菜单项应包括对应的权限标识 name,用于与用户权限匹配。4.3 动态渲染菜单:使用 React 的条件渲染 {menus.includes(item.name) && <Menu.item ... />} 动态渲染右侧菜单,未授权的菜单项不显示。4.4 使用 useEffect 监听权限变化,确保菜单能根据用户权限的变化动态更新。 |
| 5 | 退出登录重置路由 | 5.1 重置路由:使用 useHistory().replace('/login') 在用户退出时重置路由,跳转至登录页面。5.2 清空用户信息:在退出登录的函数中,通过全局状态管理器(如 useContext 或 Redux)将用户 token 和 userInfo 清空,并重置权限信息为默认状态。5.3 重置路由表:确保用户退出登录后,重新登录时动态路由信息重新加载,防止权限信息残留。 |
| 6 | 按键权限控制 | 6.1 自定义 Hook 控制按钮权限:使用 usePermission 自定义 Hook 检查用户是否具备操作权限。6.2 权限判断: usePermission 内部根据用户的操作权限 roles.points 判断是否允许执行操作。如果没有权限则返回 false,前端可以使用条件渲染 {hasPermission && <Button ... />} 来控制按钮显示。6.3 示例:在组件中使用自定义 Hook <Button disabled={usePermission('add-employee')}>添加员工</Button> 来实现按钮权限控制。 |
| 7 | 自定义 Hook 控制操作权限 | 7.1 自定义 usePermission Hook:封装一个权限校验的 Hook,内部逻辑是从用户权限数据 roles.points 获取用户的操作权限。7.2 权限校验:在 usePermission 中通过 roles.points.includes(permission) 判断用户是否有权限执行特定操作。7.3 实际应用:在页面组件中通过 const hasPermission = usePermission('add-employee') 获取操作权限结果,并在按钮、操作项等处使用该结果来动态控制是否允许用户操作。7.4 动态更新:确保用户权限变化时,自定义 Hook 能及时更新权限信息。 |
3. 访问控制权限
| 鉴权方案 | 具体实施措施 | 可落地步骤 |
|---|---|---|
| RBAC(基于角色的访问控制) | 1. 设计角色-权限映射表,将角色与权限的关系存储在数据库中。 2. 实现数据传输管理,每次请求时通过用户的角色与其权限。 3. 使用 DINT 操作角色信息,减少频繁的权限查询。 4. 在前端隐藏无权限功能,防止用户访问未授权功能。 | 1. 数据库设计:创建角色表和权限表,建立多对多关系,确保每个角色可以绑定多个权限。 2. 后端获取权限校验:每次请求时,服务器根据用户的角色检查其权限。 3. 前端获取:根据后端返回的角色信息,前端控制功能的显示,隐藏无权限操作。 4. 定期审查角色权限分配。 |
| ABAC(基于属性的访问控制) | 1. 实现属性匹配引擎,根据用户属性和环境属性进行动态权限分配。 2. 使用程序机制提高权限计算效率。 3. 支持实时动态权限更新,基于环境变化调整权限。 | 1. 属性设计:定义用户属性和环境属性(如职位、部门、时间、位置),并在用户登录时获取这些信息。 2. 属性匹配引擎:编写后端服务,通过用户属性和环境属性动态匹配访问权限。 3. 缓存权限:将权限结果缓存,避免重复计算,提升系统性能。 4. 实时更新:通过 WebSocket 等方式实现权限的实时更新。 |
| PBAC(基于策略的访问控制) | 1. 设计策略管理系统,集中管理权限策略。 2. 使用策略优先级机制避免冲突。 3. 实现日志审计系统,跟踪权限策略执行情况,确保合规。 | 1. 策略管理系统:设计可配置的策略系统,管理员可以动态添加、修改、删除权限策略。 2. 策略优先级:建立规则,确保不同策略间不冲突,优先级高的策略优先执行。 3. 审计日志:记录每个策略的执行过程,确保有据可查,防止权限滥用。 |
| 基于标签的访问控制 | 1. 设计标签管理系统,为用户打上适当标签,并根据标签赋予权限。 2. 支持自动标签更新,根据用户行为调整权限。 3. 提供标签优先级系统,解决多标签冲突问题。 | 1. 标签系统设计:定义标签(如 VIP 用户、普通用户),在用户注册或更新时打标签。 2. 前端处理:根据用户的标签决定前端功能展示。 3. 后端验证:每次请求时,后端根据标签验证用户权限。 4. 自动更新:根据用户行为或时间自动调整标签,如购买服务后升级为 VIP。 |
| HAC(强制访问控制) | 1. 实现安全级别分类系统,确保用户和资源都得到正确分级。 2. 使用强制权限校验,系统根据安全级别强制执行访问控制,用户无法自行更改。 3. 定期安全审查,防止权限泄露或安全级别错误。 | 1. 资源与用户分级:对每个资源和用户进行安全级别分类(如机器、绝密)。 2. 强制执行:在后端根据用户和资源的安全级别强制执行权限控制,用户无权限改自己的权限。 3. 安全审查:定期检查安全级别和访问日志,确保权限不会被滥用。 |
| DAC(自主访问控制) | 1. 为用户提供清晰的权限设置界面,帮助其正确设置资源共享权限。 2. 设计权限模板,为用户提供推荐的权限设置,避免错误配置。 3. 实现权限更改日志记录,监控权限变化行为。 | 1. 权限设置界面:设计直观的界面,用户可以轻松为每个资源设置共享权限。 2. 权限模板:为常见的场景提供默认模板,用户可以快速选择合适的权限配置。 3. 日志记录:对每次权限变更操作进行日志记录,方便管理员审计和回溯,防止错误操作。 |
7. 大文件上传
| 功能模块 | 详细描述 |
|---|---|
| 1. 分片上传 | |
| 1.1 分片机制 | 使用 Bub.slice() 将文件分割为较小的片段。 |
| 1.2 动态调整分片大小 | 默认分片大小为 SMB,动态调整数据网络状况(3G 网络使用 1MB,WIFI 或 4G 使用 5-10MB),提升上传效率。通过 navigator.concetion.effectiveType 判断网络状况,navigator.deviceMemory 判断设备性能,并根据文件大小(如 xlsb 使用 10MB 分片)。 |
| 2. 切片唯一值 | |
| 2.1 文件hash生成 | 使用 spark-md5 生成文件唯一标识,利用 web-worker 异步计算 MD5 值,避免阻塞主线程。分块计算 hash 后合并,结合本地存储(localStorage 或 IndexedDB)保存 hash 值和上传进度。 |
| 2.2 本地存储 | 使用 LocalStorage 或 IndexedDB 记录上传进度和文件 hash 值,确保支持多个文件同时上传时,上传进度可恢复。 |
| 3. 断点操作 | |
| 3.1 上传进度管理 | 上传前通过 GET 请求 携带文件 hash 查询已上传字节数,删除记录上传进度。每次上传成功后更新本地存储中的进度值,上传时从中断位置继续上传。 |
| 3.2 文件上传逻辑 | 分片上传时,每次通过 POST 请求,携带文件的 hash 和起始字节位置,从服务器返回的字节数处继续上传。上传完成后清理本地存储中的 hash 和进度数据。 |
| 4. 并发上传 | |
| 4.1 任务队列 | 通过任务队列限制并发上传数,使用 Promise.allSettled 和 async/await 控制上传任务,动态调度任务,确保超过并发限制的任务处于等待状态。 |
| 4.2 动态调整 | 当一个任务完成后,启动下一个任务,直到所有任务完成。 |
| 5. 失败重试机制 | |
| 重试机制 | 捕获上传失败错误,设置最大重试次数(如 3 次),每次失败后等待一段时间再重试,保证上传成功率。 |
| 6. 秒传机制 | |
| 6.1 前端发送hash | 前端计算文件 hash 后,向服务器发送 hash 询问该文件是否存在。 |
| 6.2 服务器校验文件 | 如果文件已存在,服务器直接返回成功响应,无需重复上传;如果文件不存在,前端开始正常上传流程。 |
8. 双Token/无感刷新
| 序号 | 功能模块 | 详细步骤/要点 |
|---|---|---|
| 1 | 双 Token 机制 | 1.1 访问令牌(Access Token):用于访问受保护资源,通常有效期较短(如30分钟)。 1.2 刷新令牌(Refresh Token):用于获取新的访问令牌,有效期较长(如几个月)。 1.3 登录和Token发放: - 用户登录后,服务器生成并返回访问令牌和刷新令牌。 - 刷新令牌存储位置应考虑安全性(如使用 HttpOnly 和 Secure 标志的 Cookies)。1.4 Token过期处理: - 访问令牌过期时,前端使用刷新令牌请求新的访问令牌。 - 请求控制器检测访问令牌是否过期,并在必要时自动刷新。 |
| 2 | 无感刷新实现 | 2.1 自动Token刷新: - 设置定时器,每隔5分钟自动刷新Token。 - 获取刷新令牌,使用它请求新的访问令牌,并将新的访问令牌存储到 sessionStorage 中。2.2 失败处理: - 如果刷新Token失败,清除 sessionStorage 并重定向到登录页面,要求用户重新登录。 |
| 3 | 需要考虑的问题 | 3.1 并发请求处理: - 如果多个请求同时检测到Token过期,应防止多个请求同时刷新Token,使用全局变量 isRefreshing 标记刷新状态,所有等待的请求加入队列 failedRequestQueue,Token刷新完成后统一处理。3.2 Token被修改或伪造: - 使用通知密码法生成Token(如 RS256),定期轮换密钥,使用 HTTPS 传输Token,设置 HttpOnly 和 Secure 标志,并使用Token黑名单机制。3.3 刷新时机选择: - 通过用户行为监测系统(如点击、键盘输入、滚动等),在用户活跃时自动刷新Token,减少操作干扰。 |
| 4 | Token 刷新机制 | 4.1 全局变量与Promise缓存: - 使用 isRefreshing 标记是否正在刷新Token,防止重复刷新。- 使用 failedRequestQueue 存储等待Token刷新的请求队列,确保Token刷新后重新发送请求。4.2 响应控制器处理401错误: - 如果响应返回401错误,且请求未重试过,使用刷新令牌请求新的访问令牌,并重新发送原始请求。 - 如果Token正在刷新,所有新的请求加入 failedRequestQueue 队列,刷新完成后统一处理。4.3 刷新成功或失败处理: - 刷新成功时,更新访问令牌,重新发送所有排队请求。 - 刷新失败时,清除 sessionStorage 并重定向到登录页面。 |
| 5 | Token 安全性处理 | 5.1 生成安全Token:使用通知密码法(如 RS256)生成具有足够幅值的Token。 5.2 Token验证:签名验证Token有效性,设置合理的过期时间,并定期检查和更新密钥。 5.3 HTTPS与Cookie安全标志:通过 HTTPS 传输Token,并设置 HttpOnly、Secure 标志,防止JavaScript访问和网络传输被劫持。5.4 使用Token黑名单:当Token被撤销或失效时,将其加入黑名单,在每次验证Token时检查其是否在黑名单中。 |
9. 单点登录
| 类别 | 核心知识点 | 应用场景与最优方案 | 实现方式 |
|---|---|---|---|
| 项目背景 | 多系统整合与身份认证 | 在大型企业中,通常存在多个业务系统(如 ERP、CRM、文档管理系统等)。SSO 能够简化用户身份认证,实现一次登录访问多个系统的功能,提升工作效率。 | 1. 在中心认证服务器上搭建身份验证系统(例如 KeyCloak 或 Auth0)。 2. 各业务系统重定向到认证服务器进行登录验证。 3. 登录后认证服务器生成 JWT Token 并返回。 4. 客户端和服务器在请求时通过 Authorization 头携带 Token。 |
| 协议选择 | OAuth 2.0 + OpenID Connect | 通过 OAuth 2.0 和 OpenID Connect 实现身份认证与授权,适用于大多数 Web 应用场景。OAuth 2.0 负责授权,OpenID Connect 负责身份验证,实现用户在多个应用中的单点登录。 | 使用 OAuth 2.0 的授权模式: 1. 配置 OAuth 2.0 认证服务器(如 KeyCloak)。 2. 新增用户 /authorize 获取授权码。3. 后端通过 Token 端点获取 Access Token。 4. 用 JWT 存储用户的身份信息。 |
| 跨系统登录 | Access Token + Refresh Token | 不同系统(如 admin.company.com 和 docs.company.com)使用 JWT 进行身份认证。通过 Access Token 保持登录状态,Refresh Token 负责续期,避免频繁重新登录。 | 1. 登录成功后生成 Access Token 和 Refresh Token。 2. Token 存储在客户端的 LocalStorage 或 sessionStorage 中。 3. 使用 Refresh Token 自动续期(例如在用户发起请求时检测 Token 是否过期,若过期则发送刷新请求获取新 Token)。 |
| 跨域问题处理 | CORS 配置与 iframe + postMessage | 在跨域 SSO 过程中,可通过 CORS 允许不同域名共享 Cookie 或 Token。对于完全不同域名的系统,使用 iframe 结合 postMessage 实现跨域会话传递。 | 1. 在 SSO 服务器上设置 CORS 允许持续访问。 2. 在各子系统中嵌入相同 SSO 服务器的 iframe,用户登录后通过 postMessage 向父端口传递 Token。3. 使用 window.addEventListener('message', callback) 监听登录结果并获取 Token。 |
| 安全性考虑 | CSRF 防护、XSS 防护与 Token 签名 | 防御 CSRF 和 XSS 攻击。设置 SameSite Cookie 属性,防止 Token 被盗用,并通过 HTTPS 传输数据确保通信安全。 | 1. 在 SSO 服务器上设置 SameSite 属性防止 CSRF 攻击。 2. 使用 JWT 的 HMAC 或 RSA 签名验证 Token 完整性。 3. 启用 HTTPS,强制所有请求通过 HTTPS 进行。 4. 使用 helmet 配置 CSP,防止 XSS 攻击。 |
| 身份验证与会话管理 | 短期会话与长期登录 | 用户可选择短期登录或长期保持登录状态。短期会话设置较短的 Token 过期时间,长期登录使用 Refresh Token 实现无缝登录。 | 1. 用户登录时生成 Access Token(短期过期)和 Refresh Token(长期过期)。 2. 定期检查 Token 是否过期,若过期则自动使用 Refresh Token 续期。 3. 客户端提供“保持登录”选项,将 Refresh Token 保存在 LocalStorage。 |
| 多系统会话同步 | 中心化注销与会话同步 | 用户在某一系统中注销时,需确保其他关联系统的会话同步注销。通过中心化的 SSO 服务器 管理所有系统的会话状态,实现统一注销。 | 1. 在 SSO 服务器实现注销接口 /logout,通知所有子系统同步注销。2. 在系统嵌入 iframe,用户注销时调用每个系统的注销接口。 3. 后台通过 broadcast-channel 或 redis-pub-sub 实现集群系统的同步会话注销。 |
| 移动端 SSO 实现 | WebView + 深度链接 (Deep Link) | 在移动端应用中,通过 WebView 实现单点登录,并通过 Deep Link 在不同 App 之间共享登录信息。 | 1. 使用 WebView 嵌入 SSO 登录页面。 2. 登录成功后通过 Deep Link 传递 Token 给其他 App。 3. 实现 App 之间的身份验证信息共享(例如通过 React Native 的 Linking API 实现 Deep Link 跳转并传递 Token)。 |
| 性能优化 | Token 缓存、Redis 缓存与负载均衡 | 在高并发场景下,使用 Redis 缓存 Token 信息,减少数据库查询,并通过负载均衡器分发认证请求,提升系统的性能和稳定性。 | 1. 使用 Redis 缓存 Token 及用户会话数据。 2. 配置负载均衡器(如 Nginx)分发 SSO 请求,保证可靠性。 3. 结合 JWT 实现无状态验证,减少服务器端的会话管理开销。 |
| SSO 与微服务集成 | API Gateway + Token 传递 | 在微服务系统中,通过 API Gateway 作为身份验证入口,各微服务通过 JWT 共享用户身份信息,确保安全的跨服务访问。 | 1. 在 API Gateway 中设置身份验证入口,所有请求先通过 Gateway 验证身份。 2. 使用 JWT 存储用户信息,通过 Gateway 传递给各微服务。 3. 微服务中验证 JWT 的签名和有效性,确保合法访问。 |
| 第三方登录与集成 | OAuth 2.0 第三方登录集成 | 集成 Google、Facebook、微信等第三方登录,通过 OAuth 2.0 授权码模式,用户登录后获取第三方 Token 并存储在 SSO 系统 中。 | 1. 配置第三方登录应用(如 Google、Facebook、微信)。 2. 前端跳转到第三方认证平台,用户授权后返回 Token。 3. 将第三方 Token 存储在中心认证服务器中,用户后续访问系统时跳转至 Token。 |
| 多因子认证 | MFA(多因子认证)增强安全性 | 结合 MFA,用户登录后需进行额外身份验证(如短信验证码或手机认证)。 | 1. 配置 MFA 机制(如短信验证码或 Google Authenticator)。 2. 用户登录后通过中心认证服务器发送验证码或生成动态密码。 3. 验证通过后用户方可访问系统。 4. 结合 Auth0 或 KeyCloak 实现多因子认证服务。 |
| SSO 部署与扩展 | 云服务集成与高可用部署 | SSO 系统 可通过云服务(如 Auth0、AWS Cognito)部署,结合 Docker 和 Kubernetes 实现容器化部署,确保高可用性和可扩展性。 | 1. 通过 Auth0、AWS Cognito 配置中心认证服务,利用云服务的高可用特性。 2. 使用 Docker 容器化部署 SSO 服务器,结合 k8s 实现自动管理。 3. 配置负载均衡器分发流量,确保高并发性能。 |
| 用户体验优化 | 自动登录、无缝切换与登录态保持 | 通过 Token 的长期有效性 和自动登录,用户在不同系统间无缝切换。使用 JavaScript 自动检测用户登录状态并跳转到 SSO 页面,提升用户体验。 | 1. 前端使用 localStorage 存储 Token,检测是否存在有效 Token。 2. 若 Token 存在且未过期,自动跳转至应用主页面。 3. 前端页面中使用 JavaScript 自动刷新登录状态并跳转,提供无缝体验。 |
10. 虚拟长列表
| 序号 | 项目 | 具体内容 |
|---|---|---|
| 1 | 实际应用场景 | |
| 1.1 | 电商后台管理系统 | 1. 场景描述:电商后台中,管理员需要处理大量商品和订单数据,通过虚拟长列表实现高效渲染,避免因数据量过大导致页面卡顿。 2. 具体落地方案: 2.1 商品或订单数据存储在服务器端,前端通过分页或增量加载方式获取。 2.2 使用虚拟长列表渲染,结合筛选、排序功能。 2.3 优化滚动体验,确保在大数据量下依然流畅。 |
| 1.2 | 大数据展示系统 | 1. 场景描述:在大数据展示中,设备或日志信息数量巨大,虚拟长列表能高效展示这些数据,避免延迟和卡顿。 2. 具体落地方案: 2.1 将日志或设备信息分批次加载,避免一次性加载过多。 2.2 使用虚拟长列表显示,并支持筛选和分类功能。 2.3 结合数据预加载机制提升用户体验。 |
| 2 | 实现细节 | |
| 2.1 | 定高列表的实现 | 1. 初始化:设定每个列表项的固定高度 itemHeight,获取视口高度 viewHeight。2. 计算可见元素:根据滚动位置 scrollTop 计算可视范围内元素索引:startIndex = Math.floor(scrollTop / itemHeight),endIndex = Math.floor((scrollTop + viewHeight) / itemHeight)。3. 仅渲染可见元素:只渲染从 startIndex 到 endIndex 范围内的数据。 |
| 2.2 | 不定高列表的实现 | 1. 记录高度:初次渲染时记录每个元素的高度,动态调整可视区域高度。 2. 滚动条同步调整:动态计算整个列表总高度,并根据已渲染元素的高度调整滚动条位置。 |
| 3 | 性能优化 | 1. 节流与防抖:使用 lodash 中的 throttle 或 debounce、requestAnimationFrame 优化滚动事件,减少频繁渲染导致的卡顿。2. 缓冲区机制:向上或向下多渲染几个元素作为缓冲区,避免滚动时出现闪屏或白屏,缓冲区大小根据实际情况调整。 |
3. 项目性能优化
1. 项目性能衡量指标
浏览器在⼀帧中都做了什么?
浏览器中的画⾯都是⼀帧⼀帧渲染出来的,通常来说渲染的帧率与设备的刷新率保持⼀致。⼀般情况下,设备的屏幕刷新率为1秒钟60次,⼀次16.7ms(毫秒) 当每⼀帧绘制毫秒低于16.7ms时,⻚⾯渲染时流畅的;当⼤于16.7毫秒时,会出现⼀定程度的卡顿现象。
每⼀帧的渲染流程主要包括:事件处理 → JavaScript 执⾏ → 样式计算 → 布局 → 分层 → 绘制 → 合成 → 显示。所有这些操作必须在
16.7 毫秒内完成,才能保证⻚⾯流畅。
1. 后端性能监控指标
TP50、TP90、 TP99 、TP999 特别⽤于 衡量请求的响应时间,这⾥需要后端做优化
| 指标 | 应用场景 | 示例 | 推荐值 |
|---|---|---|---|
| TP50 | 判断系统的典型性能,但不够全面,不能反映长尾请求情况 | 50%的请求响应时间 ≤ 100ms | ≤ 100ms |
| TP90 | 评估系统在较高负载下的性能,识别较慢请求 | 90%的请求响应时间 ≤ 200ms | ≤ 200ms |
| TP99 | 监控系统性能的极端情况,确保极少数请求不会过慢 | 99%的请求响应时间 ≤ 500ms | ≤ 500ms |
| TP999 | 评估系统最差情况下的表现,适用于高可用性要求高的系统 | 99.9%的请求响应时间 ≤ 1000ms | ≤ 1000ms |
2. 前端性能监控指标
| 指标 | 描述 | 优化方向 | 具体做法 |
|---|---|---|---|
| FCP | 首个内容绘制时间,反映页面加载速度 | 减少阻塞资源,优化CSS和JS加载 | 1. 关键资源优先加载:通过 <link rel="preload"> 和 <link rel="prefetch"> 确保首屏关键资源优先加载。2. CSS优化:将关键CSS内嵌到HTML中,减少外部CSS文件的请求数,非关键CSS可延迟加载。 3. JS优化:通过 async 或 defer 加载JS,减少包体积,使用 Tree Shaking 方法压缩代码。4. 资源压缩与缓存:通过 Gzip、Brotli 压缩静态资源,结合 Cache-Control 实现缓存。 |
| LCP | 最大内容绘制时间,衡量页面主体内容加载速度 | 优化图片、字体加载,提升核心内容展示速度 | 1. 图片优化:使用 CDN 分发资源,结合 WebP、AVIF 格式并压缩图片(使用 TinyPNG 等工具);通过 srcset 属性提供多分辨率适配。2. 懒加载策略:使用 loading="lazy" 延迟加载非首屏图片,结合 Intersection Observer API 预加载视口内容。3. 字体优化:使用字体子集(如 Font Squirrel)优化体积,避免加载冗余字符;通过 font-display: swap 防止布局偏移。4. 服务器响应优化:减少页面重定向,优化 TTFB(首字节时间),提升核心内容的渲染速度。 |
| FID | 首次输入延迟,衡量页面交互响应速度 | 优化JS执行时间,减少主线程阻塞 | 1. 代码分割与懒加载:通过 Webpack 或 Vite 的 splitChunks 拆分代码,利用动态导入(import())按需加载非关键代码。2. 减少主线程阻塞:将复杂计算任务放入 Web Worker,使用 requestIdleCallback 调度低优先级任务。3. 长任务拆分:用 setTimeout 或 requestAnimationFrame 拆分长任务,避免主线程长时间占用。4. 第三方脚本优化:通过 async 或 defer 加载第三方脚本,减少体积并限制其影响。 |
| CLS | 累积布局偏移,衡量视觉稳定性 | 设置固定尺寸,避免布局变化 | 1. 固定元素尺寸:为图片、视频等元素明确指定 width 和 height 属性,防止加载后布局偏移。2. 广告位占位管理:为动态广告位预设固定容器高度(如 min-height),避免内容加载时页面抖动。3. 字体加载优化:使用 font-display: swap 确保字体加载期间以系统字体显示文本。4. 动态内容占位:为表格、按钮等动态内容提前预留占位空间,避免加载时页面抖动。 5. 动画优化:优先使用 transform 实现动画,减少布局重排。 |
| TTFB | 首字节时间,反映服务器响应速度 | 优化服务器响应,使用CDN和缓存 | 1. 服务器优化:减少数据库查询,使用缓存(如 Redis)加速重复请求处理;优化反向代理(如 Nginx)。 2. 启用HTTP/2或HTTP/3:通过多路复用技术减少连接建立时间,提升响应速度。 3. CDN加速:使用CDN分发静态资源,减少传输延迟。 4. 减少请求数量:合并CSS/JS文件,使用内联关键CSS,减少HTTP请求次数。 5. DNS预加载:通过 dns-prefetch 和 preconnect 提前解析域名并建立连接。 |
2. 优化工具使用
1. Lighthouse
4种使⽤⽅式
| 使用方式 | 步骤 | 备注 |
|---|---|---|
| 1. Chrome DevTools | 1. 打开 Chrome 浏览器并导航至要测试的网页 2. 按下 F12 或右键点击页面,选择“检查”打开开发者工具 3. 切换到 “Lighthouse” 标签 4. 选择要测试的项目(性能、可访问性、SEO 等) 5. 点击“生成报告”按钮,等待 Lighthouse 生成结果 | 适用于快速分析单个网页性能 |
| 2. 命令行 (CLI) | 1. 安装 Node.js 和 npm 2. 运行 npm install -g lighthouse 安装 Lighthouse3. 使用命令 lighthouse <URL> 运行测试4. 查看生成的 HTML 或 JSON 格式报告 | 适用于自动化测试和集成 CI/CD 工具 |
| 3. PageSpeed Insights | 1. 打开 PageSpeed Insights 2. 输入要测试的 URL 3. 点击“分析”按钮 4. 查看 Lighthouse 生成的报告 | 适用于在线测试,生成实际用户环境下的性能数据 |
| 4. npm 包集成 | 1. 安装 Lighthouse npm 包 2. 在项目中通过脚本集成 Lighthouse 进行性能测试 3. 运行集成的测试脚本,查看结果 | 适用于项目中集成性能分析工具 |
2. Performance
| 使用方式 | 步骤 | 备注 |
|---|---|---|
| 1. Chrome DevTools | 1. 打开 Chrome 浏览器并导航至要测试的网页 2. 按下 F12 或右键点击页面,选择“检查”打开开发者工具 3. 切换到 Performance 标签 4. 点击“录制”按钮开始捕获性能数据 5. 完成测试操作后,点击“停止”按钮,查看性能报告 | 实时查看页面的性能瓶颈(如 CPU、内存使用率、帧率等) |
| 2. 命令行 (CLI) | 1. 安装 Node.js 和 npm 2. 通过 npm 安装 Chrome Headless 浏览器 3. 使用 puppeteer 或类似工具运行页面性能测试 4. 导出性能数据,查看帧率、加载时间等指标 | 适用于自动化性能测试,可与 CI/CD 集成 |
| 3. 远程设备测试 | 1. 将移动设备连接到电脑 2. 在 Chrome DevTools 中,点击设备图标,选择连接的设备 3. 在移动设备上操作网页,同时在 DevTools 的 Performance 标签中查看性能数据 | 适用于测试移动设备的性能表现 |
3. 网络层面优化
| 序号 | 优化方案 | 业务场景 | 具体实施措施 | 可落地步骤 |
|---|---|---|---|---|
| 1 | CDN 加速 | 内容管理系统、Web平台等需要快速加载静态资源的大型应用 | 1. 将静态资源托管至 CDN 节点,用户请求时就近访问,减少延迟。 2. 设置缓存类(Cache-Control),确保资源长期保存,减少并发浪费。 3. 实现数据加载,仅在需要时加载特定资源。 | 1. 选择优质的 CDN 服务器端,如 Cloudflare、AMS CloudFront。 2. 在打包过程中,配置静态资源路径指向 CDN。 3. 设置缓存策略,确保资源版本更新时缓存失效。 |
| 2 | HTTP/2 和 HTTP/3 | 高并发场景、实时应用,如社交平台、在线游戏。 | 1. 使用 HTTP/2 或 HTTP/3 协议,开启多路复用,减少请求的阻塞问题。 2. 启用服务器推送,提前发送关键资源。 3. 支持 TLS1.3 提高加密效率,减少握手时间。 | 1. 在服务器配置中启用 HTTP/2 或 HTTP/3,如在 Nginx 中启用 HTTP/2 支持。 2. 确保证书支持 TLS1.3,提升加密效率。 3. 对重要资源进行服务器推送(如 CSS 和 JS 文件)。 |
| 3 | Lazy Load | 图片密集型页面,如图片社交平台、新闻门户。 | 1. 对图片和视频实现微加载,确保只有在用户网站的页面中才加载资源。 2. 对长页面中的相关提示来进行微加载,减少页面初次加载时间。 | 1. 使用 HTML5 的 loading="Lazy" 属性对图片和 iframe 进行微加载。2. 对于视频和其他资源,使用 IntersectionObserver API 实现微加载。3. 优化活动性能,避免过多监听活动事件。 |
| 4 | 资源预加载 | 单页面应用(SPA)、大型电商平台,用户需要快速导航到其他页面。 | 1. 使用 <Link rel="preload"> 预加载关键 CSS、JS 和字体等资源,提升自屏渲染速度。2. 使用 <Link rel="prefetch"> 提前获取用户可能访问的后续页面资源。 | 1. 确定页面的关键资源,并在 <head> 标签中使用 <Link rel="preload"> 进行预加载。2. 对用户行为进行分析,使用 <Link rel="prefetch"> 提前加载用户可能会访问的后续页面资源。3. 配置打包工具生成预加载文件。 |
| 5 | DNS 预解析与 TCP 连接复用 | 多域名站点、跨域资源加载,如广告平台、第三方 API 集成。 | 1. 使用 <Link rel="dns-prefetch"> 提前解析 DNS,减少域名解析时间。2. 启用外文连接,保持 TCP 连接活跃,减少重复连接的扩展。 3. 启用连接复用,避免重复的 DNS 解析和连接延误。 | 1. 在 <head> 标签中添加 <Link rel="dns-prefetch">,提前解析第三方链路的 DNS。2. 配置 Nginx 或其他 Web 服务器,启用 Keep-ALive,保持 TCP 连接活跃。 3. 对常用的第三方域名启用连接复用,减少重复连接和解析时间。 |
| 6 | Gzip/Brotli 压缩 | 内容丰富的新闻站点、电商平台等页面内容较多的站点。 | 1. 启用 Gzip 或 Brotli 压缩,将 HTML、CSS、JS 等文本文件压缩传输,减少带宽占用。 2. 优先选择 Brotli,压缩效果优于 Gzip。 | 1. 在 Nginx、Apache 或其他服务器中启用 Brotli 或 Gzip 压缩,优先选择 Brotli。 2. 对常用的文件类型(如 HTML、CSS、JS)进行压缩传输,设置文件大小的最小阈值,确保小文件不进行压缩,避免压缩时间超过传输节省的时间。 |
| 7 | 缓存机制优化 | 需要频繁更新的页面,如新闻门户、社交平台。 | 1. 对静态资源设置长缓存策略,确保用户重复访问时直接从浏览器缓存加载资源。 2. 对频繁变化的资源(如 HTML 文件)使用短缓存或 Flag 机制 进行版本控制。 | 1. 在 Nginx 或 Apache 中配置缓存策略,对静态资源(如 CSS、JS 目录)设置长缓存,版本变更时修改文件名确保缓存失效。 2. 使用 Flag 机制 对 HTML 文件 进行版本控制,确保用户始终获取最新版本的页面。 |
| 8 | 使用 WebP 格式图片 | 图片丰富的页面,如电商平台、图像社交平台。 | 1. 使用 WebP 格式替代传统的 PNG 或 JPEG 图片,减少图片文件大小。 2. 对不支持 WebP 的浏览器提供 PNG 或 JPEG 作为备用格式。 | 1. 使用图片处理工具(如 Photoshop、ImageMagick)或第三方服务(如 Cloudinary)将图片转换为 WebP 格式。 2. 在 HTML 中使用 <picture> 标签提供多种图片格式,确保兼容性。3. 配置打包工具或 CDN 自动转换图片格式以适应浏览器的支持情况。 |
| 9 | 分片上传 | 大文件上传场景,如视频平台、在线教育平台。 | 1. 实现分片上传功能,将大文件作为少片段的上传,避免单片上传失败导致重载。 2. 后端支持分片合并,并使用文件给备份设备完整性。 | 1. 在前端使用 File API 或第三方库(如 fine-uploader)将文件拆分为小块,上传时无法发送。 2. 在后端使用文件给备份设备备份的分片的完整性,并在所有分片上传完成后合并文件。 3. 实现新版缓存功能,确保上传中断时能够从上次中断的地方继续上传。 |
4. 代码层面优化
| 序号 | 优化方案 | 业务场景 | 具体实施措施 | 可落地步骤 |
|---|---|---|---|---|
| 1 | 代码拆分 (Code Splitting) | 单页面应用 (SPA),如大型电商平台、在线学习平台。 | 1. 使用 Webpack、Vite 等打包工具将不同页面或模块的代码分离成独立包,用户访问时才加载对应的代码包。 2. 对第三方库进行按需加载,减少初次加载的体积。 | 1. 在 Webpack 配置中使用 dynamic import 实现代码拆分。2. 配置 optimization.splitChunks 进行共享代码的拆分。3. 使用 Vite 的按需加载功能为不同路由或模块生成单独的 JS 文件。 |
| 2 | Tree Shaking | 单页面应用 (SPA),如内容管理系统、后台管理系统。 | 1. 使用 Webpack、Rollup 等打包工具去除未使用的代码 (Tree Shaking)。 2. 确保第三方库支持 ES Modules 格式,便于打包工具移除无用代码。 | 1. 在 Webpack 中配置 mode: 'production',启用 Tree Shaking 功能。2. 使用支持 ES Modules 的第三方库,避免使用 CommonJS 格式。 3. 在 Rollup 中配置 treeshake: true,确保移除未用的模块。 |
| 3 | 减少 DOM 操作 | 数据密集型页面,如表格系统、数据大屏展示系统。 | 1. 合并多次 DOM 操作,避免频繁更新 DOM。 2. 使用虚拟 DOM 或 document fragment 减少真实 DOM操作的次数,提高渲染性能。 | 1. 使用 React、Vue 等框架的虚拟 DOM 特性,减少真实 DOM 的操作。 2. 对需要批量插入的 DOM 元素,使用 document fragment 合并操作后一次性插入到页面中。3. 避免在循环中频繁操作 DOM,改为先构建节点再统一插入。 |
| 4 | 减少重排和重绘 | 需要频繁交互的页面,如实时数据监控系统、在线编辑器。 | 1. 避免频繁修改布局相关的 CSS 属性(如 width、height 等),减少重排。2. 批量修改样式,避免每次修改都发生变化。 3. 使用 transform 和 opacity 实现动画效果,避免影响布局。 | 1. 对涉及布局的属性修改,使用 requestAnimationFrame 进行批处理。2. 在执行批量 DOM 操作时,使用 classList 批量添加/移除类,避免频繁修改单个样式。3. 使用 CSS 的 transform 和 opacity 进行过滤动画,避免触发重排和重绘。 |
| 5 | 长列表虚拟化 | 需要显示大量数据的页面,如自后台管理系统、社交媒体评论列表。 | 1. 使用虚拟滚动技术,仅渲染当前可见的列表项,减少内存占用和渲染压力。 2. 使用 IntersectionObserver 实现增加载,确保列表滚动时逐步加载数据。 | 1. 在长列表场景下使用 react-virtualized、vue-virtual-scroll-list 等库实现虚拟滚动。2. 通过 IntersectionObserver 监听滚动位置,动态加载当前可见区域的内容。3. 对超出视口的元素进行增加载,减少初次渲染的内容量。 |
| 6 | 图片懒加载 | 图片密集型页面,如图片社交平台、新闻门户。 | 1. 使用 loading="lazy" 或 IntersectionObserver API 实现图片懒加载,减少页面初始渲染的负担。 | 1. 对于图片的 iframe 使用原生的 loading="lazy" 属性,减少页面首次加载的资源量。2. 对不支持 loading="lazy" 的浏览器,使用 IntersectionObserver 来监听图片的进入视口,加载图片。3. 使用 Vue、React 等框架中的懒加载库,进一步简化操作。 |
| 7 | 使用 Web Workers | 需要复杂计算的项目,如数据分析平台、在线图像处理平台。 | 1. 将复杂的计算任务或数据处理任务交给 Web Workers 处理,避免随意生成新的 UI 渲染。 2. 使用 Web Workers 进行并行处理,加快数据处理速度。 | 1. 创建独立的 Web Worker 文件,将耗时的计算逻辑放入其中。 2. 使用 postMessage 和 onmessage 实现主线程与 Worker 线程的同步。3. 对复杂计算或多任务并行处理,使用多个 Web Workers 协同工作,提升整体性能。 |
| 8 | 缓存 API 请求 | 数据密集型应用,如金融系统、社交平台。 | 1. 对频繁调用的 API 使用 IndexedDB 或 Service Workers 缓存,减少不必要的网络请求。 2. 对相同数据多次请求的 API 使用请求合并策略,减少重复请求。 | 1. 对常用的 API 数据进行缓存,使用 Service Workers 或 localStorage 进行本地存储。2. 在数据变化不频繁的场景下,使用 Flag 或 Cache-Control 机制缓存 API 响应。3. 对于短时间内多次请求相同数据的 API,使用防抖或节流策略。 |
| 9 | Debounce 和 Throttle | 高频事件产生的页面,如搜索建议、滚动事件监听。 | 1. 对高频触发的事件(如搜索输入、滚动事件)使用 Debounce 或 Throttle 技术,减少事件处理的频率,提升性能。 | 1. 使用 Lodash 或自定义 debounce 和 throttle 函数,对输入事件、滚动事件等高频事件进行防抖处理。2. 在 React、Vue 等框架中使用状态管理库,将防抖或节流的语句与状态管理层分离。 3. 对频繁触发的动画、鼠标移动等事件进行节流,减少无意义的计算。 |
1. 动态预加载
1. 动态预加载实现
动态预加载,游戏中的不同场景分为主要场景和次要场景。主要场景资源通过动态预加载,不是script标签写死的sel=preload, ⽽次要场景的资源采⽤懒加载策略,在需要时动态加载。
| 场景类型 | 加载策略 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|---|
| 主要场景 | 动态预加载 | 1. 基于用户行为和游戏逻辑,利用 JavaScript 动态创建(注意是动态创建)link 标签,设置 rel="preload",提前加载必要资源。 2. 通过智能预测即将进入的主要场景,调用后台服务静默下载场景所需的资源,确保资源在场景切换时可用。 3. 可使用带宽管理工具,根据用户的网络情况调整加载资源的优先级。 | 1. 提升用户体验:通过提前加载资源,减少场景切换时的延迟,确保场景顺畅切换。 2. 更高资源利用率:按需加载,避免加载不必要的资源。 | 1. 实现复杂:动态预加载需准确预测用户行为,避免加载过多不必要的资源。 2. 带宽负担:可能因预加载占用带宽,影响实时网络请求性能。 |
| 次要场景 | 懒加载策略 | 1. 使用 IntersectionObserver 检测用户接近次要场景时触发懒加载,或在用户需要时使用动态导入 import() 加载模块。 2. 场景内资源如图片、视频等,可以通过 lazy 属性或 按需加载工具 实现懒加载。 | 1. 节省带宽与内存:只在需要时加载,避免初始页面加载过多无用资源,减少内存和流量消耗。 2. 提高首屏速度。 | 1. 首次加载延迟:首次进入次要场景时,可能因资源未提前加载导致短暂等待。 2. 用户体验问题:次要场景交互需迅速响应。 |
1. 动态预加载实现
行为预测与加载触发:通过检测用户在游戏中的行为(如导航操作、任务完成等),智能预测用户即将进入的主要场景。提前触发 link 标签预加载资源:
function preloadResource(url, type) { const link = document.createElement('link'); link.rel = 'preload'; link.as = type; // 资源类型,如 'script', 'image', 'font' 等 link.href = url; document.head.appendChild(link); } // 调用预加载函数,提前加载主要场景资源 preloadResource('path/to/scene-script.js', 'script'); preloadResource('path/to/scene-image.jpg', 'image');带宽优化:结合 Network Information API,动态调整预加载的策略。例如,在用户网络质量较好时,快速预加载资源,而在网络较差时降低加载优先级,避免影响游戏实时交互。
if (navigator.connection.downlink > 2) { preloadResource('high-res-image.jpg', 'image'); } else { preloadResource('low-res-image.jpg', 'image'); }
这样可以确保表格的内容和样式与原文档保持一致,特别是数字编号和 Markdown 格式的强调文本。
次要场景的懒加载策略
IntersectionObserver 实现懒加载:在⽤户即将进⼊次要场景时,使⽤ IntersectionObserver 检测元素的可⻅性并触发资源加载。
例如,当场景内的关键元素出现在视⼝范围内时加载相关资源。
// 创建一个 IntersectionObserver 实例来监听元素是否进入视口
const observer = new IntersectionObserver((entries, observer) => {
// 遍历所有被观察的元素
entries.forEach(entry => {
// 检查元素是否已经进入视口
if (entry.isIntersecting) {
// 如果元素进入视口,动态加载次要场景的模块
import('./secondary-scene.js').then(module => {
// 模块加载完成后,初始化次要场景
module.initScene();
});
// 加载完成后,停止观察当前元素,避免重复加载
observer.unobserve(entry.target);
}
});
});
// 选择需要懒加载的元素
const target = document.querySelector('.secondary-scene-trigger');
// 将选定的元素加入观察列表中,等待其进入视口
observer.observe(target);
- 懒加载资源的延迟优化:次要场景的静态资源(如图⽚、⾳频)可以使⽤原⽣的 loading="lazy" 属性,确保只有在资源可⻅时才会被加
载。此外,还可以设置资源的低优先级,以确保主要场景的资源获取不被延迟。
5. webpack打包优化
| 优化维度 | 核心优化建议 | 备注 |
|---|---|---|
| 代码分割 | 1. 使用 SplitChunksPlugin 将依赖分割成多个 bundle,优化加载速度 2. 通过 动态导入(Dynamic Import)按需加载模块 | 减少首屏加载时间,优化资源利用 |
| Tree Shaking | 1. 启用 Tree Shaking 移除未使用的代码 2. 配置 sideEffects: false 优化依赖库打包 | 减少打包体积,移除无用代码 |
| 缓存 | 1. 启用 缓存,使用 Cache-Control 缓存策略 2. 为静态资源添加 hash 或 chunkhash | 提升重复访问时的加载速度 |
| 图片和资源优化 | 1. 使用 image-webpack-loader 等工具压缩图片 2. 使用 url-loader 或 file-loader 处理静态资源 | 优化资源加载速度,减少资源占用 |
| 代码压缩 | 1. 启用 TerserPlugin 压缩 JavaScript 文件 2. 使用 css-minimizer-webpack-plugin 压缩 CSS | 减少打包体积,提升加载性能 |
| 多线程打包 | 1. 使用 thread-loader 启用多线程打包 2. 使用 parallel-webpack 提高打包速度 | 提升打包性能,减少打包时间 |
| 预编译依赖 | 1. 使用 DllPlugin 和 DllReferencePlugin 预编译依赖库 2. 缓存未变化的第三方库 | 减少构建时间,提高打包效率 |
| 按需加载 | 1. 配置 lazy loading 按需加载非关键资源 2. 使用 import() 动态导入模块 | 优化资源利用,减少不必要的加载 |
| 使用生产模式 | 1. 使用 mode: 'production' 启用生产环境配置 2. 启用 webpack.DefinePlugin 配置环境变量 | 启用默认优化选项,优化打包效果 |
| CSS 和 JS 分离 | 1. 使用 MiniCssExtractPlugin 分离 CSS 文件 2. 避免将所有 CSS 打包到一个文件中,使用按需加载 | 减少首屏加载时间,提升加载性能 |
| 模块联邦 (Module Federation) | 1. 使用 Module Federation 共享跨应用模块 2. 在多个项目之间共享依赖库 | 提升模块复用,减少重复打包依赖 |
| DevTool 优化 | 1. 在开发环境中使用 cheap-module-source-map 提升构建速度 2. 在生产环境中禁用 source-map 减少体积 | 优化开发体验,减少生产环境体积 |
6. 浏览器架构
| 序号 | 组件 | 实际应用场景 | 优化措施 | 高逼格优化方案 |
|---|---|---|---|---|
| 1 | 用户界面 | 确保 UI 流畅交互,特别是在用户输入 URL、操作浏览器按钮等时不影响页面渲染。 | 1. 避免过度动画效果。 2. 使用轻量级 UI 框架,如 Ant Design、Element-UI,但要注意减少不必要的复杂性。 | 1. 使用 requestIdleCallback 在空闲时处理低优先级任务,如用户行为分析或日志统计,不阻塞主线程。 |
| 2 | 浏览器引擎 | 处理用户请求、加载页面,并协调渲染和网络模块,确保浏览器输入和输出的响应速度。 | 1. 避免复杂页面重定向。 2. 减少跨站资源加载,提升页面首屏渲染速度。 | 1. 使用预加载技术(Preload、Prefetch),在用户访问页面前提前加载资源。 2. 利用 Service Workers 实现离线缓存,提升页面加载速度。 |
| 3 | 渲染引擎 | 页面渲染的核心,确保 DOM 和 CSSOM 树的快速生成,并实现流畅的页面布局和绘制。 | 1. 使用 documentFragment 进行批量 DOM 操作。 2. 避免内联样式的频繁更改,减少重排和重绘次数。 | 1. 利用虚拟 DOM 和增量更新技术(如 React Fiber、Vue 的 Diff 算法)提升渲染性能。 2. 通过 will-change 提前声明变化,减少重绘和重排。 |
| 4 | JavaScript 引擎 | JavaScript 逻辑处理的核心,特别是涉及 DOM 操作和异步任务时,需要避免主线程阻塞。 | 1. 使用 async/await 处理异步任务,避免阻塞渲染线程。 2. 减少不必要的全局变量和事件监听器的使用。 | 1. 使用 Web Workers 将复杂计算和非 UI 相关的任务放在后台线程中执行,避免阻塞主线程。 2. 引入树摇优化(Tree Shaking),减少不必要的代码体积。 |
| 5 | 网络模块 | 处理页面资源的加载与请求响应,确保页面的网络请求快速并高效传输数据。 | 1. 使用 HTTP/2 加快多资源并发加载。 2. 减少 HTTP 请求次数,合并资源文件。 | 1. 实施 CDN 加速,通过内容分发网络提升全球用户访问速度。 2. 使用 Service Worker 进行离线缓存和智能预加载,提升页面的可用性和性能。 |
| 6 | UI 渲染线程 | 负责将渲染树转换为屏幕上的图像,处理页面的布局和绘制任务。 | 1. 使用 requestAnimationFrame 优化动画流畅度,避免阻塞渲染线程。 2. 减少 DOM 树的深度和复杂性。 | 1. 利用 GPU 加速提升图形渲染性能,如 CSS 动画、3D 渲染等。 2. 使用 IntersectionObserver 实现懒加载,避免不必要的页面渲染和加载。 |
| 7 | 图层合成器 | 负责处理页面的滚动、动画等效果,将页面分成不同图层合成。 | 1. 将动画元素、复杂的滚动元素提升为单独的渲染层,减少重新布局的代价。 2. 避免频繁触发 Layout 和 Paint 操作。 | 1. 使用 will-change 属性提前通知浏览器哪些元素会发生变化,避免频繁的合成和重绘。 2. 利用 GPU 合成层渲染大规模动画和复杂效果,提升渲染效率。 |
| 8 | 浏览器进程 | 负责管理选项卡、窗口的生命周期,提升浏览器的整体稳定性与安全性。 | 1. 避免打开过多选项卡,以减少系统资源占用。 | 1. 使用多进程架构确保浏览器稳定性,避免一个选项卡的崩溃影响其他页面。 |
| 9 | 渲染进程 | 每个选项卡对应一个独立的渲染进程,负责页面的渲染和 JavaScript 执行。 | 1. 优化页面的加载顺序,确保首屏内容快速呈现。 2. 使用 defer 和 async 属性异步加载 JavaScript,减少阻塞渲染的风险。 | 1. 利用代码拆分技术(如 Webpack 的 import() 进行懒加载),仅在需要时加载特定模块,减少页面初始加载体积。 |
| 10 | GPU 进程 | 负责将图形渲染交给 GPU 处理,提升页面的渲染速度和效率。 | 1. 使用 CSS3 硬件加速提升动画和 3D 效果的性能。 2. 避免过多使用高负载的 CSS 动画和过度的页面变换效果。 | 1. 使用 Canvas、WebGL 等技术,充分利用 GPU 加速高性能图形渲染,如数据可视化、游戏等。 2. 避免不必要的 GPU 消耗,保持页面流畅性。 |
| 11 | 插件进程 | 负责处理浏览器中的插件(如 Flash、PDF 插件),确保插件的独立性和稳定性。 | 1. 降低插件的使用频率,避免过度依赖插件。 | 1. 使用现代 Web API(如 WebAssembly、PWA 等)替代传统插件,提升性能和兼容性,减少插件进程的开销。 |
4. 网络
1. HTTP
1.1 常见HTTP状态码
1.1.1 成功(2XX)
| 状态码 | 原因短语 | 说明 |
|---|---|---|
| 200 | OK | 表示从客户端发来的请求在服务器端被正确处理。 |
| 201 | Created | 请求已经被实现,而且有一个新的资源已经依据请求的需要而建立 通常是在POST请求,或是某些PUT请求之后创建了内容,进行的返回的响应。 |
| 202 | Accepted | 请求服务器已接受,但是尚未处理,不保证完成请求 适合异步任务或者说需要处理时间比较长的请求,避免HTTP连接一直占用。 |
| 204 | No content | 表示请求成功,但响应报文不含实体的主体部分。 |
| 206 | Partial Content | 进行的是范围请求,表示服务器已经成功处理了部分GET请求 响应头中会包含获取的内容范围(常用于分段下载)。 |
1.1.2 重定向(3XX)
| 状态码 | 原因短语 | 说明 |
|---|---|---|
| 301 | Moved Permanently | 永久性重定向,表示资源已被分配了新的URL 比如,我们访问http://www.baidu.com会跳转到https://www.baidu.com。 |
| 302 | Found | 临时性重定向,表示资源临时被分配了新的URL,支持搜索引擎优化 首页,个人中心,遇到了需要登录才能操作的内容,重定向到登录页。 |
| 303 | See Other | 对于POST请求,它表示请求已经被处理,客户端可以接着使用GET方法去请求Location里的URI。 |
| 304 | Not Modified | 自从上次请求后,请求的网页内容未修改过 服务器返回此响应时,不会返回网页内容(协商缓存)。 |
| 307 | Temporary Redirect | 对于POST请求,表示请求还没有被处理,客户端应该向Location里的URI重新发起POST请求 不对请求做额外处理,正常发送请求,请求location中的url地址。 |
因为post 请求 ,是非幂等的,从302中细化出了303和307
简而言之: 301、302、307都是重定向
304协商缓存。
1.1.3 客户端错误(4XX)
| 状态码 | 原因短语 | 说明 |
|---|---|---|
| 400 | Bad Request | 请求报文存在语法错误(传参格式不正确)。 |
| 401 | Unauthorized | 权限认证未通过(没有权限)。 |
| 403 | Forbidden | 表示对请求资源的访问被服务器拒绝。 |
| 404 | Not Found | 表示在服务器上没有找到请求的资源。 |
| 408 | Request Timeout | 客户端请求超时。 |
| 409 | Conflict | 请求的资源可能引起冲突。 |
1.1.4 服务端错误(5XX)
| 状态码 | 原因短语 | 说明 |
|---|---|---|
| 500 | Internal Server Error | 表示服务器端在执行请求时发生了错误。 |
| 501 | Not Implemented | 请求超出服务器能力范围,例如服务器不支持当前请求所需要的某个功能,或者请求是服务器不支持的某个方法。 |
| 503 | Service Unavailable | 表明服务器暂时处于超负载或正在停机维护,无法处理请求。 |
| 505 | HTTP Version Not Supported | 服务器不支持,或者拒绝支持在请求中使用的HTTP版本。 |
当前端看到控制台报出 400时,前端先检查传参格式是否有误。
1.2 HTTP缓存
| 缓存类型 | 机制 | 关键字段 | 工作原理与特性 | 状态码 |
|---|---|---|---|---|
| 强缓存 | 浏览器直接使用缓存,不向服务器发送请求。 | Expires、Cache-Control | 1. Expires基于绝对时间控制缓存,时间到期后缓存失效,可能受客户端与服务器时间差异影响。 2. Cache-Control通过max-age设置相对时间,支持no-cache、no-store等选项,优先级高于Expires,能够更灵活地控制缓存策略。 | 无请求,直接使用缓存 |
| 协商缓存 | 浏览器向服务器发送请求,服务器验证缓存是否可用。 | Last-Modified/If-Modified-Since、ETag/If-None-Match | 1. Last-Modified服务器返回资源的最后修改时间,浏览器请求时带上If-Modified-Since进行对比,判断资源是否发生修改。 2. ETag服务器生成资源的唯一标识符ETag,浏览器请求时通过If-None-Match检查资源是否变化,ETag精度高于Last-Modified,解决了Last-Modified无法准确标识频繁修改和时间同步的问题。 3. 若缓存未失效,服务器返回304 Not Modified,浏览器使用本地缓存。 | 304 Not Modified |
| Expires | 通过绝对时间控制缓存过期。 | Expires | 1. Expires以绝对时间标识缓存失效时间。 2. 由于基于服务器时间,如果客户端和服务器的时间不一致,可能导致缓存问题。 | 无请求,直接使用缓存 |
| Cache-Control | 通过相对时间控制缓存行为,优先级高于Expires。 | Cache-Control | 1. max-age缓存有效期,单位为秒。 2. no-cache强制浏览器每次都需要向服务器验证缓存是否可用。 3. no-store完全禁止缓存,每次都需要从服务器获取资源。 | 无请求,直接使用缓存 |
| Last-Modified | 通过资源最后修改时间判断缓存有效性。 | Last-Modified、If-Modified-Since | 1. 服务器返回资源的最后修改时间Last-Modified,浏览器请求时带上If-Modified-Since进行对比,判断资源是否变化。 2. 问题:Last-Modified精度只能到秒,无法处理1秒内多次修改的情况。 3. 服务器时间可能不一致,导致缓存判断不准确。 4. 解决方案:通过结合ETag使用,ETag可以更准确标识资源变化。 | 304 Not Modified |
| ETag | 通过资源唯一标识符判断缓存有效性,精度更高。 | ETag、If-None-Match | 1. 服务器生成资源唯一标识符ETag,浏览器请求时带上If-None-Match进行对比,判断资源是否变化。 2. 为什么需要ETag:Last-Modified只能精确到秒,若1秒内多次修改,无法准确标识资源变化。 3. 服务器时间不同步,Last-Modified可能不准确。 4. ETag更加精确,可解决这些问题。ETag是服务器自动生成或由开发者定义的唯一标识符,确保缓存准确性。 5. ETag和Last-Modified可以一起使用,先验证ETag,再验证Last-Modified。 | 304 Not Modified |
1.2.1 缓存机制流程总结
| 缓存流程 | 解释 |
|---|---|
| 强缓存 | 1. 浏览器首先根据Expires或Cache-Control判断是否命中强缓存,若命中,则直接从缓存中加载资源,不发送请求到服务器。 |
| 协商缓存 | 2. 若强缓存未命中,浏览器向服务器发送请求,通过Last-Modified或ETag验证缓存是否仍然有效,若缓存有效,服务器返回304 Not Modified,浏览器继续使用本地缓存资源。 |
| 完整请求 | 3. 如果协商缓存也未命中,服务器将返回完整的资源内容,浏览器更新本地缓存并加载新资源。 |
1.3 HTTP场景属性
总结:
- 高优先级属性:max-age和no-cache常用于控制缓存时长和获取最新资源。
- 敏感信息控制:no-store和private确保缓存安全,特别是处理个人隐私和敏感数据。
- 验证机制:etag和last-modified提供了更细致的版本控制和缓存验证机制。
- 优化体验:stale-while-revalidate和stale-if-error提高了缓存使用的灵活性,确保高可用性。
| 属性 | 描述 | 应用场景 |
|---|---|---|
| max-age | 设置缓存的最大存储时间,单位为秒,在该时间内直接从缓存读取。 | 常用于静态资源(如 JS 、CSS )缓存,提升加载速度。 |
| no-cache | 每次请求都需向服务器验证资源是否更改,未修改时才使用缓存副本。 | 适用于需要确保获取最新内容的场景,如动态内容。 |
| no-store | 不存储任何缓存,每次都从服务器获取最新资源。 | 适用于敏感信息,如支付或个人数据。 |
| private | 缓存只对单个用户有效,不能被共享缓存(如CDN)存储。 | 适用于个性化内容或用户私人数据。 |
| public | 允许所有缓存(包括代理、CDN)存储该响应内容。 | 用于公共资源(如图片、CSS文件),允许大规模缓存。 |
| etag | 唯一标识资源版本,判断资源是否更新,用于精确缓存控制。 | 适用于频繁更新的资源,如API响应。 |
| last-modified | 资源最后修改时间,客户端可用If-Modified-Since进行验证。 | 适用于静态资源,配合etag提供时间维度的缓存控制。 |
| immutable | 指示资源不可变,不会发起重新验证请求,永远使用缓存副本。 | 适用于不会更改的静态资源,如版本化的文件。 |
| s-maxage | 针对共享缓存(如CDN)设置的缓存过期时间。 | 适用于需要代理服务器缓存的资源。 |
| must-revalidate | 缓存过期后必须重新验证,确保内容始终最新。 | 适用于内容准确性要求高的场景,如交易页面。 |
| stale-while-revalidate | 允许缓存过期后继续使用过期副本,直到新资源获取到。 | 提高用户体验,防止加载时间过长。 |
| stale-if-error | 当服务器出错时,允许使用过期缓存副本。 | 用于保障可用性,避免服务器故障时用户请求失败。 |
| Vary | 指定基于请求头的不同响应版本,常用于处理内容协商(如根据User-Agent返回不同内容)。 | 适用于根据请求头返回不同响应的场景。 |
1.4 取消HTTP缓存
| 类型 | 操作方式 | 描述 |
|---|---|---|
| 取消强缓存 | 设置Cache-Control: no-store | no-store会禁止缓存的任何内容,浏览器每次都会直接从服务器获取资源。用于确保不缓存任何内容,常用于敏感数据传输(如支付、账户信息)。 |
| 取消协商缓存 | 设置Cache-Control: no-cache和Pragma: no-cache | no-cache会强制客户端每次请求都发送到服务器进行验证,即使存在缓存也不能直接使用,必须确认资源是否修改。Pragma确保兼容老旧HTTP/1.0代理服务器。 |
| 完全取消缓存 | 同时设置Cache-Control: no-store, no-cache, must-revalidate和Expires: 0以及Pragma: no-cache | no-store完全禁止缓存,no-cache强制每次验证,must-revalidate确保过期时强制重新获取资源,Expires: 0和Pragma: no-cache确保彻底禁用缓存。 |
2. TCP和UDP区别
| 区别维度 | TCP (传输控制协议) | UDP (用户数据报协议) |
|---|---|---|
| 连接方式 | TCP 是面向连接的协议,传输数据前需要通过三次握手建立连接,传输完成后需要通过四次挥手断开连接,确保双方准备就绪。 | UDP 是无连接的协议,发送数据时无需建立连接,直接将数 据报发送给目标,不保证目标主机是否处于可接收状态。 |
| 传输可靠性 | TCP 提供可靠的传输机制,包括顺序控制、丢包重传和数据完整 性检查,确保数据准确传输且顺序无误。 | UDP 不提供可靠性保障,没有顺序控制、丢包重传机制,数 据报可能乱序到达,且丢包后不会进行重传。 |
| 传输效率 | TCP 由于需要进行握手、确认、重传和流量控制等操作,开销较 大,传输效率较低,适合对数据可靠性要求高的场景。 | UDP 不需要连接建立和流量控制,传输过程简单,开销小, 传输效率高,适合实时性要求高但对丢包容忍的场景。 |
| 适用场景 | TCP 适用于对数据完整性和传输可靠性要求高的应用,如网页浏 览、文件传输、电子邮件等。 | UDP 适用于对实时性要求高、对丢包不敏感的场景,如视频 会议、在线游戏、流媒体传输等实时通讯场景。 |
3. HTTP各版本区别
| 维度 | HTTP/1.1 | HTTP/2 | HTTP/3 |
|---|---|---|---|
| 传输层协议 | 基于 *TCP*,受限于 TCP 的连接管 理和传输效率。 | 基于 *TCP*,但通过多路复用和头部压 缩优化传输效率。 | 基于 *UDP*,使用 *QUIC* 协议,彻底优化传输 层,规避 TCP 的固有问题。 |
| 连接复用 | *无多路复用*,每个请求—个连接, 容易造成 *队头阻塞*。 | *多路复用*, —个连接传输多个请求,减 少连接消耗和阻塞。 | *多路复用*,基于 QUIC 提升性能,解决队头阻 塞问题,传输更快。 |
| 头部压缩 | 不支持头部压缩,传输冗余较大。 | 使用 *HPACK* 头部压缩,减少重复头部 信息。 | 使用 *QPACK*,更灵活高效的头部压缩,优化在 UDP 上的传输。 |
| 连接建立 | *三次握手* + *TLS* *两次握手*,耗时 较长。 | 虽然仍需三次握手,但 TLS 1.3 优 化了握手时间。 | *0-**RTT* 连接建立,首次握手后支持零时延连 接,大幅减少时延。 |
| 安全性 | 支持 *明文* *HTTP* 和 *TLS*,加密为 可选项,存在潜在安全风险。 | 强制使用 *TLS* *1.2/1.3*,所有传输加 密。 | *默认使用* *TLS* *1.3*,基于 QUIC 内置的安全 性,传输更安全、更高效。 |
| 队头阻塞 | *严重队头阻塞*, TCP 连接无法并发 处理多个请求。 | 应用层解决了队头阻塞问题,但 TCP 层面依然存在队头阻塞。 | QUIC 协议彻底消除了 TCP 的队头阻塞,实现 高效并发处理。 |
| 应用场景 | 适用于小规模、低并发场景,逐渐 被 HTTP/2 取代。 | 支持高并发和更快速的响应,适用于现 代网站、 API 服务和移动应用。 | 适用于低延迟、高并发的实时通信,如视频流、 在线游戏、实时协作,未来网络标准。 |
4. HTTP/3为什么使用UDP
HTTP/3选择UDP是为了彻底颠覆传统基于TCP的传输瓶颈。通过在UDP之上构建的QUIC协议,HTTP/3不仅解决了队头阻塞问题,还通过0-RTT连接大幅缩短了延迟,同时内置更强的加密和更灵活的流量控制机制。QUIC打破了TCP固有的局限。
5. 网络7层协议
| 层级 | 名称 | 功能描述 | 典型协议 | 具体应用场景 | 与其他层的关系 |
|---|---|---|---|---|---|
| 7 | 应用层 | 提供应用程序接口,直接与用户交互,实现应用服务 | HTTP、FTP、SMTP | 浏览器访问网站、发送邮件、文件传输,用户使用浏览器访问Web服务 | 应用层依赖表示层,确保数据格式转换正确;通过传输层提供可靠的数据传输,并最终在物理层传输数据。 |
| 6 | 表示层 | 负责数据格式转换、加密解密、压缩解压处理,确保数据可理解 | SSL/TLS、JPEG、MPEG | HTTPS加密通信、图片视频压缩传输,视频会议中音视频数据解码、压缩 | 表示层依赖会话层和传输层提供的数据连接,通过加密、格式转换确保上层应用能够理解和使用数据。 |
| 5 | 会话层 | 管理会话的建立、维护、同步与终止,保证数据的有序传输 | NetBIOS、RPC、SQL | 视频会议保持会话稳定性、在线游戏连接保持、文件传输中的会话控制 | 会话层依赖传输层确保数据传输的完整性,管理应用层多次请求的数据流,并在传输层中断时能够重建连接或恢复数据传输。 |
| 4 | 传输层 | 提供端到端的可靠数据传输,负责数据分段、流量控制、错误检测 | TCP、UDP | 文件传输(使用TCP确保完整性)、视频直播(使用UDP减少延迟)、数据分段传输 | 传输层通过端口号标识不同的应用层协议,并将数据分段,确保数据通过网络层正确路由传输,最终在物理层传输比特流。 |
| 3 | 网络层 | 负责路由选择和逻辑地址管理,将数据包从源地址传输到目标地址 | IP、ICMP、IGMP | IP地址分配、跨网段数据包路由选择(如互联网中的路由器传输)、数据包分发 | 网络层利用数据链路层的物理地址来传输数据帧,并将来自传输层的段封装为数据包,负责选择最佳路径传输到目标设备。 |
| 2 | 数据链路层 | 在同一物理网络上的节点之间传输数据帧,提供MAC地址寻址和纠错 | Ethernet、PPP | 局域网数据交换(交换机使用MAC地址转发数据帧)、以太网传输、错误检测与纠正 | 数据链路层将来自网络层的数据包封装为帧,通过物理层传输,并在传输过程中进行纠错和流量控制。它为网络层提供传输介质,确保数据包在物理网络上正确传输。 |
| 1 | 物理层 | 负责比特流的物理传输,定义物理介质(电缆、光纤)和传输信号 | IEEE802.3、RS-232 | 通过网线、电缆、光纤等介质传输数据,确保设备之间的物理连接(如WiFi信号传输、以太网信号传输) | 物理层为整个网络提供数据传输的基础,将来自数据链路层的数据帧转化为信号传输到接收端,并最终通过数据链路层重新组装为帧,传递给网络层。 |
6. 抓包工具
| 工具名称 | 核心功能 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|
| Wireshark | 强大的网络协议分析工具,支持实时抓包与多协议分析 | 网络调试、协议分析、安全审计 | 开源免费,支持丰富协议,强大过滤和分析功能 | 界面复杂,学习曲线较陡 |
| Fiddler | 专注于HTTP/HTTPS抓包,支持请求响应查看、修改与重放 | Web开发调试、性能测试 | HTTPS解密支持,界面简洁,适合HTTP流量分析 | 对非HTTP协议支持有限,功能比Wireshark单一 |
| Charles | 支持HTTP/HTTPS抓包,特别适用于移动端应用调试 | 移动端网络调试、请求分析 | 移动设备代理支持,网络条件模拟,可修改请求和响应数据 | 付费工具,功能比Wireshark和Fiddler相对少 |
7. 前端安全攻防
以下按照优先级排序:
| 安全威胁 | 描述 | 攻击方式 | 防范措施 | 具体项目场景 |
|---|---|---|---|---|
| 1. XSS攻击 | 恶意脚本注入,窃取用户数据或执行恶意操作。 | 在输入框、URL等注入JavaScript代码。 | 1. 输入验证和输出转义 2. 启用CSP 3. 禁用不必要的JavaScript。 | 在社交媒体项目中,防止用户在评论区输入恶意脚本窃取其他用户的Cookie或重定向至钓鱼网站。 |
| 2. 敏感数据泄露 | 前端暴露敏感信息如API密钥或用户数据,导致数据被窃取。 | 通过控制台或抓包工具查看暴露的敏感数据。 | 1. 避免在前端暴露敏感信息 2. 使用HTTPS 3. 限制前端暴露的API权限。 | 在SaaS平台中避免API密钥在前端暴露,确保使用后端代理请求。 |
| 3. CSRF攻击 | 利用用户登录状态发送伪造请求,执行敏感操作。 | 诱导用户点击恶意链接或提交表单。 | 1. 使用CSRF令牌 2. 启用SameSite Cookie 3. 对敏感操作启用双因素认证。 | 在电商平台上防止黑客利用CSRF进行伪造的购物请求或篡改账户信息。 |
| 4. 前端依赖包漏洞 | 使用不安全的第三方库,导致攻击者利用漏洞进行恶意攻击。 | 利用第三方库中的已知漏洞进行XSS等攻击。 | 1. 使用Snyk定期检查依赖包 2. 更新第三方库 3. 启用SRI。 | 在内容管理系统中防止使用过时的富文本编辑器引发的XSS攻击。 |
| 5. HTTP不安全传输 | 未使用HTTPS导致传输的敏感数据被拦截和篡改。 | 黑客通过中间人攻击拦截HTTP请求中的敏感信息。 | 1. 使用HTTPS加密数据传输 2. 启用HSTS强制使用HTTPS。 | 在支付系统中确保所有交易数据通过HTTPS传输,避免中间人攻击导致支付数据泄露。 |
| 6. 恶意代码注入 | 通过第三方脚本或库注入恶意代码,执行未授权操作或窃取数据。 | 黑客利用不安全的第三方脚本注入恶意代码。 | 1. 使用可信CDN 2. 对第三方脚本启用SRI 3. 启用CSP限制脚本来源。 | 在广告平台中防止广告脚本加载恶意代码影响用户浏览器的安全。 |
| 7. Clickjacking | 使用透明iframe覆盖合法网站诱导用户点击隐蔽的按钮。 | 在页面上嵌入恶意的透明iframe。 | 1. 使用X-Frame-Options:DENY/SAMEORIGIN 2. Frame Busting技术。 | 在银行支付系统中防止用户点击恶意iframe进行非法支付操作。 |
| 8. 本地存储滥用 | 在localStorage或sessionStorage中存储敏感信息,导致信息被窃取。 | 通过XSS攻击读取localStorage中的敏感数据。 | 1. 避免在本地存储中保存敏感信息 2. 使用HTTP-only Cookie存储重要信息。 | 在认证系统中防止用户Token存储在localStorage而被黑客通过XSS窃取。 |
| 9. 暴力破解 | 黑客通过大量密码组合尝试暴力破解用户账号。 | 黑客通过自动化工具暴力破解登录凭据。 | 1. 启用账户锁定机制 2. 使用CAPTCHA验证防止机器人攻击。 | 在用户登录系统中防止黑客暴力破解用户账户,尤其是弱密码账户。 |
5. 鸿蒙App开发
6. JSBridge跨端技术
特性
| 特性 | 详细说明 |
|---|---|
| 1. 基本概念 | JSBridge是Web端和Native端之间的桥梁,允许JavaScript调用Native功能,反之亦然。它主要用于在WebView环境下,让移动端应用中的HTML5页面与原生功能互通,实现类似于本地应用的体验。通过它,JavaScript可以访问本地资源(如相机、存储、传感器),而Native端也可以调用JavaScript函数,提供双向通信的能力。 |
| 2. 工作原理 | JSBridge通过在WebView中注入对象的方式,将Native方法暴露给JavaScript层。 1. JavaScript调用Native功能:JavaScript通过调用暴露的接口,将请求发送到Native层。 2. Native拦截并处理请求:Native层监听并处理请求,执行相应操作(如调用相机、文件系统等)。 3. Native返回结果:Native执行完操作后,将结果通过JSBridge传回JavaScript。 |
| 3. 跨平台实现 | JSBridge的跨平台实现依赖于各平台的WebView技术: 1. iOS:使用JavaScriptCore或WKWebView,在JavaScript环境中注入Native对象,从而实现调用本地功能。 2. Android:通过WebView.addJavascriptInterface,将Native对象暴露给JavaScript使用,便于调用设备功能。 3. 统一接口:为了保持跨平台一致性,开发者通常封装一套JSBridge接口,提供统一的调用方式。 |
| 4. 通信流程 | JSBridge通信流程包括: 1. JavaScript端发起调用:JavaScript通过调用JSBridge提供的接口,发送请求(如调用相机、文件上传)。 2. Native端拦截请求:Native端通过WebView拦截请求,并解析其中的数据,执行相应的操作。 3. 返回结果:Native执行完操作后,将结果返回给JavaScript,通常通过回调函数或Promise处理结果。 |
| 5. 优势 | JSBridge的优势在于: 1. 双向通信:支持Web和Native之间的双向调用,实现丰富的功能交互。 2. 灵活性高:可以根据不同业务需求,灵活地调用设备功能(如摄像头、GPS、麦克风等),适应各种复杂的场景。 3. 跨平台兼容:通过封装统一接口,保证在iOS和Android等不同平台上的—致性,降低开发和维护成本。 4. 扩展性强:可以不断扩展功能,接入新的Native能力。 |
| 6. 使用场景 | JSBridge广泛应用于以下场景: 1. 调用设备功能:如相机、麦克风、GPS、传感器等设备接口,满足拍照、录音、定位等需求。 2. 文件操作:处理文件上传、下载,访问本地存储等操作,适合需要和本地文件系统交互的业务场景。 3. 支付和认证:通过调用Native端的支付SDK,或使用指纹、面部识别等本地认证功能,保障用户安全并提升体验。 4. 复杂交互:如处理大规模图像渲染、数据计算等复杂操作,借助Native端的性能优势。 |
| 7. 性能与挑战 | 1. 性能瓶颈:在高频调用场景下,JSBridge的通信开销可能较大,尤其是在需要频繁与Native端交互时,如实时图像处理、频繁的硬件调用,可能导致延迟和性能瓶颈。 2. 通信延迟:由于需要在Web和Native之间建立通信通道,存在一定的网络和系统开销,导致交互响应的延迟,特别是在低网速或低性能设备上更为明显。 3. 优化建议:减少无效的通信请求,避免频繁通信,充分利用Native的批量处理能力,结合异步操作,提升整体性能。 |
| 8. 安全性 | 1. 权限控制:JSBridge的双向通信涉及设备的敏感功能(如相机、存储),需要严格管理JavaScript调用Native方法的权限,防止恶意代码执行敏感操作。 2. 加密通信:通过HTTPS通道进行加密通信,确保数据的传输安全,防止中间人攻击。 3. 输入验证:对传入的数据进行严格的输入验证,确保JavaScript传递给Native的数据不包含恶意代码。 4. 数据隔离:避免不同域名的JavaScript共享敏感数据,提升数据安全性。 |
| 9. 框架与工具 | 常用的跨平台框架: 1. Weex:阿里推出的跨平台框架,基于JSBridge实现Web与Native交互,主要应用于电商平台和移动端项目。 2. React Native:Facebook推出的框架,通过桥接机制,允许React代码调用Native模块,具有较高的性能和稳定性,适合中大型项目开发。 3. Flutter:Google推出的跨平台框架,通过Dart和Native端通信,渲染性能极佳,适用于性能要求高的应用。 |
| 异常处理 | 在使用JSBridge时,需要处理以下异常情况: 1. 无响应或超时:Native端可能会因为任务过载或硬件问题未能及时响应。建议使用Promise或Callback机制处理超时或错误,确保应用的健壮性。 2. 兼容性问题:不同平台的实现细节差异可能导致不一致行为。建议使用Polyfill或平台适配层进行兼容性处理。 |
JavaScript部分
// 通用的JSBridge调用接口,适用于iOS和Android
function callNative(method, params) {
if (window.webkit && window.webkit.messageHandlers) {
// iOS平台调用
window.webkit.messageHandlers.JSBridge.postMessage({
action: method,
params: params || {}
});
} else if (window.JSBridge) {
// Android平台调用
window.JSBridge[method](JSON.stringify(params || {}));
} else {
console.log("JSBridge不可用");
}
}
// 处理Native端返回的数据
function onNativeResponse(data) {
console.log("收到来自Native的数据:", data);
}
// JavaScript调用Native功能(调用相机)
function callCamera() {
callNative("openCamera", {});
}
// JavaScript调用Native功能(获取用户信息)
function getUserData() {
callNative("getUserData", { userId: 123 });
}
// Native调用JavaScript函数(此函数供Native调用)
function receiveDataFromNative(data) {
console.log("从Native收到数据:", data);
}
iOS平台(Swift)部分
/*
使用WKWebView和messageHandlers在iOS中实现JSBridge
*/
import WebKit
class WebViewController: UIViewController, WKScriptMessageHandler {
var webView: WKWebView!
override func viewDidLoad() {
super.viewDidLoad()
// 配置WKWebView并注入JSBridge
let contentController = WKUserContentController()
contentController.add(self, name: "JSBridge") // 暴露JSBridge给JavaScript使用
let config = WKWebViewConfiguration()
config.userContentController = contentController
// 创建并加载WebView
webView = WKWebView(frame: self.view.bounds, configuration: config)
self.view.addSubview(webView)
let url = URL(string: "https://your-web-page.com")!
webView.load(URLRequest(url: url))
}
// 处理来自JavaScript的调用
func userContentController(_ userContentController: WKUserContentController, didReceive message: WKScriptMessage) {
if message.name == "JSBridge" {
if let body = message.body as? [String: Any], let action = body["action"] as? String {
if action == "openCamera" {
// 调用相机功能
openCamera()
} else if action == "getUserData" {
// 返回用户数据
let userData = ["name": "John", "age": 30]
let jsonData = try! JSONSerialization.data(withJSONObject: userData, options: [])
let jsonString = String(data: jsonData, encoding: .utf8)!
webView.evaluateJavaScript("receiveDataFromNative(\(jsonString))", completionHandler: nil)
}
}
}
}
// 模拟相机功能(实际实现省略)
func openCamera() {
print("打开相机")
}
}
Android平台(Java)部分
/*
使用WebView.addJavascriptInterface在Android中实现JSBridge
*/
public class WebAppInterface {
Context mContext;
WebAppInterface(Context context) {
mContext = context;
}
// 暴露给JavaScript的方法,打开相机
@JavascriptInterface
public void openCamera() {
// 调用Android相机功能
Intent intent = new Intent(MediaStore.ACTION_IMAGE_CAPTURE);
((Activity) mContext).startActivityForResult(intent, CAMERA_REQUEST);
}
// 暴露给JavaScript的方法,返回用户数据
@JavascriptInterface
public void getUserData() {
try {
JSONObject userData = new JSONObject();
userData.put("name", "John");
userData.put("age", 30);
// 调用JavaScript函数,返回数据给Web
((Activity) mContext).runOnUiThread(new Runnable() {
@Override
public void run() {
webView.evaluateJavascript("receiveDataFromNative(" + userData.toString() + ")", null);
}
});
} catch (JSONException e) {
e.printStackTrace();
}
}
}
// 设置WebView并注入JSBridge
WebView webView = (WebView) findViewById(R.id.webview);
webView.getSettings().setJavaScriptEnabled(true);
webView.addJavascriptInterface(new WebAppInterface(this), "JSBridge");
// Native端调用Web端JavaScript函数
webView.evaluateJavascript("receiveDataFromNative('Hello from Android')", null);
7. 微前端
1. 为什么要使用微前端
1、解耦⼤型项⽬。
**解释:**微前端将单体应⽤拆解为多个独⽴⼦应⽤,每个⼦应⽤都可以独⽴开发、测试、部署,减少相互依赖。
**优势:**让各团队各司其职,加快迭代速度,不再受制于单体架构中的耦合与复杂依赖,推动业务快速上线。
2、技术栈⽆关
**解释:**Qiankun ⽀持不同的前端技术栈,⽆论是 Vue、React、Angular,还是其他技术,⼦应⽤都可以⾃由选择最合适的框架。
**优势:**保护企业的技术投资,减少全局重构的⻛险,实现技术平滑过渡,同时为未来引⼊新技术提供了充分空间,最⼤化技术⾃由
度。
3、独⽴部署与发布
**解释:**每个⼦应⽤都可以独⽴部署与发布,不需要和其他⼦应⽤同步上线,极⼤地减少部署和运维的复杂度。
**优势:**更灵活的版本管理和发布策略,减少了集中发布带来的⻛险,⽀持持续交付(CI/CD),应对复杂业务需求和频繁的市场变化。
4、渐进式重构
**解释:**传统系统可通过微前端架构进⾏渐进式改造,⽆需停机重构,逐步替换旧功能。
**优势:**降低⼤规模系统重构的⻛险,将改造⼯作细化分步,保证系统的可⽤性和稳定性,显著缩短上线周期和调整周期。
5、应⽤隔离
**解释:**Qiankun 的沙箱机制保证⼦应⽤之间的隔离性,防⽌全局变量污染和 CSS 样式冲突,确保每个⼦应⽤互不⼲扰。
**优势:**有效避免了⼦应⽤之间的冲突问题,确保每个应⽤的独⽴运⾏和全局变量、样式的隔离,保证系统的稳健性和扩展性。
6、提升并⾏开发与发布效率
**解释:**各团队可以独⽴开发、测试和发布⾃⼰的⼦应⽤,不会因为其他模块的进度⽽被阻塞。
**优势:**通过分布式开发,多个团队并⾏开发、测试,缩短开发周期,极⼤提升项⽬的灵活性,避免单体架构中常⻅的协作瓶颈。
7、按需加载与性能优化
**解释:**⽀持按需加载⼦应⽤,减少初始加载的资源占⽤,显著提升应⽤的性能和⽤户体验。
**优势:**减少不必要的资源加载,提升⻚⾯⾸屏速度,尤其适合复杂的企业级应⽤场景,提升了系统的整体响应速度和⽤户交互体验。
8、⻓期可扩展性
**解释:**微前端架构使得应⽤具备更⾼的可扩展性,新的⼦应⽤可以轻松集成,⽽不会对现有应⽤造成影响。
**优势:**实现企业级应⽤的⻓期扩展规划,轻松添加新业务模块,不必担⼼破坏现有业务,减少系统重构成本,确保未来业务增⻓的灵活应对。
9、团队独⽴性与治理增强
**解释:**每个团队可以独⽴负责某个⼦应⽤的全⽣命周期管理,增强了团队的⾃主性和独⽴性。
**优势:**团队⾃主掌控应⽤的开发、运维和发布,避免团队间的相互依赖,提升团队的⼯作效率和协作体验,推动⾼效决策和执⾏。
10、跨域通信与⽆缝集成
**解释:**提供⾼效的应⽤间通信机制,保证主应⽤和⼦应⽤之间的解耦和⾼效集成,⽀持复杂业务场景下的多应⽤协同⼯作。
**优势:**提供松耦合的通信机制,实现⼦应⽤间的⾼效协作,解决跨应⽤共享数据、事件传递等问题,确保各应⽤在复杂业务逻辑下依然保持灵活与⾼效。
2. qiankun存在的问题
| 序号 | 不足之处 | 详细描述 | 解决方案 |
|---|---|---|---|
| 1 | 样式隔离不彻底 | 浏览器的样式继承机制导致子应用间的全局样式、第三方库样式可 能相互影响,尤其在使用公共样式或 UI 组件库时, CSS 样式可 能会冲突。 | 1. 使用 CSSModules:为每个子应用定义独立的样 式作用域,避免全局样式影响。 2. ScopedCSS:在 Vue 中使用 scoped 属性, 使得样式仅作用于当前组件。 3. 通过 ShadowDOM 为子应用创建完全独立的样式 作用域,彻底避免样式冲突。 |
| 2 | 全局变量污染 | 子应用可能依赖于相同的全局对象(如window 、 document ),引发状态污染,导致多个子应用之间的 全局变量相互干扰,破坏了隔离性,进而影响应用的稳定性。 | 1. 使用 Proxy沙箱:通过 Proxy 代理全局对象 的访问,为每个子应用创建独立的全局作用域。 2. 通过沙箱隔离每个子应用的全局变量,避免不同子 应用对同—对象进行读写操作。 3. 使用 消息传递机制,通过发布-订阅模式在应用 之间传递信息,替代全局变量的共享。 |
| 3 | 内存泄露问题 | 子应用在卸载时,可能没有清理事件监听器、定时器等全局资源, 导致内存泄漏。久而久之,这种积累会拖慢整个应用,严重时可能 造成应用崩溃。 | 1. 在子应用的生命周期钩子(如beforeUnmount )中,确保注销所有的 事件监听器 和 定时器 ,避免资源被无意保留。 2. 使用 WeakMap 或 WeakSet 等弱引用数据结构 存储全局资源,这样当不再需要时,内存可以被自动 回收。 3. 定期进行 内存分析,使用浏览器开发者工具检测 并修复潜在的内存泄漏。 |
| 4 | 第三方库冲突 | 子应用可能依赖不同版本的第三方库,如果多个子应用共用全局变 量,版本差异会导致冲突,甚至影响整个系统的稳定性,特别是在 依赖旧版本库时问题更加严重。 | 1. 利用 externals 配置:在 Webpack 中将常用 的第三方库设为外部依赖,避免子应用之间加载不同 版本的库,减少冲突。 2. 使用 Web Components:为每个子应用创建独立 的 Web Components,确保不同子应用的库运行在隔 离的环境中,不会互相影响。 3. 通过 模块联邦(Module Federation) ,共享 第三方库的加载,确保相同库的单—实例,避免加载 不同版本。 |
| 5 | 路由冲突 | 主应用和子应用可能使用不同的路由框架,或者同 — URL 路径可 能被不同子应用使用,导致路由跳转异常,出现重复匹配或者页面 无法正常加载的情况。 | 1. 使用 路由前缀:为每个子应用定义不同的 URL 前缀,确保子应用的路由不会与主应用或其他子应用 冲突。 2. 使用 Qiankun 提供的 主-子应用路由同步机制,在主应用中监听子应用的路由变化,确保路径同 步。 3. 使用 hash 模式 路由,避免路由冲突与刷新时 的页面错误问题。 |
| 6 | 资源加载冲突 | 如果多个子应用加载相同的静态资源(如图标、字体或脚本),可 能导致重复加载或资源冲突,影响页面性能和资源—致性,导致最 终的 UI 呈现不—致。 | 1. 使用 CDN 加速:将常用的静态资源上传到CDN,确保所有子应用使用相同的资源版本,避免重复 加载。 2. 利用 按需加载 策略:为不同子应用配置独立的 静态资源加载策略,避免不必要的资源重复加载,减 少加载时间。 3. 通过 Subresource Integrity (SRI) 校验资 源的完整性,确保资源版本—致,避免冲突。 |
| 7 | 运行时环境差异 | 子应用可能运行在不同的浏览器或设备上,尤其在移动端和桌面端 存在不同的运行时 API 支持时,可能导致兼容性问题,进而影响 应用体验的—致性和稳定性。 | 1. 引入 Polyfill:针对不兼容的浏览器或设备引 ⼊ Polyfill,确保新特性可以在旧设备上正常运 行。 2. 环境检测:在应用启动时检测运行时环境,动态加 载合适的 Polyfill 或子应用,确保兼容性。 3. 通过 User - Agent 检测设备类型,针对不同平台 动态加载不同的资源或功能。 |
3. 理想的沙箱隔离
| 序号 | 理想沙箱目标 | 详细描述 | 实际实现方法 |
|---|---|---|---|
| 1 | 完全的全局变量隔离 | 子应用的全局变量和主应用、其他子应用的全局变量必须完全隔离,确保全局变量访问和修改仅限于子应用自己的作用域,防止变 量冲突和污染。 | 1. 使用 Proxy 代理全局对象,将每个子应用的全局变量 隔离到沙箱内。通过 Proxy 拦截对子应用中的window 、 document 等对象的访问和修改。 2. 通过 WeakMap 将每个子应用的全局对象存储在独立的 作用域中。 |
| 2 | 样式的完全隔离与作用域控制 | 子应用的样式必须完全隔离,不得影响其他子应用和主应用的样 式,保证不同子应用的样式互不干扰,避免样式冲突。 | 1. 使用 Shadow DOM 为每个子应用创建独立的样式作用 域,确保其 CSS 样式不会泄漏到全局。 2. 利用 CSS Modules 或 Scoped CSS 实现样式的局部 作用域,防止样式覆盖或冲突。 |
| 3 | 动态加载与卸载资源管理 | 子应用在加载和卸载时应动态管理其资源,确保在卸载时清除所有 的脚本、样式、事件监听器、定时器等,避免残留资源影响其他应 用。 | 1. 在子应用的生命周期钩子(如 beforeUnmount)中, 清理所有事件监听器、定时器、全局状态等资源,防止内存 泄漏。 2. 通过 WeakRef 或 WeakMap 等弱引用数据结构存储子 应用的全局对象,确保内存可以自动释放。 |
| 4 | 网络请求的隔离与限制 | 子应用发出的网络请求(如 AJAX WebSocket)应独立于其他应 用,确保网络请求的权限和作用域限制在子应用范围内,避免子应 用间的数据共享和干扰。 | 1. 使用 Service Worker 代理子应用的网络请求,确保 请求在子应用的沙箱范围内处理,不泄漏到主应用。 2. 配置 CORS 和 API Gateway,为子应用设定严格的请 求策略,防止跨域或跨应用的数据共享。 |
| 5 | 子应用独立的运行时环境 | 子应用应在独立的运行时环境中执行,不能与主应用或其他子应用 共享执行上下文,确保各子应用的执行逻辑相互独立,防止意外的 上下文污染。 | 1. 使用 iframe 为子应用创建独立的 JavaScript 执行 环境,完全隔离主应用和子应用的执行上下文。 2. 通过 Web Workers 在后台处理复杂计算任务,将逻辑 处理与主线程隔离,确保不同子应用的独立性。 |
| 6 | 全局事件的隔离与控制 | 子应用的全局事件(如 window 的 resize 、 scroll 事件)在 卸载时应彻底清理,避免影响其他子应用或主应用的正常运行,确 保事件生命周期与应用生命周期—致。 | 1. 在子应用的生命周期钩子(如 beforeUnmount)中, 注销所有注册的全局事件监听器,避免内存泄漏和事件冲 突。2. 使用 事件代理机制 实现对子应用的全局事件监听的统 —管理,保证事件与应用生命周期同步。 |
| 7 | 性能与内存优化 | 理想的沙箱不仅要提供隔离功能,还要尽可能减少性能开销,优化 内存使用,避免加载过多的资源,确保主应用和子应用的运行效率 不受沙箱机制的影响。 | 1. 通过 懒加载 和 按需加载 策略,动态加载子应用的资 源,减少首屏渲染时的资源消耗。 2. 利用 浏览器性能 API 监控子应用的性能表现,并通过 优化渲染路径、减少不必要的资源加载来提升整体性能。 |
| 8 | 低侵入性与灵活性 | 沙箱应尽量减少对子应用的代码侵入,实现无缝接入,支持不同技 术栈和框架(如 Vue、React、Angular),确保不同应用的兼容 性和灵活性。 | 1. 实现沙箱时应基于 非侵入式设计,允许子应用无须大规 模改造即可接入微前端架构。 2. 使用 微前端框架(如 Qiankun 提供对多种前端技术 栈的支持,保证不同技术栈的子应用可以顺利集成。 |
| 9 | 错误隔离与恢复能⼒ | 子应用在运行时若发生错误,不能影响主应用和其他子应用的正常 运行,沙箱应具备错误隔离和恢复能力,确保系统的整体稳定性和 鲁棒性。 | 1. 通过 错误边界(Error Boundary) 捕获子应用的运 行时错误,防止其蔓延至主应用或其他子应用。 2. 引入 监控系统,实时捕获子应用异常,并通过自动恢复 机制确保系统在发生故障时可以快速恢复。 |
| 10 | 沙箱生命周期管理 | 沙箱应具备完整的生命周期管理,从子应用加载、渲染到卸载各个 阶段均应有清晰的管理策略,确保子应用与主应用及其他子应用的 生命周期协调—致。 | 1. 沙箱应提供完善的 生命周期钩子 (如beforeMount 、 beforeUnmount ),确保子应用在不同 阶段能够正确加载资源并在卸载时清理资源。 2. 支持 生命周期扩展机制,允许根据需求自定义钩子行 为,实现灵活管理。 |
4. Shadow DOM 如何解决弹框样式隔离
| 序号 | 理想目标 | 详细描述 | 实际实现方法 |
|---|---|---|---|
| 1 | 弹框样式的完全隔离 | 弹框在不同子应用之间容易出现样式冲突,理想状态下弹框的样式 应该完全隔离,确保各自的样式互不干扰,同时不影响主应用的全 局样式。 | 1. 使用 Shadow DOM 为弹框组件创建独立的DOM 树和样式作用域,确保弹框内的样式不影响外 部页面,也不受外部全局样式影响。 2. 将弹框组件封装成 Web Components,使其 拥有独立的样式作用域和逻辑,确保全局样式隔 离。 |
| 2 | 样式作用域的全局控制 | 通过 Shadow DOM,弹框的样式作用域只限于该组件内部,任何 全局样式(如 body 的字体或颜色)不会渗透到 Shadow DOM 内部,也不会将其样式传播到外部。 | 1. 在弹框组件中使用 host 选择器,使得组件 能够响应外部状态变化而不影响样式隔离。 2. 通过 Scoped CSS 与 Shadow DOM 结合, 确保外部全局样式和组件内部样式完全隔离。 |
| 3 | CSS样式冲突的彻底避免 | 传统弹框可能会受全局 CSS 覆盖,导致设计偏离预期,而使用 Shadow DOM 后,弹框的样式定义局部化,不会受到全局样式的 影响,从而确保样式—致性和稳定性。 | 1. 利用 Shadow DOM 层级隔离机制,确保外部 样式表无法影响弹框内部的布局和样式。 2. 弹框组件中的所有样式通过 Shadow DOM 层 进行封装,外部无法修改组件内的样式,实现样式 的独立性和稳定性。 |
| 4 | 弹框的跨项目一致性 | 在大型项目或微前端架构下,不同团队可能使用不同的样式规范或 框架, Shadow DOM 能确保各团队的弹框组件样式互不影响,保 证弹框在各个子应用中的—致性和独立性。 | 1. 使用 Web Components 创建标准化的弹框组 件,确保组件样式独立,方便在不同项目中复用,减少样式冲突。 2. 通过 CSS Variables 实现可配置的弹框样 式,进—步提高样式的灵活性和—致性。 |
| 5 | 提升开发和调试体验 | 通过 Shadow DOM 提供的独立样式作用域,开发者可以更轻松地 管理和调试弹框样式,无需担心全局样式的影响,大大简化了样式 调试工作,提升开发效率。 | 1. 借助开发者工具中的 Shadow DOM 可视化工 具 直接查看组件内部样式,方便开发者调试和优 化弹框组件。 2. 使用 Scoped CSS 将样式与功能分离,减少 样式冲突的调试成本。 |
5. Shadow DOM 如何支持自定义字体
总结:
引入字体:在 Shadow DOM 内部通过
<style>标签定义@font-face引入自定义字体,确保字体样式局部化。资源优化:通过 CDN 或本地缓存优化字体加载,减少加载延迟,提升用户体验。
独立作用域:通过 Shadow DOM 实现字体的局部化,保证字体样式不影响外部文档,同时实现组件内的字体样式隔离。
| 步骤 | 自定义字体支持策略 | 详细描述 | 具体实现方法 |
|---|---|---|---|
| 1 | 使用<style>标签引入字体 | 在 Shadow DOM 内部通过 <style> 标签直接引入自定义 字体,将字体样式局部化,只作用于当前 Shadow DOM 内 部的元素。 | 1. 在 Shadow DOM 的模板中,通过 <style> 标签定义 @font-face 引入自定义字体。2. 将自定义字体的 @font-face 声明嵌入到 Shadow DOM 内部,确保字体仅对该组件生效。示例如下:js const shadow = this.attachShadow({ mode: 'open' }); shadow.innerHTML= <style>@font-face { font-family: 'MyFont'; src: url('myfont.woff2'); }%style><div style="font-family: 'MyFont';">Hello World %div>; |
| 2 | 使用外部字体URL引入 | 如果自定义字体是外部的 URL,可以通过 @font-face 规 则在 Shadow DOM 内部的样式表中引入该字体,确保字体 的正确加载和显示。 | 1. 在 Shadow DOM 的 <style> 标签内,通过 @font-face 引入外部 URL 的自定义字体文件。2. 确保字体文件的 URL 正确,并且字体加载前做好回退字体处理。例如:css @font-face { font-family: 'CustomFont'; src:url('https: Ⅱexample.com/fonts/customfont.woff2') format('woff2'); } |
| 3 | 字体资源的本地缓存与优化 | 为了优化加载速度,可以将自定义字体文件存储在本地或CDN 上,以减少字体加载的延迟,避免字体加载对用户体验 造成影响。 | 1. 将字体文件上传至 CDN,并使用 @font-face 引入 CDN 上的字体资源,确保字体的快速加载。2. 通过 浏览器缓存 优化字体的加载时间,减少对网络请求的依赖。 |
| 4 | 字体的作用域控制 | 确保自定义字体只在 Shadow DOM 内部生效,避免字体样 式影响外部文档的其他部分,保证字体样式的局部化和模块 化,确保字体样式的独立性。 | 1. 在 Shadow DOM 的 <style> 标签内定义自定义字体,并通过组件内部的样式规则将字体应用于 组件内的文本。2. 通过 Scoped CSS 或 :host 选择器确保字体只影响当前 Shadow DOM 内的内容。 |
| 5 | 跨多个Shadow DOM的字体复用 | 当多个组件使用相同的自定义字体时,可以通过全局定义的 @font-face 提高字体的复用性,确保多个 Shadow DOM 共享相同的字体,而不需要在每个组件中重复引入。 | 1. 在主文档中全局引入自定义字体,并在各个 Shadow DOM 内部的样式中引用该字体。 2. 如果必须在 Shadow DOM 内部引入,使用 CDN 的字体 URL,并在各个 Shadow DOM 组件中共 享该字体。 |
| 6 | 字体加载与FOUT问题优化 | 解决 FOUT( Flash of Unstyled Text)问题,确保在 字体加载过程中提供回退字体,避免自定义字体加载延迟导 致页面内容闪烁的情况。 | 1. 使用 Font Loading API 检测字体加载状态,在字体加载完成前使用回退字体,避免闪烁问题。 2. 定义合理的字体加载顺序,确保自定义字体能够尽快加载并显示,同时避免 FOUT 现象。 |
6. Shadow Dom问题
Shadow DOM 比如 elementUI 会把一些元素渲染到body,会逃逸掉原来的body渲染到另一个地方去了,没有样式 如何解决
当使用 Shadow DOM 时, —些像 Element UI 这样的组件库,会将弹框等组件直接渲染到 body 外层(例如 el-dialog 或 el-
tooltip ),从而逃逸了 Shadow DOM 的作用域,导致这些元素失去了原有的样式。由于 Shadow DOM 的样式隔离机制,这些渲染到 body 的元素不会继承 Shadow DOM 内部的样式,造成样式缺失问题。为了解决这—问题,有几种可行的方案:
| 解决方案 | 详细描述 | 具体实现方法 |
|---|---|---|
| 1.手动控制渲染容器 | 可以通过配置或自定义组件,将原本渲染到 body 的元素改为渲 染到 Shadow DOM 内部,确保这些元素保持在 Shadow DOM 的 作用域内,从而继承正确的样式。 | 1. 修改 Element UI 弹框组件的渲染方式,将其 append-to- body 属性设置为 false ,确保弹框在 Shadow DOM 内部渲染。2. 自定义 Portal 组件,将这些需要全局渲染的元素通过编程方 式插入到 Shadow DOM 中。 |
| 2.动态插入样式 | 在组件被渲染到 body 之外时,手动将样式动态插入到 body, 确保弹框等组件即使在 body 外部渲染也能加载正确的样式。 | 1. 使用 JavaScript 动态插入需要的 CSS 样式:js const style = document.createElement('style'); style.innerHTML = .el-dialog { , 样式定义 -};document.head.appendChild(style); |
| 3.使用Scoped样式 | 通过 scoped 或 CSS Modules 局部化样式,确保弹框组件的 样式即使在 body 外部渲染时,样式也能正常生效。 | 1. 使用 scoped 样式局部化,确保弹框组件样式不会因为渲染位 置改变而丢失。 2. 在 Shadow DOM 外部的样式表中定义相关的样式规则,确保渲 染到 body 的组件能够加载正确的样式。 |
| 4.使用#part选择器 | 通过 Shadow DOM 的 **#**part 选择器,允许外部样式控制Shadow DOM 内部某些元素的样式,从而确保渲染到 body 的 元素可以通过 part 属性传递样式,解决样式隔离问题。 | 1. 在组件内部的需要渲染到 body 的元素上加上 part 属性: html<div part="dialog"> #%div>2. 在外部样式表中使用 0part 选择器定义样式: css 0part(dialog) { , 样式 - } |
| 5.自定义Portal机制 | 使用 Portal 机制,控制弹框或其他全局元素的渲染位置,使其 能够渲染在 Shadow DOM 内部或通过编程方式渲染到特定位置, 确保样式—致。 | 1. 使用 Vue 的 Portal 插件或 React 的 createPortal ⽅ 法,自定义元素渲染逻辑,确保全局组件被正确渲染到 Shadow DOM 内。 |
| 6.全局CSS引⼊ | 将 Element UI 或其他库的全局样式通过 @import 或 link 标签引入 Shadow DOM 外部的全局样式中,以便全局样式能够应 用到渲染到 body 外部的组件。 | 1. 在主文档的 <head> 中引入全局样式,确保这些渲染到 body 的组件可以应用这些样式规则。2. 使用 @import 引入外部样式表,确保所有全局组件都能继承到 正确的样式。 |
具体实现示例:
- 动态插入样式:
const style = document.createElement( 'style');
style.innerHTML = `
.el-dialog {
, 自定义样式 -
}
`;
document.head.appendChild(style);
- 自定义 Portal 机制:
在 Vue 中通过 Portal 插件将组件渲染到 Shadow DOM 中:
<portal to="#my-shadow-dom">
<el-dialog>
1 弹框内容 2
%el-dialog>
%portal>
总结:
为了在 Shadow DOM 环境中解决像 Element UI 这类会渲染到 body 外部的组件样式问题,可以使用 自定义渲染容器 、动态样式插入 、 Portal 机制 等多种方法,确保弹框等全局组件可以加载正确的样式,从而避免样式丢失问题。
7. qiankun原理
| 核心概念 | 实现原理 | 源码解析 |
|---|---|---|
| 微应用注册与管理 | 通过 registerMicroApps 注册多个子应用,定义其入口、容器、激活规则和生命周期钩子。每个子应用注册后会按照指定的激活规则(如 URL 路由)进行加载与卸载。 | 源码中的 registerMicroApps 会将子应用注册信息存储在一个全局的子应用配置数组中,并监听路由变化,当路由匹配某个子应用的 activeRule 时,会触发该子应用的加载流程。 |
| 生命周期管理 | 子应用在挂载、更新、卸载的不同阶段都有对应的生命周期钩子,如 beforeMount、mount、unmount 等。通过这些钩子可以在子应用的生命周期中执行特定的逻辑,比如资源初始化和清理。 | 源码中通过调用子应用注册时的 lifeCycles 钩子,触发子应用的生命周期事件。例如在子应用加载时调用 mount,卸载时调用 unmount,确保每个阶段的资源和状态管理得到妥善处理。 |
| 沙箱隔离机制 | Qiankun 采用了 Proxy 沙箱和快照沙箱实现子应用之间的全局变量、样式隔离。每个子应用运行在自己的沙箱环境中,防止全局变量污染。Proxy 沙箱可以拦截对全局对象的访问,实现读写隔离。 | 源码中,沙箱机制基于 Proxy 实现。对于全局对象(如 window),每次访问都会被拦截并代理到当前子应用的沙箱环境中,实现子应用间的全局变量隔离。在沙箱运行时,拦截子应用的全局变量操作。 |
| 动态加载与懒加载 | 通过 loadMicroApp 方法动态加载子应用,或通过主应用的路由激活规则懒加载子应用。子应用的资源只有在需要时才会加载,避免主应用的过度加载,提升性能。 | 在源码中,Qiankun 会根据 entry 动态加载子应用的 HTML、CSS、JS 资源,并挂载到指定的 DOM 容器中。懒加载通过 activeRule 判断是否需要加载资源,未激活的子应用资源不会加载。 |
| 子应用的通信机制 | 通过 initGlobalState 实现子应用之间的通信和全局状态管理。主应用和子应用可以共享全局状态,并通过 onGlobalStateChange 监听全局状态的变化,保持主子应用之间的状态同步。 | 源码中,initGlobalState 基于观察者模式实现,将状态变化通知所有订阅的子应用。每次状态变更时,都会触发 setGlobalState,并通知所有通过 onGlobalStateChange 注册的监听器。 |
| 路由拦截与路由同步 | Qiankun 通过拦截主应用的路由,判断路由是否匹配某个子应用的 activeRule。如果匹配成功,Qiankun 会加载并激活对应的子应用。子应用可以拥有独立的路由系统,主应用可以同步子应用的路由状态。 | 源码中,activeRule 是通过字符串匹配、正则匹配等方式实现的。当路由变化时,Qiankun 会遍历所有注册的子应用,找到匹配的子应用并加载。如果子应用的路由发生变化,主应用也可以同步更新路由状态。 |
| 沙箱快照机制 | 当某个子应用被卸载时,Qiankun 通过快照沙箱保存当前的全局状态,当该子应用再次被加载时,可以恢复之前的全局变量和样式,保持子应用状态的一致性。 | 源码中,在卸载子应用时,Qiankun 会将全局对象的状态保存为快照(如 window、document 的状态)。当子应用重新加载时,会恢复这些快照,从而保持子应用的运行环境不变。 |
| 子应用独立部署与运行 | 每个子应用可以独立开发、独立部署,主应用通过动态加载子应用的 HTML 入口文件。每个子应用的代码、样式和逻辑都是完全独立的,且子应用可以使用不同的技术栈(如 React、Vue、Angular)。 | 源码中,Qiankun 使用 fetch 请求子应用的 entry(入口 HTML),然后解析其中的资源链接,并通过 document.createElement 动态插入脚本和样式,从而实现子应用的独立运行。 |
| 性能优化 | Qiankun 通过懒加载、缓存、沙箱机制等提升性能。懒加载确保未使用的子应用不会加载,缓存机制减少重复加载的资源,沙箱隔离机制减少全局污染,确保子应用高效运行。 | 源码中,当子应用首次加载后,会缓存子应用的静态资源。下次访问时,直接从缓存中加载,避免重复请求资源。同时,沙箱的严格隔离确保全局变量不会被滥用或污染,减少了潜在的内存泄漏和性能问题。 |
| 插件化与扩展性 | Qiankun 提供了插件机制,允许开发者在子应用加载前、加载后插入自定义逻辑,或者扩展主应用与子应用的通信方式。可以灵活定制微前端的行为,适配不同的业务需求。 | 在源码中,通过 registerMicroApps 或 start 方法可以传入 plugins 参数,开发者可以通过插件机制扩展子应用的功能,执行一些额外的操作,比如日志记录、性能监控、错误处理等。 |
1. 沙箱隔离机制原理
Qiankun 的沙箱隔离机制通过 Proxy API 实现了全局变量的隔离,使用 Scoped CSS 实现了样式隔离,并通过独立的生命周期管理和子应用的快照/单例沙箱模式,实现了微前端架构中多个子应用的高效运行与隔离。该机制有效解决了全局变量污染和样式冲突问题。
核心原理
全局变量隔离
- 每个子应用都有自己的 window 全局对象。Qiankun 使用代理模式,创建子应用的独立 window 对象,所有全局变量和方法在该子应用的上下文中有效,防止与其他子应用或主应用的冲突。
- Proxy API:Qiankun 通过 JavaScript 的 Proxy 对象拦截全局变量的读写操作,确保子应用在访问和修改全局变量时,能够在自己的代理对象中操作,而不会影响其他应用的 window 对象。
样式隔离
- 每个子应用加载时会带有自己的样式表,可能会影响主应用或其他子应用的样式。为了解决这个问题,Qiankun 通过样式隔离技术,在每个子应用的 DOM 树上加上特定的命名空间前缀,使样式只对当前子应用生效。
- Scoped CSS:子应用的样式通过动态添加前缀(如 #subapp-root)进行隔离。这样可以确保子应用的样式不会污染主应用或其他子应用。
子应用生命周期管理
- Qiankun 为子应用提供了独立的生命周期管理:mount、unmount、bootstrap 等。通过这些生命周期钩子函数,子应用在加载、挂载和销毁时可以执行对应的逻辑,保证每个子应用的独立性。
- 当一个子应用被卸载时,Qiankun 会自动清理该应用的全局变量和样式,避免内存泄漏和潜在冲突。
快照沙箱与单例沙箱
- 快照沙箱:适用于非严格模式的子应用。当子应用被卸载时,Qiankun 会记录该应用的全局状态,并在下次重新加载时恢复。这种方式适合较为简单的场景,但不能完全解决复杂应用的隔离问题。
- 单例沙箱:适用于严格模式的子应用。每个子应用都有独立的全局上下文,通过 Proxy 完全隔离全局变量和方法。这种模式下,每个子应用的全局变量和方法不会被持久化,而是每次重新加载时重新初始化。
子应用代码执行环境隔离
- Qiankun 在动态加载子应用的 JavaScript 代码时,使用沙箱机制确保子应用的代码在独立的上下文中执行。通过 eval 或 new Function 形式加载子应用的脚本,保证执行环境的隔离。
多实例隔离支持
- Qiankun 支持同一个子应用的多实例运行。通过为每个实例创建独立的沙箱环境,避免不同实例之间的全局变量冲突和相互影响。
沙箱机制的优缺点
优点:
- 高效隔离全局变量:通过 Proxy 实现子应用的全局变量隔离,防止应用间的相互污染。
- 样式隔离:有效防止样式冲突,确保每个子应用的样式仅在自己的 DOM 范围内生效。
- 生命周期管理:为每个子应用提供完整的生命周期管理,确保应用在加载和销毁时能够正确处理全局状态。
缺点:
- 复杂性增加:在多个子应用之间维护沙箱隔离机制会增加代码的复杂性,特别是对 Proxy API 的使用和样式隔离处理。
- 性能开销:尽管沙箱提供了良好的隔离效果,但动态代理和样式隔离带来的性能开销在大规模应用中可能不可忽视。
8. qiankun核心使用
1. 多子应用注册与动态加载
在—个大型项目中,假设有多个子应用,如 vueApp 、 reactApp 、 angularApp,我们可以对每个子应用进行独立注册与按需加载。每个子应 用可以使用不同的技术栈,并根据路由规则动态加载。
配置示例:
Ⅱ 引入 Qiankun 的相关 API
import { registerMicroApps , start } from 'qiankun' ;
Ⅱ 注册多个子应用
registerMicroApps([
{
name : 'vueApp' , Ⅱ Vue 应用
entry : ' Ⅱlocalhost:8080' , Ⅱ Vue 子应用的入口
container : '#vue-container' , Ⅱ Vue 子应用的 DOM 容器
activeRule : '/vue' , Ⅱ 路由匹配 /vue 时激活 },
{
name : 'reactApp' , Ⅱ React 应用
entry : ' Ⅱlocalhost:8081' , Ⅱ React 子应用的入口
container : '#react-container' , Ⅱ React 子应用的 DOM 容器
activeRule : '/react' , Ⅱ 路由匹配 /react 时激活 },
{
name : 'angularApp' , Ⅱ Angular 应用
entry : ' Ⅱlocalhost:8082' , Ⅱ Angular 子应用的入口
container : '#angular-container' , Ⅱ Angular 子应用的 DOM 容器
activeRule : '/angular' , Ⅱ 路由匹配 /angular 时激活 },
]);
Ⅱ 启动微前端
start ();
优化点:
每个子应用有独立的入口、容器和激活规则,确保多个子应用可以按需加载,减少主应用的初始加载压力。
2. 多个子应用的沙箱隔离
每个子应用在运行时使用独立的 沙箱机制,确保不同子应用的全局变量、样式、脚本相互隔离,避免冲突。可以针对每个子应用启用不同的隔离策 略,保证其独立性。
优化配置示例:
Ⅱ 启用严格的沙箱隔离机制,确保多个子应用的独立性
start ({
sandbox : {
strictStyleIsolation : true , Ⅱ 启用严格的样式隔离,防止样式污染
}
});
优化点:
严格样式隔离:通过沙箱机制,确保多个子应用的全局样式互不影响,尤其在不同框架(如 Vue 和 React)共存时避免样式冲突。
3. 全局状态共享与跨应用通信
多个子应用之间可以通过 Qiankun 的 全局状态管理 实现状态共享和跨应用通信。假设多个子应用需要共享用户信息、权限数据等,可以使用 initGlobalState 在主应用和子应用之间进行状态同步。
配置示例:
import { initGlobalState } from 'qiankun' ;
Ⅱ 初始化全局状态
const initialState = { user : 'admin' , token : 'abc123' };
const actions = initGlobalState (initialState );
Ⅱ 监听全局状态变化
actions .onGlobalStateChange ((state , prev ) * { console .log ('全局状态已变化 ' , state );
});
Ⅱ 在子应用中修改全局状态(比如在 vueApp 中修改用户状态)
actions .setGlobalState ({ user : 'guest' });
优化点:
全局状态同步:多个子应用可以共享全局状态,如用户信息、权限、主题等,减少重复操作和通信延迟。
4. 独立部署与多环境管理
每个⼦应⽤可以独⽴部署在不同的环境或服务器上,主应⽤通过 动态⼊⼝ 加载⼦应⽤的最新版本。可以为每个⼦应⽤配置不同的环境变量和域
名,确保其在不同环境下独⽴运⾏。
优化配置示例(Nginx 配置):
# Vue ⼦应⽤的独⽴部署
location /vueApp/ {
proxy_pass http://localhost:8080;
}
# React ⼦应⽤的独⽴部署
location /reactApp/ {
proxy_pass http://localhost:8081;
}
# Angular ⼦应⽤的独⽴部署
location /angularApp/ {
proxy_pass http://localhost:8082;
}
优化点:
多⼦应⽤独⽴部署:每个⼦应⽤独⽴部署,可以在不同的服务器或域名下运⾏,⽅便版本管理和独⽴发布,尤其适⽤于 频繁迭代 和 多团队
协作 的项⽬。
5. 子应用的缓存与懒加载优化
为减少⽹络请求和资源浪费,可以为每个⼦应⽤启⽤ 缓存机制 和 懒加载,只有在⽤户访问时才加载⼦应⽤,并缓存其资源以供后续访问。
优化配置示例:
registerMicroApps([
{
name: 'vueApp',
entry: '//localhost:8080',
container: '#vue-container',
activeRule: '/vue',
props: { cache: true }, "$ 启⽤缓存,减少重复加载
},
{
name: 'reactApp',
entry: '//localhost:8081',
container: '#react-container',
activeRule: '/react',
props: { cache: true }, "$ 启⽤缓存
},
]);
// 启动微前端时启⽤懒加载
start();
优化点:
懒加载与缓存:⼦应⽤只有在被访问时才会加载,⾸次加载后将资源缓存下来,后续访问时⽆需重新加载,极⼤提升性能。
6. 子应用的生命周期管理与性能优化
通过⽣命周期钩⼦,可以精确控制多个⼦应⽤的加载、挂载和卸载⾏为。你可以在特定的⽣命周期阶段进⾏资源初始化或清理操作,优化内存使⽤。
优化配置示例:
const vueAppLifecycles = {
beforeMount: () => console.log('Vue ⼦应⽤挂载前'),
mount: () => console.log('Vue ⼦应⽤挂载完成'),
unmount: () => console.log('Vue ⼦应⽤卸载完成'),
};
const reactAppLifecycles = {
beforeMount: () => console.log('React ⼦应⽤挂载前'),
mount: () => console.log('React ⼦应⽤挂载完成'),
unmount: () => console.log('React ⼦应⽤卸载完成'),
};
// 注册⼦应⽤时绑定⽣命周期
registerMicroApps([
{ name: 'vueApp', entry: '//localhost:8080', container: '#vue-container', activeRule: '/vue', lifeCycles:
vueAppLifecycles },
{ name: 'reactApp', entry: '//localhost:8081', container: '#react-container', activeRule: '/react',
lifeCycles: reactAppLifecycles }
]);
start();
优化点:
⽣命周期管理:可以在⼦应⽤加载前和卸载后清理不必要的资源,避免内存泄漏,确保系统在多个⼦应⽤切换时性能稳定。
7. 路由同步与隔离优化
多个⼦应⽤可以各⾃拥有独⽴的路由系统,主应⽤和⼦应⽤之间的路由可以同步,也可以完全隔离,确保主⼦应⽤的路由操作不会冲突。
优化配置示例:
// 加载多个⼦应⽤时,独⽴设置每个⼦应⽤的路由规则
const vueApp = loadMicroApp({
name: 'vueApp',
entry: '//localhost:8080',
container: '#vue-container',
activeRule: '/app/vue',
});
const reactApp = loadMicroApp({
name: 'reactApp',
entry: '//localhost:8081',
container: '#react-container',
activeRule: '/app/react',
});
// 主应⽤与⼦应⽤的路由系统可以同步,也可以独⽴运⾏
9. 主流微前端框架区别
| 框架方式 | 区别 | 应用场景 | 缺点 |
|---|---|---|---|
| Qiankun | 基于 single-spa,支持不同技术栈 的应用集成,提供完善的应用生命周期 管理和沙箱隔离机制,确保主应用与子 应用之间的独立运行。 | 适用于多团队协作、技术栈多样化的复 杂企业级系统,特别是业务模块相对独 立、技术更新频繁的场景,如后台管理 系统、企业门户等。 | 初期学习成本高,对于较小或简单 的项目可能显得复杂,主子应用通 信需自行管理。 |
| Iframe | 通过 iframe 标签嵌入子应用,天然 实现样式和 JS 的隔离,简单易用,子应用完全独立。 | 适合对应用隔离要求严格且无高性能要 求的简单场景,如嵌入第三方服务、展 示性子系统或完全独立的应用模块。 | 性能较差,渲染开销大,无法进行 SEO 优化,用户体验差,子应用 与主应用的通信复杂,样式隔离过 度且无法无缝集成。 |
| 无界 | 字节跳动推出,基于 iframe 提供增 强功能,支持大规模多应用管理,结合 低代码平台,提供业务快速搭建能力。 | 适合拥有大量现成的 iframe 子应用、业务模块独立性强的大型企业,尤 其适合需要快速开发和部署的内部业务 系统。 | 性能瓶颈依然存在,通信成本高, 主要依赖字节内部生态系统,跨平 台应用场景不多,无法无缝集成到 其他非字节系项目。 |
| Single-spa | 开源微前端框架,允许不同前端项目共 享同—页面,通过自定义应用生命周期 与路由管理多个子应用,兼容性强。 | 适用于需要渐进式升级、跨团队协作的 大型项目,各团队可采用不同技术栈, 逐步将旧系统迁移到新架构,如企业级 信息系统、金融平台等。 | 搭建复杂,生命周期和路由需自定 义,维护成本高,适合复杂项目但 对小项目或简单需求来说可能显得 过度设计。 |
| Module Federation | Webpack 5 的模块联邦机制,支持动 态加载远程模块,多个独立构建的应用 共享代码或组件,提升跨应用共享能力。 | 适合需要跨多个应用共享组件或代码的 场景,如跨团队、跨产品线的企业级应 用,特别是在模块间高度复用或共享状 态的需求下,如复杂电商平台、共享组 件库。 | 依赖 Webpack 生态,动态加载 和共享模块的管理复杂,需精细化 配置,模块之间的依赖管理和调试 较为复杂,适合有工程化经验的团 队。 |
| Piral | 基于 micro-frontends 的框架,支 持跨团队开发和模块化插件式扩展,通 过插件机制将各个微前端应用集成在 — 个统—的用户体验中。 | 适合大型企业级应用,如需要灵活扩展、业务模块较多的场景,尤其适合需 要—个灵活插件系统并且不同团队并行 开发的业务场景,如门户网站、 SAAS 平台等。 | 集成复杂,依赖插件机制,管理多 个插件需要较高的技术要求,初期 设置成本较高,适合大型项目,但 小项目的集成和管理成本高。 |
| ICE(阿里系) | 阿里推出的微前端解决方案,注重工程 化支持和跨平台开发,适合电商平台、 金融系统等对性能和扩展性要求高的业 务场景,支持自定义定制化的微前端架 构。 | 适合业务复杂、技术团队较大的企业, 尤其是需要跨平台、跨应用集成和定制 化微前端架构的场景,如电商、金融、 物流等需要高可用性和高扩展性的行业 系统。 | 高度依赖阿里技术生态,适合大型 企业和复杂场景,初期学习和集成 成本较高,对于中小型项目或团队,可能不具备足够的灵活性和可 用性。 |
8. React
1. Vue和React区别
总结:
Vue 更加注重模板和⾃动化的响应式系统,使⽤简单直观的⽣命周期钩⼦和组件通信⽅式,官⽅提供了完整的⽣态系统,适合中⼩型应⽤的开发。
React 更加强调函数式编程和灵活性,通过 Hooks 和 Fiber 架构精细化控制组件更新,依赖社区和第三⽅⼯具扩展功能,适合⼤型复杂应⽤的开发。
| 序号 | 实现步骤 | Vue实现 | React实现 | 核心区别 |
|---|---|---|---|---|
| 1 | 初始化 | Vue 使用 new Vue() 创建实例,传入 el、data、methods 等 选项。 Vue 是—种 MVVM 框架,视图层和逻辑层是解耦的,模板和响 应式系统会自动初始化和渲染。 | React 通过调用 ReactDOM.render() 方法将组件渲染到 DOM。React 是—种 UI 库,专注于视图层,初始化时组件会通过 JSX(或 JavaScript)定义,并传 递给渲染器处理。 | Vue 更加注重模板的 使用和自动化的数据绑 定,而 React 依赖于 JSX 或纯 |
| 2 | 响应式系统 | Vue 2 使用 Object.defineProperty 实现响应式系统, Vue 3 使用 Proxy 进行响应式代理,自动追踪依赖,并在数据变更时自动 触发视图更新。 | React 使用 setState 进行状态管理,每次状态更新时都会触发重新渲染, React 依赖于虚拟 DOM 进行高效的 DOM 差异比对和更新。 | Vue 提供了自动的响应式系统,无需手动调 用更新方法,而React 通过setState 手动触发组件的重新渲染。 |
| 3 | 模板与JSX | Vue 使用单文件组件(SFC),模板部分使用 HTML 语法,逻辑部分 使用 JavaScript,样式部分使用 CSS。Vue 通过模板编译器将模板 转换为渲染函数。 | React 使用 JSX(JavaScript 和 HTML 的混合语法)定义组件, JSX 会通过 Babel 编译为 React.createElement 的调用,返回虚拟 DOM。 | 应式系统,无需手动调 用更新方法,而Vue 更加强调模板的 可读性和直观性,而 React 则强调在JavaScript 中构建 视图。 |
| 4 | 虚拟 DOM | Vue 使用虚拟 DOM 进行高效的 DOM 更新, Vue 的虚拟 DOM 是模 板编译器生成的渲染函数,通过 Diff 算法比对新旧虚拟 DOM 并只 更新差异部分。 | React 使用虚拟 DOM 进行高效的 DOM 操作,虚拟 DOM 是通过 JSX 或React.createElement 构建的, React 使用 Fiber 架构进行增量渲染和调 度。 | React 通过Vue 的虚拟 DOM 更 加贴近模板, React的虚拟 DOM 则通过JSX 构建, React 的 Fiber 架构带来了更 细粒度的渲染调度机制。 |
| 5 | 组件化 | Vue 提供单文件组件(SFC),组件由模板、脚本和样式组成,通过 props 进行父子组件间的传递,并支持插槽(slot)机制。 Vue 的 组件系统较为灵活,支持组合和继承。 | React 使用函数式组件和类组件,通过 props 传递数据,支持 context 进行 跨层级数据共享。 React 更加推崇函数式组件,鼓励使用 Hooks 进行状态管理和 副作用处理。 | setState 手动触发Vue 的组件更加模块 化和灵活,支持多种组 合方式; React 则偏 向函数式编程,推崇使 ⽤ Hooks 来处理逻辑 和状态。 |
| 6 | 状态管理 | Vue 通过内部的响应式系统管理状态,在组件内部使用 data 定义状 态,通过 computed 和 watch 对状态进行计算和监听。外部状态 管理通常通过 Vuex 或 Pinia 实现。 | React 使用 useState、useReducer 等 Hooks 管理状态,外部状态管理通常 使用 Redux、MobX 等库。 React 的状态管理更加灵活,可以自定义状态更新逻 辑。 | Vue 的状态管理主要依赖于响应式系统,而 React 则通过函数式 Hooks 实现状态管理, React 的状态管 理相对更灵活。 |
| 7 | 事件处理 | Vue 使用模板中的 v-on 指令来监听事件,支持直接在模板中定义事 件处理函数或传递方法名称。事件处理逻辑可以通过 methods 定义 在组件中,自动绑定上下文。 | React 使用内联的 onClick 等事件处理器,事件处理器可以直接在 JSX 中定 义,也可以定义为组件方法,通过 this 或 Hooks 来访问组件内部的状态和方 法。 | Vue 提供了更简洁的 事件处理机制,通过模 板绑定,而 React 则 使用 JavaScript 的 方式进行事件绑定。 |
| 8 | 生命周期钩子 | Vue 提供了完整的生命周期钩子函数,如beforeCreate、created、mounted、beforeUpdate、updated 等,用于在组件不同阶段执行相应的操作。 | React 类组件使用生命周期方法(如componentDidMount、componentDidUpdate、componentWillUnmount), 函数组件使用 useEffect Hook 来处理生命周期。 | Vue 的生命周期钩子 更加语义化, React的类组件生命周期较为 复杂,函数组件的useEffect 更加简洁,统—了不同的生命 周期操作。 |
| 9 | 依赖收集和变更 | Vue 通过 Dep 和 Watcher 实现依赖收集和变更通知。组件渲染时 会收集依赖的响应式数据,当数据变化时,触发相应的 Watcher 重 新渲染组件。 | React 通过 useEffect Hook 或 shouldComponentUpdate 方法控制组件的 更新, React 会比较新旧状态或 props 来决定是否重新渲染组件。 | Vue 使用自动依赖追 踪机制,而 React 则 通过手动控制组件更新 逻辑。 |
| 10 | 性能优化 | Vue 通过虚拟 DOM、模板编译优化、异步更新队列、静态节点标记 (Vue 3)等技术来提升性能。 Vue 3 还引入了 Fragment 和Suspense 等特性来优化渲染性能。 | React 通过虚拟 DOM、React Fiber 架构进行性能优化,使用shouldComponentUpdate、React.memo、useMemo、useCallback 等技术 来减少不必要的重新渲染。 | Vue 提供了内置的模板编译优化和自动依赖 追踪机制,而 React 通过 Hooks 和Fiber 架构更精细化 地控制渲染, React的性能优化更加灵活但 需要手动配置。 |
| 11 | 生态系统与扩展 | Vue 的官方生态系统包括 Vue Router、Vuex、Pinia 等, Vue 提 供了渐进式的架构,允许开发者根据需求扩展功能, Vue 的组件库和 插件生态丰富,特别适用于中小型应用的开发。 | React 的生态系统更加开放, React 本身是—个 UI 库, React Router、Redux 等状态管理工具是社区提供的, React 依赖第三方库扩展功能, React 更 加适合大型应用的开发。 | Vue 官方提供了完整 的生态系统,而React 依赖于社区和第三方工具扩展。 Vue 更加适合中小型应用, React 则更加灵活,适合大型复杂应用。 |
| 12 | 组件通信 | Vue 通过 props 传递数据,通过 $emit 触发父组件事件,提供插 槽(slots)和依赖注入(provide/inject)来实现跨层级组件的通 信。 Vuex 通常用于管理全局状态。 | React 通过 props 传递数据,函数组件使用 useContext Hook 实现跨层级 通信, Redux 通常用于全局状态管理。 | Vue 提供了多种内置的组件通信方式(如插 槽、provide/inject), ⽽ React 主要依赖 props 和context,并通过 Hooks 扩展通信能 力。 |
| 13 | 调试工具与开发体验 | Vue 提供 Vue Devtools,用于调试组件状态、事件和路由。 Vue的单文件组件和模板语法简化了组件开发,开发者可以轻松调试和查看 组件状态。 | React 提供 React Devtools,可以查看组件树、 Hooks 状态和性能分析。 JSX 和 Hooks 提供了更加灵活的开发体验,开发者可以自由选择不同的开发工具和调 试方案。适合自定义的复杂场景。 | Vue 的调试工具更加直观,专注于组件和状 态的可视化,而React 的调试工具和 开发体验更加灵活 |
2. Vue和React diff算法区别
总结:
核⼼算法:Vue 采⽤了双端 Diff 算法,并在 Vue 3 引⼊了静态节点标记和 Block Tree 优化。React 则通过 Fiber 架构带来了更细粒度的异步渲染调度。
性能优化:Vue 依赖于编译时的优化⼿段,如静态节点标记、块级节点优化,⽽ React 更依赖运⾏时的 Fiber 架构和⼿动优化配置,如shouldComponentUpdate、 memo 。
组件更新:Vue 使⽤异步队列批量更新组件,⽽ React 的 Fiber 架构允许可中断的异步渲染,通过时间分⽚提升⼤规模更新的性能。两者在 Diff 算法的实现上,都优先同级⽐较,并通过 key 优化列表渲染,但 Vue 更依赖编译时优化,React 倾向于运⾏时的⼿动优化和调度控制。
| 序号 | 实现步骤 | Vue Diff 算法 | React Diff 算法 | 核心区别 |
|---|---|---|---|---|
| 1 | 核心算法概述 | Vue 2 的 Diff 算法基于双端比较, Vue 3 引入了 静态节点标记和 Block Tree 优化, Vue 的 Diff 过程主要在同级别节点中进行比较,不跨级别比对,时间复杂度为 O(n)。 | React 使用基于 Fiber 的 Diff 算法,在 React 16 及以后的版本中采用,优化了递归渲染的性能。 React 的 Diff 算法基于深度优先的树形结构,时间复杂度为 O(n), 同样不跨级别进行比较。 | Vue 3 在 Vue 2 的双端 Diff 算法基础 上引入了 Block Tree 进行优化, React 的 Fiber 架构通过更细粒度的渲染机制,提升了更新的性能。 |
| 2 | 同级比较与跨级限制 | Vue 的 Diff 算法只在同级别的节点中进行比较,不 会跨层级进行对比。如果父节点不同,则不会对子节 点进行对比,而是直接替换整个节点树。 | React 的 Diff 算法同样限制在同级比较,不会跨级别对 比。如果发现某个层级的节点发生变化,会直接删除原节点 并重新创建新节点,而不会进行深层次对比。 | Vue 和 React 都采取了同级别比较的策 略,避免跨级比较,提升了 Diff 的效率。 |
| 3 | 双端比较优化 | Vue 2 的 Diff 算法使用双端比较法,在对比新旧 节点时,会同时从头尾两个方向进行比对,找到可以 复用的节点,双端比较优化了列表节点的更新性能, 减少了不必要的 DOM 操作。 | React 的 Diff 算法没有采用双端比较,而是从头开始逐 个比对节点,并通过 key 来优化列表的更新。如果 key 不同, React 会重新创建新的节点,并销毁旧节点。 | Vue 2 采用双端比较,提升了列表节点更新 的效率,而 React 更依赖 key 来识别节 点,避免不必要的重排和重新渲染。 |
| 4 | 静态节点标记 | Vue 3 在编译阶段为静态节点打上标记,并在后续更 新过程中跳过这些静态节点,减少不必要的比对过程。静态节点的标记大大提升了页面的渲染性能,避 免每次更新都进行 Diff 计算。 | React 没有类似的静态节点标记机制,所有的节点都会被纳 ⼊ Diff 计算。如果节点没有变化, React 通过shouldComponentUpdate 或 React.memo 进行性能优 化,避免不必要的渲染。 | Vue 3 在编译时引入了静态节点标记机制, 跳过不必要的 Diff 计算,而 React 通 过手动的 shouldComponentUpdate 或 memo 来优化性能。 |
| 5 | 块级节点优化(Block Tree) | Vue 3 通过 Block Tree 结构,针对动态节点创建 块级节点,并对这些块级节点进行高效更新。这种方式避免了对静态节点的频繁更新,显著提升了复杂页 面的渲染性能。 | React 没有类似的块级节点优化,但 Fiber 架构实现了对 组件更新的精细化控制,允许开发者通过requestIdleCallback 等方式在性能允许的情况下进行 异步更新。 | Vue 3 引入的 Block Tree 针对动态内 容的更新进行优化,而 React 的 Fiber 架构更关注整体渲染的调度和性能管理。 |
| 6 | key属性的作⽤ | 在 Vue 中, key 属性用于优化列表渲染, key ⽤ 于标识每个节点的唯—性,在进行 Diff 时通过key 判断节点是否可复用,避免不必要的节点重建。 | React 的 Diff 算法同样依赖于 key 属性进行优化。 key 的存在可以帮助 React 快速识别出哪些节点发生 了变化,从而只更新发生变化的节点。如果没有 key,则React 会按照默认的索引进行对比。 | Vue 和 React 都使用 key 来优化列表 节点更新,确保在同级别节点中通过唯—标 识判断节点是否变化,减少 DOM 操作。 |
| 7 | 递归与非递归实现 | Vue 的 Diff 算法采用递归的方式进行节点更新,对 比新旧虚拟 DOM 树时,自顶向下递归对比每个节点的 差异,并更新真实 DOM。 | React 在 Fiber 架构之前同样采用递归进行节点的更新, 但在 React 16 以后, Fiber 架构使用链表结构避免了深 度递归,通过更细粒度的渲染机制(时间分片)优化了大规 模更新的性能。 | Vue 仍然使用递归的方式对比节点, React 的 Fiber 架构则通过链表结构避免深度递 归带来的性能问题,提升了复杂应用的渲染 性能。 |
| 8 | 组件更新的调度 | Vue 在组件更新时通过异步队列的方式进行更新,组 件的状态变化不会立即同步到视图,而是将所有更新 推入队列,在下—个事件循环“tick”中批量更新,从 而避免多次重复渲染。 | React 的 Fiber 架构引入了异步可中断渲染,允许组件的 更新在性能允许的情况下进行调度,通过时间分片技术将大 规模更新分解为更小的任务,避免阻塞主线程。 | Vue 通过异步队列优化组件更新,而React 的 Fiber 架构进—步优化了调度 机制,使得大规模更新任务可以分片处理, 提升了页面响应速度和流畅性。 |
| 9 | 模板与JSX的编译优化 | Vue 的模板编译器会将模板转换为渲染函数,并在编 译时进行优化。 Vue 3 引入了编译时静态提升和缓存 事件处理函数等优化手段,减少运行时的性能开销。 | React 通过 JSX 语法构建虚拟 DOM,JSX 会编译为React.createElement 的调用, React 的性能优化更多 依赖于手动配置的 shouldComponentUpdate 或 memo 进行性能优化。 | Vue 提供了更多的编译时优化选项,如静态 节点提升,而 React 更依赖开发者在运行 时手动进行性能优化。 |
| 10 | 更新粒度控制 | Vue 的 Diff 算法主要在模板内根据节点的变化进行 更新控制, Vue 3 引入了 Fragment 和Teleport 等特性,允许更灵活地控制组件和元素的 更新粒度。 | React 的 Fiber 架构允许更精细地控制组件的更新,使用 React.lazy 、 Suspense 等功能可以按需加载和渲染组 件, React 通过时间分片和优先级调度提升了更新的控制力 度。 | Vue 主要通过编译时的优化手段和新的特性 进行更新粒度的控制,而 React 的Fiber 架构允许开发者在运行时更精细地控 制渲染更新的粒度。 |
3. React 10个 hooks
规则:
只能在函数组件或⾃定义 Hooks 中使⽤ Hooks,不能在普通的 JavaScript 函数中使⽤。
Hooks 必须在组件的最顶层调⽤,不能在循环、条件判断或嵌套函数中使⽤。
| Hook名称 | 用途 | 适用场景 |
|---|---|---|
| 1.useState | 用于在函数组件中管理状态,返回当前状态和更新状态的方法。 | 适合处理局部状态,如表单输入、计数器等。 |
| 2.useEffect | 用于处理副作用,如数据获取、订阅、手动操作 DOM。依赖数组控 制副作用执行时机。 | 等效于类组件中的 componentDidMount 、 componentDidUpdate 和 componentWillUnmount,适合处理副作用逻辑。 |
| 3.useContext | 用于消费 Context 数据,避免通过 props 在多层组件中传递数 据。 | 适合组件树中多个组件共享数据的场景,如主题、认证等全局数据。 |
| 4.useReducer | 适用于复杂状态逻辑,通过不同的动作来更新状态,类似于 Redux 的 reducer 。 | 适合有多个状态更新逻辑或状态管理较复杂的场景,如表单处理或复杂状态管理。 |
| 5.useCallback | 用于缓存函数定义,避免不必要的函数重新创建。 | 适合传递函数给子组件时,避免因为父组件的重新渲染而导致子组件重复创建回调函 数。 |
| 6.useMemo | 用于缓存计算结果,避免每次渲染时重复执行开销较大的计算。 | 适合需要优化性能的场景,如依赖重计算的数据处理或复杂的计算。 |
| 7.useRef | 用于访问 DOM 元素或在组件生命周期内保存可变数据, ref 变化 不会触发组件重新渲染。 | 适合保存不需要触发更新的数据,或操作 DOM 元素时,如访问表单元素、保存计时器 等。 |
| 8.useImperativeHandle | 用于自定义暴露给父组件的 ref ,通常与 forwardRef —起使 用。 | 适合通过 ref 控制子组件行为的场景,如控制子组件的外部方法调用。 |
| 9.useLayoutEffect | 与 useEffect 类似,但会在所有 DOM 变更后同步执行,确保在 浏览器绘制前进行 DOM 操作。 | 适合需要在 DOM 渲染之前读取布局信息或同步修改 DOM 的场景,如处理动画或测量 DOM 元素大小。 |
| 10.useDebugValue | 用于为自定义 Hook 在 React 开发者工具中添加调试信息,帮助 开发者跟踪 Hook 状态。 | 适合在开发阶段为复杂的自定义 Hook 提供调试信息,提升调试过程的可读性。 |
4. useEffect-模拟生命周期钩子
| 类组件生命周期钩子 | useEffect模拟方式 |
|---|---|
| componentDidMount | useEffect(() → { , 逻辑 - }, []);传入空数组作为依赖,副作用仅在组件挂载时执行—次。 |
| componentDidUpdate | useEffect(() → { , 逻辑 - }, [dependency]);依赖数组中传入要监测的状态,副作用在指定状态变化时执行。 |
| componentWillUnmount | useEffect(() → { return () → { , 清理逻辑 - }; },[]);通过返回清理函数,副作用在组件卸载时执行清理操作。 |
总结:
省略依赖数组:副作⽤在每次组件更新时都会执⾏。
传⼊空数组:副作⽤只在 组件挂载 时执⾏,模拟 componentDidMount 。
传⼊依赖数组:副作⽤在指定依赖变化时执⾏,模拟 componentDidUpdate。
返回清理函数:在组件卸载时执⾏清理,模拟 componentWillUnmount。
5. useCallback 和 useMemo区别
useCallback 缓存的是函数, useMemo 缓存的是值。
| 特性 | useCallback | useMemo |
|---|---|---|
| 缓存对象 | 缓存 函数。 | 缓存 计算结果。 |
| 使用场景 | 当需要缓存函数,避免子组件因为接收到新的函数 props 而不必要地重新渲染。 | 当需要缓存计算结果,避免每次渲染时重复执行耗时的计算。 |
| 返回值 | 返回 缓存的函数,只有在依赖项变化时,函数才会被重新创 建。 | 返回 缓存的值 ,只有在依赖项变化时,值才会被重新计算。 |
| 适用场景示例 | 用于 优化回调函数,尤其是当回调函数作为 props 传递 给子组件时,避免子组件重复渲染。 | 用于 优化性能开销较大的计算,如复杂的数据处理或依赖特定 值的计算,避免不必要的重复计算。 |
| 关注点 | 关注 函数的重用 ,确保函数只在依赖项变化时重新创建。 | 关注 *值的重用* ,确保值只在依赖项变化时重新计算。 |
总结:
useCallback:适⽤于需要缓存 函数 的场景,特别是当该函数作为 props 传递给⼦组件时,能避免⼦组件因函数重新创建⽽不必要地重新渲染。
useMemo:适⽤于需要缓存 计算结果 的场景,能优化性能,避免每次渲染时重复执⾏性能开销较⼤的计算操作。
6. setState同步还是异步
同步中是异步,异步中同步
当在 React 事件处理函数中调⽤时, setState 是同步的,⽴即更新组件。
在异步操作(如 setTimeout、 fetch 回调等)中调⽤时, setState 可能是异步的,React 会延迟更新以优化性能。
7. 封装自定义hooks 完成网络请求
import { useState, useEffect, useCallback } from 'react';
import axios, { AxiosRequestConfig, AxiosResponse } from 'axios';
// 定义⼀个 useRequest hooks,使⽤泛型来确定 data 的类型
function useRequest<T>(url: string, options: AxiosRequestConfig = {}, deps: any[] = []) {
// 请求结果的状态:loading、数据、错误
const [loading, setLoading] = useState<boolean>(false);
const [data, setData] = useState<T | null>(null); // 泛型 T 确定 data 的类型
const [error, setError] = useState<Error | null>(null);
// 请求逻辑封装为 useCallback,避免重复定义
const fetchData = useCallback(async () "* {
setLoading(true); // 请求开始,设置 loading 状态
setError(null); // 清空之前的错误
try {
// 发送请求
const response: AxiosResponse<T> = await axios(url, options);
// 请求成功,更新数据
setData(response.data);
} catch (err) {
// 请求失败,更新错误信息
setError(err as Error);
} finally {
// 请求结束,取消 loading 状态
setLoading(false);
}
}, [url, ...deps]); // 依赖数组,当 url 或依赖发⽣变化时,重新触发请求
// 使⽤ useEffect 在组件加载或依赖变化时触发请求
useEffect(() => {
fetchData();
}, [fetchData]);
// 返回当前请求的状态,包含:loading、数据、错误信息
return { loading, data, error, refresh: fetchData };
}
export default useRequest;
8. Fiber架构
Fiber 是⼀种增量渲染机制,能够将渲染⼯作拆分为多个⼩任务,从⽽⽀持任务的中断、暂停、恢复和取消,尤其适合复杂、耗时的 UI 更
新。
总结
核⼼架构:React Fiber 架构通过将任务拆解为更⼩的⼯作单元,并通过链表结构组织组件的更新任务,避免了递归调⽤带来的性能问题,同时⽀持任务的中断和恢复。
调度与优先级:Fiber 架构引⼊了任务的调度系统,可以根据任务优先级合理调度任务执⾏,React 的调度器能够在主线程空闲时处理低优先级任务,提升整体渲染性能。
并发渲染与时间切⽚:Fiber ⽀持并发模式,允许多个任务并⾏处理,利⽤时间切⽚技术分⽚执⾏任务,避免主线程⻓时间阻塞,React 还通过 Suspense 组件处理异步加载,提升了⽤户体验。
| 序号 | 实现步骤 | React Fiber 架构 | 源码解析 | 核心设计模式 |
|---|---|---|---|---|
| 1 | Fiber架构概述 | Fiber 是 React 16 之后引入的—种新的协调算法,解决了 React 之前递归更新的性能问题。 Fiber 使用链表结构代替递归的调用栈,使得更新任务可以被 中断、恢复和拆分,支持异步渲染。 | Fiber 使用链表结构的节点,每个节点代表—个组件单元。Fiber 架构的目标是将更新任务拆分成更小的任务块,并通过 调度器 ( scheduler ) 在事件循环的空闲时间段中执行这些 任务,避免主线程长时间阻塞。 | **时间切片(Time Slicing) **和 调度模式(Scheduling Pattern) :通过 调度和分片执行任务,使得大规模更新任 务可以在性能允许时分批完成,避免阻塞 UI 渲染。 |
| 2 | Fiber Node创建 | React Fiber 架构将每个组件抽象为—个 Fiber节点, Fiber 节点是—个普通的 JavaScript 对象,包含了组件的类型、状态、更新任务等信息。每次 更新都会为每个组件生成—个新的 Fiber 节点,形成 —棵 Fiber 树。 | 源码中, Fiber 节点通过 createFiber 函数创建,包含 type (组件类型)、 key 、 pendingProps 、 stateNode (组件实例)等属性,用于存储每个组件的状态和上下文信 息。每个 Fiber 节点通过 sibling 、 child 、 return 等链表属性连接。 | 链表模式(Linked List Pattern) :Fiber 节点以链表形式组 织,使得树形结构的遍历不再依赖递归, 而是可以通过循环来实现遍历和更新。 |
| 3 | 工作单元(Unit of Work) | Fiber 将更新任务分解为—个个小的工作单元(unit of work),每个工作单元对应—个 Fiber 节点。每 次渲染时, React 会处理—个或多个工作单元,并在 空闲时间内执行这些任务,避免长时间占用主线程。 | 源码中, performUnitOfWork 函数负责处理每个 Fiber 节点的更新工作,包括调用组件的生命周期、渲染子组件等操 作。当—个工作单元完成后, React 会继续处理下—个单元, 直到处理完所有单元或遇到任务中断。 | 分治模式(Divide and Conquer Pattern) :将大规模的更新任务分解为 多个小的工作单元,可以在空闲时间执行,避免阻塞渲染。 |
| 4 | 调度与优先级 | React 的调度器根据不同任务的优先级(如用户交互、动画、数据加载等)调度更新任务。 React 会优 先处理高优先级任务,并在事件循环的空闲时间处理低 优先级任务,调度器使用优先级队列来组织和执行任务。 | Scheduler 是 React 的调度器, requestIdleCallback 或 MessageChannel 用于 检测空闲时间,调度器会根据任务的优先级决定何时执行更新。高优先级任务如用户输入会立即执行,低优先级任务则被 拆分并在空闲时执行。 | 优先级队列(Priority Queue Pattern) :任务被赋予不同的优先级, 根据优先级调度和执行任务,确保高优先 级任务(如用户输入)得到及时响应。 |
| 5 | 渲染与协调 | React Fiber 将渲染和协调过程拆分为两个阶段:“渲染阶段”(Render Phase) 和 提交阶段(Commit Phase)。在渲染阶段, React 构建新的 Fiber 树,生成更新的 DOM 节点。在提交阶段,React 将更新应用到 DOM。 | 在源码中,渲染阶段通过 beginWork 函数生成新的 Fiber 树, completeWork 函数将 Fiber 树中的节点标记为“完 成 ”。提交阶段通过 commitWork 函数,将 Fiber 树的更 新应用到真实 DOM,并执行副作用操作(如生命周期钩子、Ref 更新等)。 | 双缓冲模式(Double Buffering Pattern):通过分离渲染和提交阶段, React 可以在后台计算 Fiber 树并在 合适的时机提交到 DOM,避免渲染过程 阻塞主线程。 |
| 6 | 可中断渲染 | Fiber 架构允许渲染过程被打断和恢复。如果有更高 优先级的任务(如用户输入), React 可以中断当前 的渲染任务,先处理高优先级任务,再恢复被中断的渲 染任务。 | workLoop 是 React 的渲染主循环函数,当检测到主线程 需要执行更高优先级任务时, workLoop 可以通过shouldYield 方法中断当前渲染任务,并在完成高优先级任 务后恢复之前的任务。 | 中断恢复模式(Interrupt and Resume Pattern):允许渲染任务被 中断和恢复,优先处理高优先级任务,确 保应用响应迅速。 |
| 7 | 时间切片与并发模式 | Fiber 引入了 时间切片 概念,将大任务拆解为多个 小任务片段,可以在主线程空闲时执行每个片段,React 也引入了并发模式(Concurrent Mode),允 许多任务并行执行。 | requestIdleCallback 和 requestAnimationFrame用于检测空闲时间并分片执行任务。 React 的 Concurrent Mode 允许不同任务并发执行,利用现代浏览器的多线程能力 提升渲染性能, React 的调度器通过时间切片技术在合适的时 机执行更新任务。 | **并发模式(Concurrent Pattern)**和 时间分片(Time Slicing Pattern) :React 利用现代浏览器的 并发能力,将大任务分片执行,并在空闲 时间处理,提升渲染性能。 |
| 8 | 任务完成与提交更新 | 当所有任务单元(Fiber 节点)都处理完毕后,React 进入提交阶段,将新 Fiber 树中的变更应用 到真实 DOM 节点。提交阶段是同步的, React 会批 量更新 DOM,避免频繁的重新渲染。 | 在源码中, commitRoot 函数负责将完成的 Fiber 树提交 到 DOM。提交阶段会执行 DOM 的更新、生命周期钩子的调用、 useEffect 副作用的处理等。提交阶段是同步的,以确 保 DOM 的—致性和完整性。 | 批量处理模式(Batch Processing Pattern) :将多个小任务合并为—个批 次,避免频繁的 DOM 更新操作,提升整 体性能。 |
| 9 | 副作用处理 | Fiber 还为每个节点记录了副作用(Effect),在提 交阶段, React 会根据副作用链执行必要的操作,如 DOM 更新、 Ref 更新、生命周期钩子的调用等。 | 副作用通过 effectTag 标记并记录在每个 Fiber 节点上,在 commitRoot 函数中, React 会遍历副作用链,执 行所有的副作用操作,包括 DOM 更新、生命周期钩子、 Ref 赋值等操作,确保渲染和逻辑同步。 | 副作用模式(Effect Pattern) :记 录副作用并在合适的时机执行,确保渲染 和逻辑操作同步进行,提升 React 的渲 染和操作的—致性。 |
| 10 | 优先级恢复与更新 | 如果渲染任务被中断, React Fiber 会记录任务的完 成状态,在空闲时恢复中断的任务,确保任务不会丢失,并最终更新完成。如果数据再次变化,则重新进入 调度阶段。 | React 使用 expirationTime 来记录任务的优先级和状态,当高优先级任务完成后, React 会重新恢复之前中断的任 务,继续完成渲染,确保所有任务最终都会被处理完毕并同步 到 DOM。 | 优先级恢复模式(Priority Recovery Pattern):通过记录任务的优先级和状 态,可以中断和恢复任务,确保高优先级 任务优先执行,而低优先级任务最终也会 被完成。 |
| 11 | React Concurrent Mode | React Fiber 支持并发模式(ConcurrentMode),允许组件在多个状态更新时保持高性能响 应, React 通过“时间分片 ”技术让渲染任务并发执 行,并通过调度器在空闲时处理低优先级任务。 | 在并发模式下, React 会通过 requestIdleCallback 检 测主线程空闲时间,并在空闲时处理低优先级任务,如异步数 据加载、非关键性渲染等。并发模式通过 useTransition 等 API 控制异步渲染任务的进度和优先级。 | 并发渲染模式(Concurrent Rendering Pattern):通过时间分片 技术, React 在并发模式下可以异步处 理渲染任务,提升大规模更新的流畅性和 响应速度。 |
| 12 | 调度与React Suspense | React Fiber 引入了 Suspense 组件来处理异步加 载场景, Suspense 可以在数据加载未完成时展示占 位符内容,并在数据加载完成后恢复渲染,避免界面阻 塞,提升用户体验。 | 源码中, Suspense 通过 pending 状态标记异步任务,React 会在数据加载完成后恢复被挂起的组件渲染,并通过调 度器合理安排任务的优先级,确保界面不会被阻塞,同时异步 加载任务可以流畅地进行。 | 异步渲染模式(Async Rendering Pattern):通过 Suspense 组件控 制异步渲染任务,提升异步数据加载场景 下的用户体验。 |
2次setState演示fiber⼯作原理
| 步骤 | 执行流程 |
|---|---|
| 1.第一次setState调用 | 第—次调用 setState 时, React 会触发状态更新,进入 Fiber 架构的 Render 阶段。在此阶段, React 会创建或更 新 Fiber 树中的节点。这个过程是异步且可中断的,意味着 React 会先标记需要更新的部分,但不会立即更新 DOM。任 务被添加到调度器中,并根据优先级决定何时执行。 |
| 2.中断渲染任务 | 在 Fiber 树构建过程中,如果调度器检测到有更高优先级的任务(如用户交互),则当前低优先级任务会被中断 。Fiber 架构的设计允许这种任务中断,以确保 React 在渲染过程中依然能够响应用户的高优先级操作,比如点击按钮或输入数据。 任务中断后, React 会继续处理高优先级任务。 |
| 3.第二次setState调用 | 用户在任务中断期间调用第二次 setState ,触发新的状态更新。此时,新的状态更新被加入到更新队列中,并与第—次 setState 的更新合并处理。 React 不会立即开始新的渲染,而是等待高优先级任务完成后,再开始重新构建 Fiber树。两次 setState 的状态更新会在下—次渲染中合并执行,减少重复工作。 |
| 4.Fiber树重建 | React 通过****时间分片****机制,逐步构建新的 Fiber 树。在这个过程中, React 会处理所有挂起的状态更新,并确保只对真 正发生变化的部分进行重绘。两次 setState 的更新结果会合并处理,避免了不必要的重复计算和渲染。 React 会优先对 变动部分进行局部更新,减少整体重绘,确保性能最优化。 |
| 5.Commit阶段执行 | 当 Render 阶段完成后, React 进入Commit 阶段,这—步不可中断。在此阶段, React 会将之前标记的 Fiber 节点的 变化应用到实际的 DOM 中。 Fiber 结构中记录了所有需要操作的 DOM 节点,只会更新那些需要改变的节点,确保 DOM操作的最小化。这—步也是性能优化的关键, React 避免了无关节点的重绘。 |
| 6.更新完成后的渲染 | 经过两次 setState 调用后, React 通过 Fiber 架构的异步任务调度机制,合并了两次状态更新,并通过最小化 DOM 操作进行高效渲染。这样做不仅避免了不必要的多次重绘,还通过 Fiber 机制的任务中断与恢复功能,确保了 UI 渲染的 流畅性,特别是在复杂的交互场景下,用户体验得到显著提升。 |
React 重写 requestIdleCallback 的原因
1. requestIdleCallback 的问题
虽然 requestIdleCallback 允许开发者在浏览器的空闲时间内执⾏任务,但它存在以下⼏个问题:
不可预测性: requestIdleCallback 依赖于浏览器的空闲时间,开发者⽆法准确预测何时会有空闲时间。这使得任务执⾏的时间和频率变得不确定,尤其在⾼性能要求的应⽤中表现不佳。
浏览器⽀持问题: requestIdleCallback 并⾮在所有浏览器中都表现⼀致,尤其是在低性能设备上,它的表现可能更糟糕,导致任务调度的稳定性较差。
任务超时问题: requestIdleCallback 提供的任务可能会被浏览器推迟甚⾄超时,特别是当⻚⾯繁忙时,低优先级的任务可能很久都⽆法执⾏。
2. React 重写 requestIdleCallback
React 团队在 Fiber 架构中为了克服 requestIdleCallback 的这些局限性,重新实现了⾃⼰的任务调度系统,主要原因包括:
更精细的任务调度控制:Fiber 的调度系统允许 React 更精准地控制任务的优先级,并保证⾼优先级任务的即时响应,⽽低优先级任务可以被分⽚处理或延迟执⾏。这让 Fiber 在⾼性能场景下⽐ requestIdleCallback 更⾼效。
可预测的执⾏模型:通过 Fiber 的任务调度机制,React 可以明确控制每个任务的执⾏顺序和频率,确保⾼优先级任务不会被阻塞,且不会依赖浏览器的不可预测空闲时间。
⼀致的跨浏览器表现:React ⾃⼰实现的调度系统不依赖于浏览器原⽣的 requestIdleCallback,保证了在不同浏览器和设备上的⼀致性,特别是在低性能设备上也能保持稳定表现。
9. React性能优化
| 序号 | 优化点 | 详细说明 | 使用场景 | 注意事项 |
|---|---|---|---|---|
| 1 | React.memo优化组件重渲染 | React.memo通过浅⽐较props避免纯函数组件的⽆效渲染。当组件的props未发⽣改变时,它跳过重渲染,这极⼤优化了复杂UI组件的性能。适⽤于组件逻辑简单且数据不频繁变更的场景。 | 适用于列表项渲染、表单组件 | 对象或数组类型props需特别处理,因浅⽐较⽆法检测深层次变化,可能需结合useMemo或useCallback进⼀步优化。 |
| 2 | usememo缓存计算结果 | useMemo⽤于缓存昂贵的计算操作的结果,只有依赖项发⽣变化时才重新计算。它避免了不必要的重复计算,提⾼性能,尤其在复杂数据处理场景中极为有效。 | ⼤型表格渲染、复杂的筛选逻辑或图表渲染。 | useMemo应合理使⽤,避免滥⽤引⼊过多内存占⽤;依赖项数组应确保准确性,以避免缓存失效。 |
| 3 | useCallback缓存函数引⽤ | useCallback可以将回调函数的实例缓存起来,避免每次渲染时都生成新的函数引用,从而减少子组件不必要的重渲染。通常用于将回调函数传递给子组件时。 | 通过 React.lazy和Suspense,可以实现按需加载模块,减少初始加载体积。与Webpack的动态import()结合,能在需要时再加载组件,极大提升应用的首屏加载速度, | 注意避免闭包陷阱,依赖项变化时会重新创建数,需保证依赖项精确传递。 |
| 4 | 代码分割(Code Splitting)和懒加载 | 通过React.lazy和Suspense,可以实现按需加载模块,Webpack内置支持,合适的资源加载策略可提高页面的首屏加载速度 | ⼤型单⻚应⽤、模块化业务 | 确保Suspense的Fallback状态处理良好,提升用户在组件加载期间的体验;注意服务器端渲染时不能使用懒加载。 |
| 5 | 虚拟化长列表渲染(Virtualization) | 对于大量数据的列表,直接渲染所有D0M节点会影响性能。虚拟化技术(如react-window、react-virtualized)只渲染可见部分,随着滚动动态加载更多内容。 | 无限滚动的长列表、数据表格或消息列表。 | 需平衡滚动体验与性能,尤其注意快速滚动时是否有卡顿现象;可配合Intersection0bserver实现惰性加载,提升用户体验。 |
| 6 | shouldComponentUpdate和PureComponent优化 | 在类组件中,shouldComponentUpdate和PureComponent提供了更高效的更新控制,PureComponent会自动比较props和state进行优化 | 在类组件中,shouldComponentUpdate和PureComponent提供了对组件渲染时机的控制。PureComponent对props和state进行浅比较,避免无意义的重新渲染,特别适合静态UI组件。 | 注意浅比较的局限性,避免错误地跳过渲染;复杂对象可使用自定义比较函数来增强精确度。 |
| 7 | 减少匿名函数与内联函数的使用 | 在JSX中定义匿名函数会导致每次渲染生成新的函数实例,影性能将事件处理函数用useCallback或在组件外定义,可以避免匿名函数的重复创建,提升子组件性能。 | 父组件频繁传递回调函数的场景,如大规模表单或列表渲染时。 | 确保函数外部定义时依赖的状态是最新的,否则可能会导致意料之外的行为,如状态滞后等。 |
| 8 | 避免不必要的状态更新 | 应避免无关渲染的状态触发不必要的重渲染。例如,确保组件只更新与其直接相关的状态,可以使用局部state来避免全局state的频繁更新。此外,减少依赖组件层级传递的状态也是一种有效手段。 | 多状态管理场景、大型表单或数据处理组件。 | 使用局部useReducer或context分离非核心状态,确保state变更仅影响必要组件。 |
| 9 | React Concurrent Mode提升交互体验 | React的并发模式(Concurrent Mode)可以分割低优先级任务,确保高优先级任务(如用户交互)先行执行,提升应速度。它允许React任务中断并恢复,提升复杂交互的流畅性。 | 复杂交互场景、用户操作频繁的应用。 | Concurrent Mode是实验性功能,当前版本仅适合少数应用场景。需要深入理解调度优先级机制,确保应用不会因为中断而丢失数据。 |
| 10 | 异步组件与Suspense优化 | React Suspense用于管理异步组件加载的状态,它通过占位符在异步数据或组件加载期间展示过渡内容,避免长时间的空白页,提升用户的体验流畅度。 | 需要异步加载资源或数据的场景,如数据加载、路由懒加载。 | 配合Suspense的使用需合理设计Fallback内容,避免加载中的用户体验变差,特别是加载时间较长的情况下,可能需要设计loading动画。 |
| 11 | 精简并合理拆分组件 | 通过组件的精细化拆分,确保每个组件只关心其状态和UI逻辑,避免组件冗余逻辑导致性能下降。同时合理控制组件层级,避免过深的D0M树结构影响React Diff算法的效率。 | 复杂UI场景、多状态管理场景。 | 组件拆分需合理,过度拆分可能会导致维护成本上升,开发复杂度增加;需根据业务需求进行适当的平衡。 |
| 12 | 长列表性能优化与分页处理 | 对于大量数据展示的长列表场景,可以通过懒加载和分页处理来减少D0M节点渲染压力,避免页面因为一次性渲染大量数据而卡顿。特别是无限滚动场景下,虚拟化列表技术是提升性能的关键。 | 数据量大且用户需要快速浏览的应用场景,女如数据表格、文章列表、消息列表旁 | 确保用户滚动加载时的体验,避免页面出现白屏或跳动问题;配合Intersection 0bserver进行懒加载优化,提升数据加载流畅性。 |
10. react状态管理库
| 序号 | 状态管理库 | 特点 | 应用场景 | 适用项目类型 |
|---|---|---|---|---|
| 1 | Redux | - 基于单一状态树,全局唯一数据源(store)。 - 强调用不可变性和纯函数 reducer。 - 通过 dispatch action 更新状态。 - 支持中间件(如 redux-thunk、redux-saga)处理异步操作。 - DevTools 支持调试。 | - 适合大型项目,复杂状态管理,尤其是有严格状态管理需求的场景。 - 需要时常间隔、调试、调状态变化的项目。 | 大型项目应用,需要复杂管理状态变化的企业级项目,涉及多交互模块的系统。 |
| 2 | Redux Toolkit | - 官方推荐的简化版 Redux,解决 Redux 使用时的冗余问题。 - 内置 immer 处理不可变变化,简化 reducer 的写法。 - 集成 redux-thunk 支持异步操作。 - 提供 createSlice 简化 reducer 和 action 创建。 | - 适用于想快速使用 Redux 的最轻便项目。 - 需要简化 Redux 配置和样板代码的开发者,直接手现现 Redux 开发。 | 大型项目应用,需要简化 Redux 配置,结构清晰且易扩展的项目。 |
| 3 | MobX | - 基于响应式编程,自动追踪状态变化,实现简化。 - 使用 observable 和 observer 装饰器跟踪状态变化。 - 不强制使用不可变数据。 | - 适用于中小型项目,或无需复杂可变性管理的项目。 - 需要轻量级开发,并注重开发效率的场景。 | 中小型应用,注重开发效率,性能要求高的项目,直接与组件的状态进行绑定。 |
| 4 | Recoil | - 由 Facebook 开发,专为React设计的状态管理库。 - 状态以atoms和selectors形式组织,可以共享或局部状态。 - 支持React的concurrent模式。 - 状态变换关系自动更新,类似MobX的依赖管理。 | - 适用于需要细粒度状态控制和高性能的场景。 - 需要更复杂组件之间共享状态时,且对React深度集成有要求的项目。 | 中大型项目,前端性能优化要求高,组件通信复杂,适合与React深度集成的场景。 |
| 5 | Context API | - React内置的状态管理机制,轻量级,无需额外安装依赖。 - 配合组件树的结构层次进行状态传递。 - 适用于相对简单的全局状态管理。 - 不支持状态松散分布和组件并行扩展。 | - 适用于简单的全局状态管理,随着组件传递数据的场景。 - 小型应用场景或非复杂共享状态的场景,不需要复杂的状态逻辑。 | 小型项目或模块化较强的项目,适合简单的全局状态传递,如用户认证、主题切换等。 |
| 6 | Zustand | - 非侵入式的状态管理库,支持可组合的状态,使用hooks来管理状态。 - API 简洁易用,轻量且高效。 - 无需reducer和action,直接通过函数更新状态。 | - 适合小型项目且需要轻量级状态管理且高性能的应用场景。 - 简单使用和自用,可扩展的状态管理方案的项目。 | 中小型项目,尤其是需要轻量、高效状态管理的应用,适合开发周期较短的项目。 |
| 7 | Jotai | - 基于原子设计(atoms)的状态管理库,类似Recoil,状态之间可以独立定义。 - 自带互不依赖,适合和React Hooks结合使用。 - 没有自含store概念,每个状态都是独立的原子。 | - 适合小型项目或若状态之间隔离较强的场景。 - 不需要复杂状态管理,更易局部状态组合的项目。 | 小型项目,强调性能和模块化,适合对性能要求不高且状态比较少的应用场景。 |
| 8 | XState | - 基于状态机和状态图的状态管理库,逻辑更清晰。 - 提供处理复杂的流程和状态图支持,具有强大的调试工具。 - 支持异步操作和UI交互管理。 | - 适用于需要表示流程逻辑和状态图可视化的复杂业务场景。 - 用于UI交互逻辑和更复杂异步流程需求的项目。 | 中大型复杂项目,包含复杂业务流程和状态管理的场景,适合多步流程和异步场景的项目。 |
| 9 | Effector | - 基于事件驱动的状态管理库,事件触发更新的机制使得更新逻辑更加清晰。 - 性能优先,优化了状态依赖链路,减少不必要的组件渲染。 | - 适合复杂的状态管理逻辑,事件驱动的状态更新和交互管理。 - 更适合需要可组合的状态和策略的项目。 | 中大型项目,实时数据处理和状态管理复杂的项目,适合事件驱动和高性能需求的场景。 |
| 10 | Apollo Client | - 专为GraphQL数据管理设计的客户端库,结合缓存机制管理远程和本地数据。 - 支持缓存、数据同步,离线访问等高级功能。 | - 适用于使用GraphQL API的项目,管理远程数据和本地状态的综合场景。 - 高度依赖GraphQL的前端应用。 | 使用GraphQL技术栈的中大型应用,远程数据管理复杂,且需要缓存支持的项目。 |
| 11 | React Query | - 专注于远程数据获取和缓存管理,适用于REST和GraphQL API数据的处理。 - 提供强大的数据缓存,数据同步,重试和后台刷新功能。 | - 适用于远程数据交互频繁的项目,管理服务端数据和缓存,提供更大且灵活的数据管理机制。 - 多接口调用和实时数据交互的场景。 | 中大型项目,服务端数据交互频繁,适合复杂API调用、实时数据处理,以及需要数据缓存的应用。 |
| 12 | RxJS | - 基于响应式编程的状态管理库,使用可观察对象(Observables)处理异步数据流。 - 提供强大的异步操作控制能力,处理复杂的数据流和事件流。 | - 适用于复杂的异步操作、流式数据处理和事件驱动的应用场景。 - 项目中有大量异步任务的场景。 | 大型项目,尤其是需要处理复杂异步数据流和事件流的项目,适合数据驱动的应用场景,实时数据流和消息推送系统。 |
| 13 | Hookstate | - 基于React Hooks的状态管理库,提供可追踪的状态和不可变数据管理。 - 支持局部状态更新、插件化扩展,性能优化。 | - 适合需要局部状态更新,不可变性能优化的场景。 | 小型项目,或有高性能要求的项目,强调局部状态更新的场景,适合对性能要求较高的应用。 |
11. redux原理
使⽤级别:
- createStore:创建 Redux store 的核⼼函数,返回包含 getState 、 dispatch 、 subscribe 的对象。开发者可以通过这些⽅法在
应⽤中获取和更新状态,连接 UI 与状态管理层。常⽤于任何需要全局状态管理的场景。
- dispatch 和 reducer 的配合: dispatch 是唯⼀能触发状态变更的⽅法,⽽ reducer 负责计算新的状态。它们通过 action 的
type 字段协作,让状态更新过程简单且透明。适⽤于需要明确状态变更路径的⼤型应⽤。
- 中间件机制的灵活性:通过 applyMiddleware 接⼊中间件,开发者可以轻松处理异步操作或扩展 dispatch。例如在复杂的业务逻辑
中,使⽤ redux-thunk 处理 API 请求或 redux-saga 管理复杂的副作⽤。
- 不可变性保障与调试⽀持:Redux 强调不可变性,每次 reducer 都返回新状态对象,配合 Redux DevTools 提供状态回滚、时间旅⾏
等调试功能,极⼤提升了开发效率。适⽤于团队开发中的调试和复杂应⽤的状态管理。
源码级别:
| 序号 | Redux 核心方法 | 解释 | 源码解读与具体实现 |
|---|---|---|---|
| 1 | createStore | createStore 函数用于创建 store,这 store 保存应用的状态树,并提供了 getState(获取状态)、dispatch(分发 action)、subscribe(监听状态变化)等方法。 | 源码中,createStore 函数接收 reducer 和 preloadedState(初始状态)作为参数,返回一个对象包含 getState、dispatch、subscribe、replaceReducer 方法。通过返回对象保持 currentState 和 listeners 的引用。 |
| 2 | reducer 函数 | reducer 是一个函数,接收当前的 state 和 action,根据 action.type 返回新的 state。reducer 是一个纯函数,从而保证 Redux 的状态是可预测的。 | reducer 在 Redux 中由用户定义,接收两个参数:state 和 action。依次 dispatch 会调用所有 reducer,根据 action.type 匹配不同逻辑,并生成新的 state。源码中 switch 或 if 语句处理不同的 action 类型。 |
| 3 | dispatch 方法 | dispatch 方法负责分发特定的 action,更新状态后触发订阅者。 | dispatch 方法接受一个合法的 action。最初会调用 currentReducer 生成新的状态,然后调用 listeners 数组,通知每个订阅者状态发生变化。dispatch 方法支持嵌套调用,且在每次执行时都会校验 action 的合法性。 |
| 4 | getState 方法 | getState 方法用于获取当前的 state。在应用了 store 的中间层或调试状态时的能力,便于组件中读取或监控应用的状态。 | 源码中,getState 方法直接返回 currentState,不对任何处理。getState 主要在 Redux 调试时使用,供组件获取所有的状态信息。调用 getState 时不会触发副作用,只是简单地读取当前状态。 |
| 5 | subscribe 方法 | subscribe 方法允许开发者订阅状态变化,当 state 通过 dispatch 发生改变时,所有订阅者会被通知到状态的改变,这样可以确保应用的 UI 与状态同步更新。 | subscribe 方法将指定的监听函数添加到 listeners 数组中,当 dispatch 发生状态变更后,依次执行 listeners 数组中所有监听函数。subscribe 返回一个函数,调用该函数会取消订阅(即从 listeners 中移除)。 |
| 6 | combineReducers | combineReducers 是 Redux 的工具函数,用于将多个 reducer 组合合成一个 reducer。每个子 reducer 处理独立的状态树一部分,dispatch 时,所有组合状态都需要更新。 | 源码中,combineReducers 接受一个对象作为参数,键为 reducer 名,值为 reducer 函数。最终生成的 reducer 调用所有子 dispatch,并将返回值合并为一个对象状态。 |
| 7 | applyMiddleware | applyMiddleware 用于在 dispatch 函数中引入中间件。通过中间件拦截所有 dispatch,注入 reducer 之前,处理异步或扩展操作。此函数支持增强 dispatch 的功能,拓展实现细粒度控制。 | 源码中,applyMiddleware 将 dispatch 进行增强,通过调用链式所有中间件,逐层增强 dispatch。源码中依赖闭包,将原始 dispatch 和 getState 注入,通过嵌套函数最终增强 dispatch 新的 action。 |
| 8 | 中间件 (Middleware) | 中间件是扩展 Redux 功能的核心机制,可以用于处理异步 action,允许在 dispatch 一个 action 之前或之后注入特定逻辑。 | 常用中间件有 redux-thunk,用于处理异步 action,使允许 dispatch 一个函数;redux-saga 用于生成器函数编写复杂业务逻辑。其核心思想是拦截 action 流程,并在 dispatch 前后对 action 进行扩展控制。 |
| 9 | replaceReducer | replaceReducer 替换当前 store 的 currentReducer,并通过一次 dispatch 完成状态迁移。该操作通常用于热重载 reducer,以支持开发环境的动态刷新。 | 源码中,replaceReducer 会更新 currentReducer 并重新初始化 state——通过调用 dispatch 一个默认 action 触发。 |
| 10 | 不可变性保障 | Redux 状态与 reducer 会遵循不可变性原则,即返回新的 state 而不是修改原始 state。这种机制确保时间旅行(time travel)调试的能力。 | 源码中,reducer 通过 Object.assign 或展开运算符(...state)来复制原始对象,而非引用修改。Redux 中的时间旅行调试工具依赖于状态不可变性。 |
| 11 | DevTools 支持 | Redux 内置对 Redux DevTools 的支持,开发者能通过 DevTools 追踪状态变化、时间旅行、重构历史,查看 action 实现。 | 源码中 createStore 函数支持 DevTools,通过 window.REDUX_DEVTOOLS_EXTENSION 连接 DevTools。可直接追踪 action 和状态变化,这对调试和开发非常重要。 |
| 12 | 异步操作处理 | Redux 本身是同步的,但可以通过中间件(如 redux-thunk 或 redux-saga)处理异步操作。异步操作会在 action 执行前后扩展 dispatch 功能。 | redux-thunk 通过注入 dispatch,允许 dispatch 的参数不仅是普通对象,还可以是函数类型。函数类型 action 中可异步执行 API 调用,完成后再手动 dispatch 新的 action。 |
| 13 | 扩展性插件设计 | Redux 提供 middleware 和 enhancer 设计模式,开发者可以为 Redux Store 引入自定义逻辑,处理复杂需求或扩展功能,并通过 compose 组合多种插件实现。 | 源码中 middleware 和 enhancer 提供抽象层,允许开发者自定义扩展逻辑。compose 用于多个中间件函数的组合执行,最终实现功能集成和扩展性设计。 |
12. React Native
| 类别 | 核⼼知识点 | 详细说明 |
|---|---|---|
| 跨平台架构 | React Native 核⼼架构 | React Native 的架构由 JavaScript 层、Bridge 层和 Native 层构成,JavaScript 负责逻辑和 UI 渲染,Native 层执⾏原⽣组件操作,Bridge 实现 JS 和 Native 之间的通信。新版本中的 JSI(JavaScript Interface)替代了 Bridge,提升了性能并实现了同步通信。 |
| 虚拟 DOM 与渲染 | Reconciler、Fiber 与异步渲染 | React Native 通过虚拟 DOM 和 Reconciler 实现⾼效渲染,通过 React Fiber 进⾏异步调度与时间切⽚,确保在⾼性能场景下不会出现 UI 卡顿。Fiber 的并发模式使得 React Native 能在计算密集型任务执⾏时保持流畅的⽤户体验。 |
| 跨平台 UI 组件 | 原⽣组件与平台特定组件 | 提供了⼤量跨平台基础组件,如 View、Text、ScrollView、Image 等,能够在 iOS 和 Android 上保持⼀致的表现。同时,可以通过 Platform API 判断当前平台,从⽽渲染特定的原⽣组件,实现针对 iOS 和 Android 的定制化开发。 |
| 性能优化 | 减少 Re-render、FlatList 优化 | 使⽤ shouldComponentUpdate、React.memo、PureComponent 避免不必要的渲染,特别是对于⾼频更新的组件。FlatList 是处理⻓列表的最佳实践,⽀持惰性加载、分⻚、窗⼝回收等特性,确保⻓列表渲染时的内存占⽤最⼩化。 |
| 动画与交互 | Animated API、Reanimated 与 LayoutAnimation | Animated 和 Reanimated 是 React Native 中的⾼性能动画库,前者通过优化 JS-to-Native 通信,后者通过直接在 Native 线程上执⾏动画。LayoutAnimation 提供了简单的⻚⾯过渡动画⽀持,适合布局变化场景的动画处理,减少代码量且提升⽤户体验。 |
| 导航管理 | React Navigation、原⽣导航与动态路由 | React Navigation 是 React Native 中最流⾏的导航库,⽀持栈导航、Tab 导航、Drawer 导航等,同时可以通过 react-navigation-stack 与原⽣导航系统(如 UINavigationController、Fragment)进⾏深度集成,满⾜复杂场景下的导航需求,并⽀持基于动态路由的导航管理。 |
| 状态管理 | Redux、MobX、React Hooks 与 Context | 在复杂项⽬中,Redux 和 MobX 是最常⻅的状态管理⼯具,前者基于严格的状态流控制和中间件扩展,适合⼤型应⽤。React Hooks(如 useState、useReducer、useContext)提供了更简洁的状态管理⽅式,结合 Context 可以实现⽆需中间库的全局状态管理。 |
| 数据持久化与同步 | AsyncStorage、本地数据库(SQLite、Realm)与数据同步 | AsyncStorage 是 React Native 提供的简单键值存储 API,适合存储⼩型⽤户数据。对于复杂的存储场景,可以集成 SQLite 或 Realm 数据库,实现更⾼效的数据操作。同时可以结合 redux-persist 实现 Redux 的持久化状态管理,保证应⽤在重启后数据的保持与同步。 |
| 通信与原⽣集成 | NativeModules、JSI 与 Native-to-JS 通信 | 通过 NativeModules,可以将原⽣功能(如相机、蓝⽛、⽂件系统等)封装成 JS 模块,供 React Native 调⽤。JSI(JavaScript Interface)是新⼀代通信机制,取代传统的 Bridge,通过提供直接调⽤原⽣⽅法的能⼒,极⼤地提⾼了 JS 和 Native 通信的性能,降低通信延迟。 |
| ⽹络请求与数据处理 | Fetch、Axios 与 WebSocket 实时通信 | React Native ⽀持通过 fetch 或 Axios 进⾏⽹络请求,后者⽀持更多配置和拦截器处理。对于实时数据传输和双向通信,WebSocket 是常⽤解决⽅案,适合即时通讯、游戏等需要实时更新的数据场景。也可以结合 GraphQL 进⾏⾼效的数据查询和操作。 |
| 多线程与异步处理 | Worker 线程、多线程与异步任务处理 | React Native 中,主线程⽤于 UI 渲染,逻辑密集型任务可以通过 react-native-threads 开启多线程处理,避免阻塞主线程。同时 InteractionManager ⽤于处理复杂交互时的任务调度,确保 UI 响应优先,提升⽤户体验。对于后台任务,可以结合 react-native-background-fetch 实现定时任务调度。 |
| 原⽣模块开发 | iOS 与 Android 原⽣模块集成 | 在 React Native 中,可以通过 Objective-C/Swift 编写 iOS 原⽣模块,或通过 Java/Kotlin 编写 Android 原⽣模块,提供平台特定功能,并通过 NativeModules 暴露给 JavaScript 调⽤。使⽤ react-native-create-library 可以快速创建跨平台原⽣模块。 |
| 调试与测试 | Flipper、Jest、Detox ⾃动化测试 | Flipper 是 React Native 官⽅推荐的调试⼯具,⽀持⽹络请求、⽇志、布局检查等功能。Jest 是推荐的单元测试框架,⽀持 Mock 数据和组件渲染测试。Detox 是⽤于 E2E 测试的⼯具,可以模拟真实⽤户操作,验证应⽤功能的完整性和稳定性。 |
| 热更新与动态发布 | CodePush 动态更新与 OTA 更新 | 通过微软的 CodePush 服务,可以在不经过 App Store/Google Play 审核的情况下实现代码热更新,直接将更新推送到⽤户设备。CodePush 适⽤于⼩规模代码更新,如 UI 修复、Bug 修复,但对于需要原⽣代码变更的情况,仍需通过原⽣应⽤商店发布完整版本更新。 |
| 打包与构建 | Metro Bundler、Hermes 引擎优化启动速度与内存占⽤ | Metro 是 React Native 的默认打包⼯具,⽀持⾼效的增量编译。Hermes 是为 React Native 优化的轻量级 JavaScript 引擎,通过字节码执⾏、即时编译等技术,显著提升了应⽤启动速度和内存占⽤,特别适合资源有限的 Android 设备。Hermes 引擎⽬前主要应⽤于 Android,但 iOS ⽀持也在逐步完善中。 |
| 跨平台 API 与平台特性 | Platform API、⽂件命名规则与平台差异化处理 | React Native 通过 Platform API 判断当前运⾏平台,并根据平台执⾏特定代码逻辑。同时,可以通过 .ios.js 或 .android.js ⽂件名编写平台特定的代码,解决不同平台的兼容性问题。例如在 iOS 中使⽤ ActionSheetIOS,在 Android 中使⽤ ToastAndroid。 |
| 国际化与本地化 | i18n、react-intl、Date 和 Number 格式化 | React Native ⽀持通过 i18n-js 或 react-intl 实现应⽤的国际化和本地化处理。i18n-js 提供简单的国际化功能,通过配置不同语⾔的翻译⽂件实现语⾔切换。react-intl 则⽀持更⾼级的国际化需求,如⽇期、货币、数字的本地化格式化,能够为⽤户提供更加本地化的体验。 |
| 安全与加密 | 数据加密、HTTPS 和证书管理 | React Native 应⽤中,确保数据传输的安全性⾄关重要,所有⽹络请求应使⽤ HTTPS。同时可以通过 react-native-keychain 或 SecureStore 将敏感数据(如密码、令牌)加密存储在设备中。在数据传输⽅⾯,建议使⽤ JWT 或 OAuth2 进⾏身份验证,确保⽤户数据的安全性和隐私保护。 |
| ⾼级图形与可视化 | Skia、WebGL、⾼性能图形渲染与数据可视化渲染的应⽤ | React Native ⽀持通过 Skia 或 WebGL 进⾏⾼性能图形渲染,特别适⽤于游戏、3D 图形和数据可视化等场景。Skia 是 Google 提供的 2D 图形库,具有极⾼的渲染效率。WebGL 是⼀种跨平台的图形 API,可以结合 expo-gl 在 React Native 中使⽤,适⽤于需要复杂图形渲染的场景。 |
| 进程管理与内存优化 | 内存管理、多线程与后台任务处理 | React Native 中,确保应⽤的内存使⽤得当对性能⾄关重要。使⽤ InteractionManager 优化⾼优先级任务,使⽤ requestIdleCallback 处理低优先级任务。在内存敏感的场景下(如 Android 低端设备),需要重点关注 FlatList 的内存管理,合理配置缓存策略与分⻚加载。此外,通过 react-native-background-fetch 可以实现后台任务的⾼效调度,确保应⽤在后台运⾏时不会过度消耗设备资源。 |
13. Next.js服务端渲染
| 类别 | 核心知识点 | 详细说明 |
|---|---|---|
| 渲染模式 | 服务端渲染 (SSR) | Next.js 的核心特性之一是服务器端渲染。通过 getServersideProps,在每次请求时从服务器获取数据并渲染页面、适合需要动态数据的场景。SSR 优势在于初始页面加载时获取 SE0 友好的完整 HTML,且能保证内容的实时性,但相较于静态生成,性能负载较高。 |
| 静态生成 | 静态站点生成 (SSG) | 通过 getStaticProps 和 getstaticPaths 实现静态页面生成,适合内容变化不频繁且需要高性能的场景。SSG会在构建时生成 HTML 文件,提供极高的加载速度和 SE0 友好性。可通过 ISR(增量静态生成)结合实现部分内容的动态更新,避免频繁重建。 |
| 增量静态生成 | Incremental Static Regeneration (ISR) | Next.js 独特的特性之一,允许在不重新构建整个应用的情况下,逐步更新静态生成的页面。通过 revalidate 参数,页面可以在后台自动更新,保持静态生成的高性能同时确保内容实时更新,适合博客、新闻等动态更新频率较高的应用。 |
| 混合渲染 | 混合渲染模式 (SSG 与 SSR 混合) | Next.is 支持同一应用内使用 SSG 和 SSR 混合渲染模式,可以根据具体页面需求选择合适的渲染方式。例如,首页使用 SSG 提高加载速度,动态数据页面使用 SSR 确保数据实时性,最大限度地提升应用的性能与用户体验。 |
| 路由管理 | 文件系统路由 | 基于文件系统的自动化路由管理,开发者无需手动配置路由,直接在 pages 目录下创建 .js 文件,即可生成对应的 URL 路由。支持嵌套路由、动态路由和 Catch-all 路由,灵活性高。 |
| API 路由 | 内置 API 路由支持 | Next.js 提供了 API 路由,通过在 pages/api 目录下创建文件,可以轻松构建服务端 API,无需额外配置。每个API 路由都是一个独立的 Node.js 函数,适合处理服务器端逻辑、数据库连接、身份验证等操作,实现前后端一体化开发。 |
| 动态路由 | 动态路由与 Catch-all 路由 | 支持基于文件名的动态路由,例如 [id].js,用于动态页面的生成。。getStaticPaths 可用于生成静态路径的静态页面,getServerSideProps 用于动态渲染。Catch-all路由(如[...slug].js)可处理多个动态路径,适合处理多层级路径结构的场景。 |
| 数据获取 | getStaticProps, getServerSideProps 和 getStaticPaths | getStaticProps 用于静态生成页面时获取数据,getServerSideProps 用于每次请求时获取数据并进行服务器端渲染,getStaticPaths 用于生成静态路径,三者结合可实现灵活的数据获取,满足不同业务场景的页面数据需求。 |
| API 数据获取与缓存 | SWR 与 react-query 数据管理 | 在客户端数据获取时,Next.js 推荐使用 SWR 或 react-query 实现数据高效获取与缓存。SWR 提供了自动缓存、自动更新的特性,支持离线数据获取;react-query 则是一个更强大的数据管理库,支持数据缓存、预取、分页等功能。两者都支持 API 数据进行优化管理。 |
| Image 优化 | Next.js Image 组件 | 内置的 next/image 组件支持自动图像优化、懒加载和自适应图像大小,帮助开发者减少页面加载时间。图像会根据屏幕分辨率和设备类型动态调整大小,并通过 WebP 等格式优化,极大地提升性能和用户体验,特别适合电商类应用或需要大量图像展示的页面。 |
| CSS 处理 | CSS Modules, 全局样式与 styled-jsx | Next.js 支持 CSS Modules,实现了模块化的样式处理,确保样式的作用范围仅限于组件内部。还支持全局样式和styled-jsx,开发者可以使用 styled-jsx 或引入 styled-components 等库,来实现组件级别的样式隔离和动态样式生成,适合开发复杂应用时的样式管理。 |
| 性能优化 | 代码分割与懒加载 | Next.is 提供了自动的代码分割功能,每个页面只加载当前所需的 JS 代码,避免了不必要的资源加载。同时,支持对组件进行懒加载,通过 React.lazy 和 Suspense 实现按需加载,提高页面渲染速度,减少初始加载时间,适合大型应用的性能优化。 |
| 国际化支持 | 内置国际化与区域化支持 | Next.is 原生支持国际化,通过 i18n配置可以轻松实现多语言网站开发。支持基于 URL 的语言切换和动态加载不同语言包,同时也提供了区域化设置(如日期、货币格式等)的自动处理,适合需要面向全球用户的应用。 |
| 开发体验 | Fast Refresh 与实时热更新与自动编译 | Next.js 提供了优秀的开发体验,Fast Refresh 功能支持组件修改后秒级热更新,在保存文件无需手动刷新页面,保证开发效率。实时热更新会在不中断状态的情况下处理组件自身的状态,帮助开发者专注于高效开发。 |
| API 路由与数据库集成 | Prisma, Mongoose, TypeORM 等数据库集成 | Next.js 支持与多种数据库 0RM 集成,如 Prisma、Mongoose、TypeORM,开发者可以通过 API 路由直接与数据库交互,实现数据存储与管理。Prisma 提供了强大的类型安全查询生成器,适合大型应用的复杂数据操作,而 Mongoose和 TypeORM 则更适合中小型项目。 |
| 静态文件处理 | public 目录与静态资源管理 | Next.is 的 public 目录用于存放静态文件,如图像、字体、视频等,任何位于 public 目录的文件都可以通过根路径直接访问。静态资源会被高效缓存,并支持 CDN 加速,提升全站的静态资源加载性能。 |
| SEO 优化 | Meta 标签管理, 动态 Head, 动态路由 SEO | Next.is 支持通过 next/head 组件动态管理页面的 <head>元素,实现灵活的 Meta 标签管理。可以根据不同页面动态设置标题、描述、关键词等 SE0 关键内容。对于动态路由页面,Next.js 通过 SSR 生成完整的 HTML 内容,确保搜索引擎能够抓取到最新的页面内容,提高 SE0 效果。 |
| TypeScript 支持 | TypeScript 与类型安全 | Next.js 原生支持 TypeScript,开发者可以在项目中使用 TypeScript 实现类型检查,避免运行时错误。结合React 的类型系统,Next.js 项目中的组件、API 路由和数据获取函数都能获得强大的类型提示与自动补全,提升开发效率和代码质量。 |
| SSR 与 CSR 混合模式 | SSR, CSR, SSG 的混合使用 | Next.js 允许开发者在同一个应用中灵活使用 SSR、CSR(客户端澶染)和 SSG,适合复杂的业务场景。通常首页使用SSG 或 ISR 提高性能,动态页面使用 SSR 确保内容实时更新,某些交互页面则可以使用 CSR 以提升用户体验。 |
| 错误边界与监控 | Error Boundaries 与 Sentry 集成 | 通过 React 的 Error Boundary,Next.is 提供了对应用错误的捕获与处理,确保在渲染过程中发生错误时不会导致整个应用崩溃。同时可以集成 Sentry 进行前后端的错误监控和性能跟踪,方便开发者对应用问题进行实时监控和调试。 |
| 安全与性能优化 | Helmet, HTTPS, 内容安全策略 (CSP) | Next.is 支持通过 next-helmet 或 next-secure-headers 插件设置 HTTP 头部,添加安全相关的内容安全策略(CSP)、强制 HTTPS 和其他安全策略,防止常见的 Web 安全攻击,如 XSS、CSRF 攻击等。结合现代 Web 性能优化技术,Next.js 也能很好地处理资源缓存和懒加载,提升网站加载速度。 |
| 部署与扩展 | Vercel 部署与 CI/CD 集成 | Next.js 是由 Vercel 团队开发,具有与 Vercel 平台的深度集成,支持一键部署至 Vercel,同时自动实现CI/CD 流程。每次提交代码后,Vercel 会自动构建并部署最新版本的应用。还支持通过 Docker、自托管等方式部署,适合多种部署需求 |
| 模块化与微前端架构 | Module Federation 与微前端架构支持 | Next.is 支持 Webpack 的 Module Federation 特性,能够轻松实现微前端架构,支持多个应用之间的模块共享。 通过微前端架构,开发者可以将不同功能模块独立部署和更新,提升应用的可维护性和扩展性,适合大型企业级应用。 |
| 前端与后端集成 | 全栈开发与 Serverless 函数 | Next.js 支持构建全栈应用,提供了内置的 API 路由,用于处理服务器端逻辑、数据库操作等。同时与 VercelServerless 函数无缝集成、能够将 API路由部署为无服务器函数、按需调用,大幅提升应用的可扩展性和灵活性,降低服务器负载。 |
1. 水合技术
SSR(服务器端渲染)和 CSR(客户端渲染)结合的关键部分,主要解决了服务端染(SSR)后页面静态 HTML 在浏览器加载后重新与 React 组件树关联,使页面具备动态交互能力。
2. 水合源码
| 模块 | 描述 | 源码解析 | 中文注释 |
|---|---|---|---|
| 服务端渲染 (SSR) | Next.js 通过 SSR 生成静态 HTML 页面,并注入预渲染的数据。 | getServerSideProps 和 getStaticProps 用于获取数据并注入到渲染的 HTML 中,通过renderToString 或 renderToStaticMarkup 方法生成静态 HTML。 | 在 SSR 阶段,Next.js 会生成 HTML,并将数据注入其中,供客户端渲染时使用。 |
| 客户端水合 (Hydration) | 在客户端接收到 SSR 生成的 HTML 后,Next.js 使用 React 的 hydrate() 将组件挂载到已有的 DOM 结构上。 | ReactDOM.hydrate 是水合的核心,通过复用现有的 DOM 而不是重新生成它,React 会将静态 HTML 转换为动态页面。 | 客户端接收到 HTML 后,React 会复用已有的 DOM,而不是重新渲染,提升性能。 |
| 虚拟 DOM 对比 | React 会将内存中的虚拟 DOM 树与 SSR 生成的 HTML 进行对比,并确定哪些需要更新。 | React 通过虚拟 DOM 的 reconciliation(协调)算法,逐步比较虚拟 DOM 和真实 DOM,找到需要更新的部分,避免无效的 DOM 操作。 | 通过虚拟 DOM 比对,React 可以在不重新生成整个 DOM 的情况下实现更新,提升渲染效率。 |
| 事件绑定 | 在水合过程中,React 会为现有的 DOM 绑定事件处理器,使其具备动态交互能力。 | 在 hydrate 过程中,React 会为 HTML 元素绑定事件侦听器(如 onClick, onChange),使其页面可用与 React 组件交互。 | 在水合后,静态的 HTML 页面会变为可交互的 React 组件。 |
| 数据注入 | SSR 生成的数据通过注入 __NEXT_DATA__,以便于客户端复用数据。 | 在生成的 HTML 中,Next.js 会通过 <script id="__NEXT_DATA__" type="application/json"> 注入 JSON 数据到页面中,客户端通过 window.__NEXT_DATA__ 获取数据并进行渲染。 | 服务端渲染生成的预渲染数据会被注入到页面,便于客户端渲染时可以直接复用这些数据,避免二次数据请求。 |
| 水合不匹配问题 | 如果 SSR 和 CSR 渲染结果不一致,会导致水合失败,页面可能会抖动或重新渲染。 | React 在水合过程中会比对 D0M,如果发现 SSR 生成的 HTML 与 CSR渲染的虚拟 D0M 不一致,会抛出警告并重新渲染不匹配的部分。 | 如果 SSR 和 CSR 渲染逻辑不一致,会导致页面抖动或性能损失。确保两者数据源一致是关键。 |
| 性能优化 | 使用动态加载和分片水合,减少初次渲染时的JavaScript 文件大小。 | Next.js 支持通过 next/dynamic 进行组件的懒加载,只有在需要时加载对应组件,减少初次水合的负担。分片水合将页面分成多个部分逐步加载,避免一次性加载所有内容。 | 动态加载和分片水合可以减少初始渲染的 JavaScript 体积,提高首屏渲染速度,适合大型应用的性能优化。 |
9. Vue
1. Vue2和Vue3区别
| 区别点 | Vue 2 | Vue 3 |
|---|---|---|
| 1. 响应式系统 | 1. 基于 Object.defineProperty 实现,只能拦截对象现有属性的读写操作。 2. 无法监听对象属性的新增、删除以及数组索引和长度的变化。 3. 对于深度嵌套的对象,响应性能较差,特别是在大型数据结构上有瓶颈。 | 1. 基于 Proxy 实现,全面支持 对象动态属性的新增、删除、数组索引和长度变化等,极大提升了灵活性。 2. 通过深度响应优化,代理整个对象结构,提升处理复杂嵌套对象的性能,适用于大型复杂应用。 |
| 2. 编译性能与体积优化 | 1. 编译与运行时繁耦合,导致打包体积较大,应用规模越大体积增长越明显。 2. 在大量数据和深层嵌套对象的处理上,性能有所下降。 | 1. 支持 Tree-shaking,未使用的代码会被自动移除,极大减少打包体积。 2. 基于 Proxy 的响应式系统和优化的 Virtual DOM,带来显著的性能提升,特别是对大型和复杂数据的处理。 |
| 3. 组合式 API | 1. 使用 Options API,逻辑分散在多个选项中,如 data、methods、computed,复用性较差,复杂组件的可维护性较低。 | 1. 引入 Composition API,通过函数组合逻辑,增强代码复用性,可以更好地组织复杂逻辑,尤其适用于复杂的组件开发和状态管理。 |
| 4. 异步组件与 Suspense | 1. 通过 Vue.component() 实现异步组件加载,缺少加载过程中的状态管理和错误处理。 | 1. 支持 Suspense,使得异步组件加载时可以处理加载、过渡和错误状态,提升用户体验,特别是在处理复杂异步流程时更加灵活。 |
| 5. Fragment和 Teleport | 1. 模板结构必须有一个根节点,多根节点需要额外包裹一个父节点,增加了模板的复杂性。 | 1. 支持 Fragment,允许多个根节点存在,减少了不必要的 DOM 节点包裹,简化了模板结构。 2. 引入 Teleport,可以将组件的 DOM 结构渲染到指定的外部位置,简化弹窗、模态框等的实现。 |
| 6. 自定义渲染器 | 1. 自定义渲染器支持有限,通常需要较多的底层操作,开发成本较高。 | 1. 提供更灵活的 Custom Renderer API,允许开发者针对非 DOM 平台(如 Websi、原生移动应用、终端)实现自定义渲染器,极大增强了 Vue 的适用范围和灵活性。 |
| 7. v-model改进 | 1. v-model 只能绑定单一数据源,且默认只能用于单个 prop 和 event。 | 1. 支持 多个 v-model,开发者可以为不同的 prop 自定义绑定事件和属性,增强了灵活性,特别是在复杂表单场景中更加高效。 |
| 8. 全局 API 调整 | 1. 全局 API 通过 Vue 实例方法调用,限制了多实例应用的场景,无法在多个 Vue 应用中共享全局配置。 | 1. 全局 API 通过应用实例调用,如 app.component,允许多个应用实例共享配置,支持多实例模式,提升了应用的可扩展性。 |
| 9. TypeScript支持 | 1. 提供 有限的 TypeScript 支持,类型堆栈和类型检查不够全面,大型项目中需要手动定义复杂的类型。 | 1. 原生支持 TypeScript,拥有更强的类型堆栈和类型检查能力,大幅提升了开发体验,开发者可以无缝使用 TypeScript 开发大型 Vue 应用,确保代码健壮性。 |
2. Vue2和Vue3 diff算法区别
| 特性 | Vue 2 diff 算法 | Vue 3 diff 算法 |
|---|---|---|
| 依赖 key 的优化 | Vue 2 依赖于 key 来提升 diff 性能。未设置 key 时,Vue 会默认使用默认顺序比较,这会导致低效的节点移动、删除和插入操作,尤其在复杂列表场景下,效率较低。 | Vue 3 更依赖 key,在保留原有 key 优化的基础上引入了 LIS(Longest Increasing Subsequence)算法,用以在列表更新时进行最小化 D0M 操作。key 的使用不仅能提升节点的准确对比,还能避免不必要的 DOM 重建,提升性能。 |
| 双端比较策略 | Vue 2 使用四种方式进行双端比较:头-头、尾-尾、尾-头、头-尾。这种比较方式虽然能提高某些场景下的性能,但在长列表中依然存在性能瓶颈,尤其是当需要频繁移动节点时,效率较低。 | Vue 3 保留了双端比较策略,但结合了 LIS 算法进行优化。当列表发生变化时,Vve 3 会通过双端比较迅速确定需要更新的范围,并通过LIS 找出最小的移动路径,减少不必要的节点操作。这种优化极大提升了节点移动效率,尤其在复杂列表场景下。 |
| 长列表性能 | 在长列表渲染和更新中,Vue 2 的表现较为一般。尤其当列表设置 key 或 key 设置不当时,Vue 2 可能执行许多冗余操作和移动操作,导致页面更新时产生明显的性能问题。 | Vue 3 针对长列表场景进行了专门优化。通过引入 LIS 算法,Vue 3能在长列表中准确找出需要移动的最小节点序列,避免了冗余的节点操作,显著提升了长列表的渲染和更新性能。特别是在大型应用场景中,Vue 3 的长列表处理能力显著优于 Vue 2。 |
| DOM 操作最小化 | Vue 2 的 DOM 更新机制相对较为直接,节点复用和更新逻辑较简单。更新时可能会触发较多次 DOM 移动,这在重复重建、拆分等复杂 DOM 操作中,效率较低。 | Vue 3 在 DOM 操作上更加智能化。通过 LIS 算法,Vue 3 能够识别出需要最少移动的节点序列,并通过最小的 DOM 操作完成视图更新,减少了 DOM 重绘和回流的频率,极大提升了整体性能,尤其在复杂场景下表现优异。 |
| 深层递归遍历 | Vue 2 的 diff 算法会对每个子节点进行全量递归遍历,这意味着每次更新时,即便只发生了局部变化,Vue 2 依然会遍历所有子节点,从而降低了性能。 | Vue 3 的 diff 算法更加灵活。它在进行深层递归时会根据实际情况跳过不必要的比较操作,减少了对无关节点的递归遍历,进一步提升了性能。这种灵活的优化方式在深度嵌套的组件结构中尤为显著,避免了Vue 2 全量递归导致的性能瓶颈, |
| 性能表现 | Vve 2 在普通场景下性能表现良好,但在处理大量数据、复杂组件结构和长列表时性能表现较弱,尤其是节点频繁插入、删除或移动的场景。 | Vue 3 在复杂场景下的性能表现明显优于 Vue 2。得益于 LIS 算法的引入,以及对 D0M 操作的最小化策略,Vue3尤其在处理长列表、大型数据更新和复杂的递归组件结构时,性能大幅提升,减少了不必要的计算和操作。 |
3. nextTick
| 项 | 解释 |
|---|---|
| 1. 核心原理 | Vue 的 DOM 更新采用异步批量处理机制: 1. 数据变化时,Vue 不会立即更新 DOM,而是将更新任务加入队列 2. 在事件循环结束时统一执行批量更新,避免频繁 DOM 操作提升性能 |
| 2. 执行机制 | 浏览器事件循环顺序: 1. 同步任务 → 2. 微任务(Promise.then) → 3. 宏任务(setTimeout) Vue nextTick 优先级: 1. Promise.then(现代浏览器) 2. MutationObserver(兼容方案) 3. setImmediate(IE) 4. setTimeout(兜底方案) → 确保 DOM 更新完成后立即执行回调 |
| 3. 实现流程 | 1. 数据变更:触发虚拟 DOM 更新,暂不提交到真实 DOM 2. 队列缓存:将 DOM 更新任务存入异步队列 3. 批量更新:事件循环结束时执行队列中所有 DOM 更新 4. 回调执行:通过 nextTick 注册的回调在更新完成后触发,保证获取最新 DOM 状态 |
| 4. 关键总结 | 1. DOM 更新异步化:基于浏览器事件循环实现批量处理 2. 微任务优先:通过 Promise/MutationObserver 确保及时性 3. 状态一致性:nextTick 是访问更新后 DOM 的标准方式 |
4. ref和reactive区别
| 特性 | ref实现原理 | reactive实现原理 |
|---|---|---|
| 响应式机制 | 基于对象的 .value 属性进⾏依赖追踪和更新 | 基于 Proxy 代理对象,递归地使所有属性响应式 |
| ⽤途 | 主要⽤于基本类型的响应式数据,也可⽤于包装对象 | 主要⽤于对象和数组的响应式处理,适⽤于深层嵌套的数据结构 |
| 依赖追踪 | 只追踪 .value 的访问和修改 | 通过 Proxy ⾃动拦截 get 和 set 操作,追踪对象所有属性的访问和修改 |
| 访问⽅式 | 必须通过 .value 来访问基本类型或包装的对象 | 直接访问对象或数组中的属性,⽆需通过 .value |
| 深度响应式 | 不⽀持,只能包装单个值或浅层对象,内部属性不会变为响应式 | ⽀持,⾃动递归处理所有嵌套的对象属性,内部属性也是响应式 |
总结ref:适⽤于基本类型数据或需要通过 .value 显式访问的对象;对基本类型进⾏响应式处理,使⽤简单且直观。 reactive :适⽤于对象和数组,会将所有嵌套的属性变为响应式,适合处理复杂的嵌套数据结构。 在实际项⽬中,有时我们需要混合使⽤ ref 和 reactive。例如,将⼀个复杂对象作为响应式数据,并且使⽤ ref 来处理基本类型或引 ⽤类型的某些特殊属性。
5. v-model实现原理
Vue 2:依赖于input事件和value的语法糖。 Vue 3:使⽤ modelValue 和 update:modelValue实现双向绑定。
6. v-if 和 v-for优先级
Vue2 中 vfor优先级⾼于vif vue3中相反
7. Vue组件通信
| 通信方式 | 描述 | 应用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| props(父 $ 子) | 父组件通过 props 将数据传递给子组件,是最基础的单向数据流方式,Vue3 支持 defineProps 简化使用。 | 父组件向子组件传递静态或动态数据,适用于组件内较为简单的数据传递场景。 | 简单直观,符合单向数据流设计理念,易于调试和维护。 | 子组件无法直接修改 props,复杂数据需要频繁的 props 传递,且深层组件嵌套传递困难。 |
| 自定义事件 $emit(子 $ 父) | 子组件通过 $emit 向父组件发送事件,父组件通过事件监听响应。Vue3 提供 defineEmits 支持更强的类型检查和简化写法。 | 子组件需要通知父组件一些交互操作的结果(如表单提交、按钮点击)。 | 数据流向明确,事件通信方式符合 Vue 的设计理念,降低耦合性,Vue3 中通过组合 API 进一步简化了代码。 | 仅限于父子组件通信,不适合兄弟组件或跨层级组件。 |
| v-model 双向绑定 | Vue3 中支持多个 vmodel,可同时双向绑定多个数据,通过简化代码来提高开发效率。 | 父组件需要直接操作子组件的数据时,如表单、用户输入,适用于表单或动态内容的双向数据绑定场景。 | 双向数据绑定简洁易用,适用于频繁需要父子组件同步数据的场景。 | 在复杂应用中可能造成数据流难以追踪,影响代码可维护性,不符合单向数据流的最佳实践。 |
| provide/inject | Vue 通过 provide 和 inject 跨组件层级传递数据,可有效避免层层 props 传递。Vue3 通过 ref 使其与响应式系统紧密结合。 | 跨越多层组件传递数据,如主题、全局配置、插件等。适用于祖先和深层嵌套的子组件间需要共享状态的场景。 | 避免了深层嵌套组件的 props drilling,代码简洁,Vue3 中的响应式支持增强了其灵活性。 | 数据源不直观,依赖隐式关系,容易产生组件间的强耦合,适用场景受限于祖先和后代组件。 |
| 全局事件总线(EventBus) | 通过一个中央事件管理系统(如 Vue2 中的 $bus 或 Vue3 中的外部事件库如 Mitt),各组件通过发布 / 订阅模式进行通信。 | 跨组件层级通信,特别是兄弟组件之间通信。适用于无父子关系的兄弟组件间需要直接通信的场景。 | 解耦组件,任何组件间都可通过事件进行通信,使用方便,灵活性高,Vue3 可结合 Mitt 等库进行管理。 | 随着项目变大,事件管理容易混乱,难以调试和维护,事件传递路径不直观,可能导致性能问题。 |
| Vuex(状态管理) | Vuex 是 Vue 的集中式状态管理工具,适合管理复杂的全局状态,Vue3 中与组合式 API 结合更紧密,支持模块化和插件化管理。 | 中大型项目的全局状态管理,多组件共享复杂数据,如购物车、用户登录状态等。 | 全局状态集中管理,数据流向清晰,可维护性和调试性强,Vue3 中的组合 API 支持增强了状态的模块化和封装性。 | 简单项目中显得过于复杂,代码量大,学习成本高,不适合小型项目,状态管理需要设计得当,否则可能导致性能问题。 |
| refs 和 parent | 通过 refs 引用组件或 DOM 元素实例,parent 访问父组件实例,可直接调用组件内部方法。 | 需要直接操作子组件或 DOM 元素时,如获取表单数据、触发子组件方法。 | 直接操作组件实例,能访问内部方法和属性,适用于需要手动控制 DOM 操作或访问子组件特定方法的场景。 | 破坏了组件封装性,容易导致组件间强耦合,不符合 Vue 的数据驱动理念,可能导致维护困难。 |
| attrs 和 listeners | Vue3 通过 v-bind="和listeners" 将父组件的未声明 props 和事件传递给子组件,适用于封装通用组件。 | 封装通用组件时,允许传递未知属性和事件给子组件,如构建 UI 库时。 | 灵活性高,允许动态控制子组件接收到的 props 和事件,适用于构建高可复用的通用组件。 | 使用场景较为有限,通常用于 UI 库或高度通用化的组件封装,项目中滥用可能增加复杂度。 |
| Pinia(Vue3 状态管理) | Vue3 官方推荐的轻量级状态管理工具 Pinia,支持 TypeScript,模块化设计和热重载,Vuex 的替代品。 | 中大型项目的全局状态管理,尤其是希望在 Vue3 中使用组合式 API 和 TypeScript 的场景。 | 更轻量且简单,支持组合式 API 和热重载,结构清晰,灵活性强,适合 Vue3 的生态和开发模式。 | 需要学习和引入新工具,某些场景下与 Vuex 类似,简单项目中可能显得复杂。 |
| localStorage/sessionStorage | 使用浏览器的本地存储,将数据存储在 localStorage 或 sessionStorage 中,适合不同页面或组件间持久化数据的传递。 | 需要在组件之间跨页面保持数据持久性,如登录信息、主题设置等。 | 数据持久化,页面刷新后仍可保留状态,适用于跨页面通信。 | 不适用于需要实时更新的数据传递,且存储的容量有限,安全性需要考虑。 |
| 异步事件 emit + async/await | 结合 emit 和 async/await 处理异步通信,适合处理异步操作后通知父组件执行后续操作。 | 需要处理复杂的异步操作并在父子组件或兄弟组件间传递异步数据时。 | 更现代化的异步处理方式,使用简洁,代码可读性高,符合现代 JavaScript 的最佳实践。 | 异步流程复杂时需要额外的错误处理逻辑,需合理管理异步状态,避免回调地狱。 |
8. Vue2响应式原理
总结:
- 实现顺序:Vue 2 的响应式系统从数据的初始化( Object.defineProperty)开始,通过递归地遍历对象、依赖收集、数据变更通知和异 步更新等⼀系列步骤,确保数据变化时视图⾃动更新。
- 核⼼设计模式
- 观察者模式:Vue 通过数据与 Watcher 之间的依赖关系,确保数据变化时视图⾃动更新。
- 发布-订阅模式:通过 Dep 类和 Watcher 类的结合,实现了数据变化时通知所有依赖的组件进⾏更新。
- 队列模式:Vue 使⽤队列机制和异步更新来优化性能,避免频繁的同步渲染
| 序号 | 实现步骤 | 描述 | 源码解析 | 设计模式 |
|---|---|---|---|---|
| 1 | 初始化响应式系统 | Vue 2 在实例化时调用 observe 函数,将 data 对象转化为响应式对象。Vue 2 使用 Object.defineProperty 为每个对象的属性定义 getter 和 setter,从而追踪数据变化。 | Vue 2 中的 observe 函数会递归遍历 data 对象中的所有属性,并为每个属性通过 Object.defineProperty 设置 getter 和 setter。getter 用于依赖收集,setter 用于在数据变化时通知依赖进行更新。 | 观察者模式(Observer Pattern):通过为对象属性设置 getter 和 setter,使得 Vue 可以观察数据变化,自动通知视图更新。 |
| 2 | 依赖收集 | 当组件渲染时,Vue 会访问响应式数据,通过 getter 收集依赖,依赖收集会将当前的渲染 Watcher 与数据属性关联起来,后续当该属性变化时,Watcher 会被通知更新。 | 在 getter 中,Vue 会通过 Dep.target 获取当前的 Watcher,并将其添加到 Dep(依赖)中。Dep 是一个管理依赖的类,负责将属性和依赖它的 Watcher 关联起来,以便数据变化时触发依赖更新。 | 发布 - 订阅模式(Publish-Subscribe Pattern):响应式数据发布变化事件,Watcher 作为订阅者收集依赖并在数据变化时被触发。 |
| 3 | 创建 Watcher | 每个组件的渲染过程都由 Watcher 进行管理,它负责收集依赖并在数据变化时重新执行渲染逻辑。Watcher 通过 getter 收集依赖,并在依赖数据变化时执行更新函数(如组件重新渲染)。 | Watcher 在初始化时会将自身赋值给 Dep.target,然后执行组件渲染函数,从而触发依赖收集。Watcher 会监听所有被访问的响应式数据,并在数据更新时触发 update 方法,重新计算组件的渲染结果。 | 观察者模式(Observer Pattern):Watcher 作为观察者,依赖于响应式数据,数据变化时自动触发 Watcher 的更新操作。 |
| 4 | 数据变更通知(Setter) | 当响应式数据的属性发生变化时,setter 会被触发,setter 中通过 Dep 通知所有依赖该属性的 Watcher,从而触发视图更新。 | 在 setter 中,Vue 会调用 Dep.notify 来通知所有依赖该属性的 Watcher,这些 Watcher 会触发相应的回调函数,从而引发视图的重新渲染。Vue 2 的响应式系统通过同步执行 setter 实现数据变化的追踪。 | 发布订阅模式(PublishSubscribe Pattern):当数据变化时,Vue 通过 setter 通知订阅该数据的所有 Watcher,实现数据到视图的同步更新。 |
| 5 | 递归遍历对象(深度观察) | Vue 2 在初始化时会递归遍历 data 对象的每一个属性,并通过 Object.defineProperty 为所有嵌套属性设置 getter 和 setter。这种递归方式确保所有深层次的属性也能被观察到,缺点是对大型对象性能不佳。 | Vue 2 的 observe 函数会递归遍历对象中的所有嵌套属性,并对每个属性调用 defineReactive。defineReactive 是为对象属性定义 getter 和 setter 的核心函数,递归遍历会一次性将整个对象的所有属性都转化为响应式。 | 迭代器模式(Iterator Pattern):Vue 通过递归遍历的方式为每个属性设置响应式 getter 和 setter,从而实现深度观察和响应。 |
| 6 | 数组响应式实现 | Vue 2 无法直接拦截数组的索引变化,因此通过重写数组的 7 个变更方法(如 push、pop 等)来实现对数组的响应式处理。当数组通过这些方法修改时,Vue 会触发视图更新。 | Vue 2 在初始化时会检测到数据类型是数组,如果是数组,则会将数组的原型指向自定义的 Array.prototype,通过覆盖数组的 push、pop、shift、unshift、splice、sort 和 reverse 7 个方法,确保数组变更时触发响应式更新。 | 装饰器模式(Decorator Pattern):通过重写数组的原型方法,Vue 实现了对数组变更的响应式处理,确保数组在被修改时依然能够触发视图更新。 |
| 7 | 依赖触发与更新 | 数据变化时,依赖于该数据的 Watcher 会被通知,Watcher 会调用 update 方法进行组件重新渲染或更新。在 Vue 2 中,update 方法会同步执行,即数据变化后立即触发视图更新。 | 在 Dep.notify 中,所有依赖该属性的 Watcher 会被依次调用,Watcher 的 update 方法会同步调用。Vue 2 的响应式系统是同步触发的,数据一旦变化,立即执行更新逻辑。虽然简单直接,但可能导致性能问题,特别是在大量数据变更时。 | 观察者模式(Observer Pattern):数据变化后立即通知 Watcher 更新视图,保证数据与视图保持同步。同步更新的方式简单但可能导致性能开销。 |
| 8 | 异步队列与批量更新 | Vue 2 为了优化性能,避免多次重复渲染,提供了异步更新机制。Vue 2 在更新数据时会将所有的 Watcher 推入一个更新队列中,并在下个事件循环 “tick” 时批量执行这些更新,避免了频繁的同步渲染。 | Vue 2 使用 nextTick 和 queueWatcher 机制,确保所有的 Watcher 只会在同一个事件循环中更新一次。queueWatcher 将 Watcher 推入队列,nextTick 使用微任务或宏任务在下个事件循环中统执行更新,避免重复的视图渲染。 | 队列模式(Queue Pattern):将多次数据变化触发的更新操作放入队列,批量执行更新,避免多次重复渲染。通过异步任务 nextTick 实现批量更新,提升渲染性能。 |
| 9 | 计算属性与缓存 | Vue 2 的 computed 计算属性是基于 Watcher 实现的,它会缓存计算结果,只有在依赖的响应式数据变化时才会重新计算,避免了不必要的重复计算。 | computed 通过创建 Watcher 来追踪依赖的数据。当依赖数据发生变化时,Watcher 会触发重新计算并更新结果。如果依赖数据没有变化,则返回缓存的结果,避免了重复计算,提升性能。computed 的更新和视图更新是分离的,只在依赖变化时重新计算。 | 惰性计算模式(Lazy Evaluation Pattern):computed 通过缓存机制实现性能优化,只有在依赖变化时才会触发重新计算,减少了不必要的计算开销。 |
| 10 | $nextTick 实现异步更新 | Vue 2 使用 $nextTick 来确保在 DOM 更新完成后执行特定的回调函数。它利用了 JavaScript 的事件循环机制,通过 Promise、MutationObserver 或 setTimeout 来异步执行任务,以确保数据更新与 DOM 渲染同步。 | nextTick 利用了 JavaScript 事件循环中的微任务(Promise)或宏任务(setTimeout)来异步执行回调函数。当数据变化时,Vue 会在 DOM 更新完成后,调用 $nextTick 中注册的回调函数,确保回调在视图更新后执行。 | 异步模式(Asynchronous Pattern):通过 nextTick 将回调函数放入事件循环的下个微任务中,确保数据更新与 DOM 更新同步完成。异步执行可以避免频繁的同步操作导致的性能瓶颈。 |
| 11 | 响应式系统的限制 | Vue 2 的响应式系统在某些场景下有局限性,例如不能监听对象属性的添加和删除,数组的索引变动不会触发视图更新。Vue 2 通过 Vue.set 和 Vue.delete 提供了对这些场景的支持,尽管其并不是最优解决方案。 | Vue 2 无法检测对象属性的添加和删除,因为 Object.defineProperty 只能为已存在的属性定义 getter 和 setter。Vue 提供了 Vue.set 和 Vue.delete 来手动为新增属性或删除属性实现响应式追踪,但这些方法需要手动调用,不够灵活。 | 补丁模式(Patch Pattern):通过 Vue.set 和 Vue.delete 提供一种补丁机制,手动为新增或删除的属性设置响应式。虽然解决了部分问题,但这种方式需要额外的手动调用,体验不如 Vue 3 的 Proxy 方式 |
Vue3响应式原理
| 序号 | 实现步骤 | 描述 | 源码解析 | 设计模式 |
|---|---|---|---|---|
| 1 | 初始化响应式系统 | Vue 响应式系统在组件创建时通过 reactive 或 ref 函数初始化数据对象,将普通的 JavaScript 对象或基本数据类型转换为响应式对象。 | reactive 通过 Proxy 对对象进行代理, ref 则对基本类型包装并通过 value 进行访问。在 Vue 的内部实现中, reactive 会返回个代理对象,拦截对数据的访问和修改,而 ref 会返回个对象包装器,允许对基本类型数据的响应式追踪。 | 代理模式(Proxy Pattern):通过 Proxy 拦截对象的操作,实现数据的代理,增强普通对象的响应式特性。 |
| 2 | 依赖收集 | 当组件渲染时,Vue 自动跟踪被访问的响应式数据,并通过依赖收集系统将当前的 effect 记录为该数据的依赖,后续数据更新时会触发这些依赖的重新执行。 | track 函数在数据访问时被调用,它会将当前活动的 effect 存储到全局的 targetMap 中, targetMap 是个嵌套的 WeakMap,存储每个响应式对象的依赖关系。当依赖的属性被访问时, track 函数将对应的 effect 添加到依赖追踪列表中。 | 观察者模式(Observer Pattern):数据和视图之间建立起观察者关系,当数据变化时通知观察者(视图)更新,实现自动化的数据和视图同步。 |
| 3 | 注册副作用函数 (effect) | 每个组件的渲染过程都是个副作用函数( effect),这些函数依赖于响应式数据。当响应式数据发生变化时, effect 函数会被重新执行以更新视图。 | effect 函数在 Vue 中用于注册副作用(如渲染函数),它会在数据读取时自动跟踪依赖。当数据变化时, trigger 函数会找到依赖该数据的 effect 并重新执行,确保视图与数据保持同步。 effect 通过全局栈管理多个副作用的执行顺序。 | 命令模式(Command Pattern): effect 函数可以看作是种命令,当依赖数据变化时,系统会执行这些命令(副作用),使得视图与数据保持同步。 |
| 4 | 依赖追踪 | Vue 在访问响应式对象的属性时,通过 track 函数追踪依赖关系。它将依赖(即当前活动的 effect)与数据关联起来,后续数据变化时能够触发对应的依赖重新执行。 | track 函数内部维护了个全局的 targetMap,它存储了每个响应式对象的依赖关系。当读取某个响应式数据时, track 会将当前的 effect(副作用函数)存储到依赖表中。依赖追踪通过 WeakMap 实现,保证内存的高效使用和垃圾回收机制。 | 发布 - 订阅模式(Publish - Subscribe Pattern):当响应式对象的属性被访问时,Vue 将其视为发布者,并将当前活动的 effect 函数作为订阅者,维护依赖关系。 |
| 5 | 触发依赖更新 | 当响应式数据被修改时,Vue 会通过 trigger 函数通知所有依赖该数据的 effect,重新执行这些副作用函数,从而更新视图。 | trigger 函数在数据更新时被调用,它通过查找 targetMap 中的依赖列表,找到所有依赖该数据的 effect,并调用这些 effect 函数重新执行。触发依赖更新的操作是异步的,通过 scheduler 执行,以减少不必要的重复渲染。 | 观察者模式(Observer Pattern):当数据发生变化时,Vue 作为观察者系统,触发所有依赖于该数据的观察者函数( effect),使视图与数据保持同步更新。 |
| 6 | 懒代理与深层次响应式 | Vue 的 reactive 会对嵌套的对象属性进行懒代理,只有当嵌套属性被访问时才会递归地将其转化为响应式对象,避免一次性代理整个对象带来的性能开销。 | Vue 通过 Proxy 的 get 拦截器实现深层次的响应式追踪。当访问嵌套对象的属性时,Vue 会动态地将该属性转换为响应式对象并开始追踪依赖。这种懒代理机制避免了 Vue 2 中使用 Object.defineProperty 时的一次性深度递归,极大地提升了性能。 | 懒加载模式(Lazy Loading Pattern):Vue 使用懒代理的方式仅在访问嵌套对象时进行代理,减少不必要的代理操作,提高性能。 |
| 7 | 计算属性( computed) | computed 是基于其他响应式数据的计算结果,具有缓存特性,只有在依赖的数据发生变化时才会重新计算,否则返回上次计算的结果,避免不必要的重复计算。 | computed 通过 ComputedRefImpl 类实现,内部使用了 effect 函数来注册依赖,并通过 scheduler 进行调度,只有当依赖的响应式数据发生变化时, effect 才会重新计算结果。结果会被缓存,直到依赖数据再次发生变化时才会重新计算。 | 惰性计算模式(Lazy Evaluation Pattern): computed 通过缓存机制避免不必要的重复计算,只有当依赖数据变化时才会重新计算。 |
| 8 | 调度与批量更新 | Vue 在数据变化时并不会立即更新视图,而是通过调度器( scheduler)对多次更新操作进行合并,并在事件循环的下一个 “tick” 中批量执行所有更新操作,以提高性能。 | scheduler 负责管理异步更新任务,Vue 使用 queueJob 函数将更新任务推入队列,并在事件循环的下个阶段执行所有任务。Vue 使用 Promise 微任务或 setTimeout 宏任务调度更新队列,避免多次触发渲染和更新操作,从而提升应用的整体性能。 | 队列模式(Queue Pattern):Vue 使用调度器将多次更新操作合并到队列中,并在合适的时机批量执行更新,避免不必要的重复渲染,提高性能。 |
| 9 | 停止依赖追踪 (stop) | 在某些情况下,开发者可能希望停止某个响应式对象的依赖追踪。Vue 提供了 stop 函数来停止某个 effect 的依赖收集,从而避免后续的响应式更新。 | stop 函数会将指定的 effect 标记为非活动状态,并从依赖表中移除,确保该 effect 后续不再参与依赖追踪。此时该 effect 的重新执行和数据更新将被停止,但之前的响应式数据依然保留原有的追踪机制。 | 命令模式(Command Pattern): stop 函数类似于种命令,控制是否继续追踪响应式数据的依赖,当命令被执行后,停止对数据的追踪和更新 |
10. Vue3.5 新增特性
| 特性 | 详细描述 | 源码原理 | 优势 |
|---|---|---|---|
| defineModel | 简化⽗⼦组件之间的双向绑定语法,替代 v-model。 | Vue 内部通过将 props 和 emit 封装到⼀起,⾃动追踪 props 变化并同步到⼦组件,避免⼿动触发 emit ('update:modelValue')。 | 减少代码冗余,特别是在复杂表单场景下简化双向绑定逻辑。 |
| defineRender | 在组合式 API 中定义渲染函数,实现逻辑与渲染分离。 | defineRender 封装了渲染逻辑,使⽤ Vue.createVNode 创建虚拟 DOM 节点,并在 setup 中处理响应式数据,动态⽣成虚拟 DOM 树。 | 提供更灵活的渲染控制,适合复杂的动态渲染需求。 |
| Reactive Props | reactive 直接⽀持 props,避免使⽤ toRefs。 | Vue 内部通过 Proxy 对 props 进⾏代理操作,⾃动追踪依赖并在数据变化时触发组件更新。 | 简化复杂 props 的处理,减少 toRefs 的样板代码,提升代码可读性。 |
| vmemo | 缓存组件渲染结果,减少不必要的重复渲染。 | Vue 内部通过依赖追踪和 WeakMap 实现缓存机制,利⽤依赖变化决定是否复⽤缓存的渲染结果。 | 在复杂组件或列表渲染场景中提升性能,减少重复渲染开销。 |
| Suspense 增强 | ⽀持多个异步组件并发加载,增加加载状态和错误处理能⼒。 | Vue 在内部通过 Promise 链处理多个异步任务,创建 SuspenseBoundary 来追踪任务进度,并在所有任务完成后解除 Suspense 状态。 | 更流畅的异步组件加载体验,适⽤于并发请求场景。 |
| Vue Router 钩⼦增强 | 新增 onBeforeRouteLeave 和 onBeforeRouteUpdate 钩⼦,增强路由导航控制。 | Vue Router 内部通过 Promise 链控制路由钩⼦,允许组件在路由变化时通过 onBeforeRouteLeave 和 onBeforeRouteUpdate 控制导航流程,依赖 Promise 的结果决定是否中断或继续导航。 | 提供更细粒度的导航控制,特别适⽤于复杂路由跳转和状态管理的场景。 |
| 虚拟 DOM 优化 | 对静态节点提升和动态节点更新的性能优化,减少渲染开销。 | Vue 通过 static hoisting 将不需要更新的静态节点提升,减少 Diff 过程中的重复操作,并通过 Block Tree 优化动态节点的更新流程,显著减少渲染中的性能开销。 | 提升⼤型应⽤的性能,减少浏览器的 CPU 和内存开销 |
总结:
- **简化双向绑定:**通过 defineModel 和 reactive props,Vue 3.5 简化了⽗⼦组件之间的数据传递和状态管理。
- **渲染性能提升:**通过 v-memo 和虚拟 DOM 的优化,⼤⼤提升了渲染性能,尤其是复杂⻚⾯和列表渲染的场景。
- 异步加载优化: Suspense 的增强,使得开发者在处理多个并发异步请求时能够更加优雅,提升了⽤户体验。
- **路由控制增强:**Vue Router 的钩⼦增强,让路由跳转和组件卸载等操作更为灵活,适⽤于复杂的导航需求
Vue项目性能优化
| 序号 | 性能优化项 | 具体应用场景 | 深入优化措施及高亮内容 |
|---|---|---|---|
| 1 | 懒加载路由和组件 | 电商平台后台:多个页面和组件的初始加载时间过长。 | 1. 通过动态导入和路由懒加载,按需加载页面组件,避免不必要的全局加载。 2. Vue 2 中使用 import () 函数,Vue 3 中使用 defineAsyncComponent 实现动态加载,减少首屏资源占用,提升加载速度。 |
| 2 | 虚拟滚动优化长列表渲染 | 聊天应用:消息列表数据量⼤,滚动时页面卡顿。 | 1. 使用 vue-virtual-scroller 等虚拟滚动插件,仅渲染可见区域的列表项。 2. 这种方式减少了 DOM 元素的渲染和内存占用,提升了大量数据场景下的滚动和渲染性能。 |
| 3 | 事件防抖与节流 | 实时数据监控系统:页面需要频繁处理用户输入、滚动等事件,性能下降。 | 1. 使用 debounce 和 throttle 减少高频事件的触发次数,避免性能浪费。 2. 在 Vue 2 和 Vue 3 中均可通过 lodash 或原生方法实现,提升页面交互响应速度,减少不必要的计算开销。 |
| 4 | 图片懒加载 | 内容展示平台:页面包含大量高清图片,导致加载时间过长。 | 1. 使用 vuelazyload 实现图片懒加载,在图片进入视口时才进行加载。 2. 结合低分辨率占位图技术,优化用户首次加载体验,减少初始加载时间,尤其适用于图片密集的电商项目和内容展示平台。 |
| 5 | SSR(服务端渲染)与 CSR 结合 | 新闻平台或博客系统:页面首次渲染时间长,SEO 要求较高。 | 1. 使用 Nuxt.js 或 Vue SSR 提高首屏渲染速度,Vue 2 和 Vue 3 均可通过 SSR 提升 SEO 优化和页面性能。 2. CSR 用于后续页面切换和交互,提高整体性能和用户体验。 |
| 6 | 使用 v-if 代替 v-show | 表单系统:多个表单字段和组件动态显示,页面切换时性能下降。 | 1. 对于不频繁显示的组件使用 v-if,仅在需要时才渲染组件。 2. v-if 会在组件销毁时释放内存,而 v-show 只是隐藏元素,Vue 2 和 Vue 3 中都应优先使用 v-if 处理动态内容渲染,提高性能。 |
| 7 | 组件缓存(keep-alive) | 表单管理系统:用户在不同表单页之间频繁切换,页面重新加载导致性能下降。 | 1. 使用 keep-alive 缓存未被销毁的组件,避免表单页之间的重复渲染。 2. 这种缓存机制在表单切换时保持状态,Vue 2 和 Vue 3 中均可通过 keep-alive 提升性能和用户体验,减少不必要的页面加载。 |
| 8 | Vuex 状态管理的优化 | 社交平台:全局状态管理过度复杂,导致更新频繁时性能下降。 | 1. Vue 3 使用 reactive 实现轻量状态管理,Vue 2 中可以通过模块化优化 Vuex 结构。 2. Vuex 中使用懒加载和按需引入模块,减少全局状态的更新,优化全局状态管理的性能。 |
| 9 | 编译时静态提升与 Tree-shaking | 内容管理系统:页面静态内容多,动态部分少,但每次更新都影响性能。 | 1. Vue 3 通过编译时静态提升和 Tree-shaking 优化打包,剔除未使用的代码和模块。 2. 静态内容在编译时直接提升,减少运行时的计算开销,避免动态内容的重复渲染,提高渲染性能,尤其适用于静态页面多的场景。 |
| 10 | Reactivity 系统优化 | 数据驱动应用:大量数据依赖实时更新,性能容易受到影响。 | 1. Vue 3 使用 Proxy 替代 Vue 2 中的 Object.defineProperty 实现响应式数据追踪,性能更高效。 2. 响应式数据追踪更灵活,适合需要大量数据联动更新的复杂场景,避免了 Vue 2 中依赖过多带来的性能瓶颈。 |
| 11 | Teleport 优化 DOM 渲染 | 模态框组件:模态框等常驻 DOM 的元素会影响页面渲染效率。 | 1. Vue 3 的 Teleport 可以将模态框等组件挂载到 DOM 外部,减少主页⾯的 DOM 层级。 2. 这种方式避免了 DOM 结构复杂化,尤其适用于含有多个全局弹窗和模态框的后台系统或电商平台,提升页面渲染性能。 |
| 12 | watchEffect 替代 watch | 数据监控平台:频繁依赖数据的监听,watch 逻辑复杂且效率低。 | 1. Vue 3 的 watchEffect 可以自动收集依赖,简化依赖数据的追踪逻辑。 2. 这种机制在复杂的监控系统中减少了依赖手动声明的复杂性,提高了数据响应速度和代码可维护性,避免了冗余的依赖收集。 |
| 13 | Suspense 处理异步加载 | 电商平台:产品详情页面包含多个异步请求,加载时间长,用户体验差。 | 1. Vue 3 的 Suspense 组件能够优雅处理异步请求,在异步数据加载时提供加载提示。 2. 这种异步处理方式特别适合异步数据密集的场景,如产品页面,能够有效减少用户等待时间,提升用户体验。 |
| 14 | 动态组件按需 加载 | 综合管理系统:系统包含多个不常⽤ 的模块和组件,导致打包体积过⼤。 | 1. 通过 defineAsyncComponent 实现动态加载,仅在需要时加载 组件,减⼩⾸屏打包体积。 2. Vue 2 和 Vue 3 均可使⽤此技术,减少了资源消耗和加载时 间,提升了系统的灵活性和性能 |
12. Vue-Router4原理
以下是 Vue Router 的原理总结,按照实现顺序和前后关联的流程,从初始化到导航过程,深⼊源码级别的分析,以表格形式呈现:
| 序号 | 实现步骤 | 描述 | 源码解析 | 设计模式 |
|---|---|---|---|---|
| 1 | 创建路由实例 | 使用 createRouter 方法创建路由实例,传入路由配置 routes 和其他选项(如 mode、scrollBehavior 等),生成路由对象。 | 源码中,createRouter 函数初始化路由对象,主要包含 matcher(路由匹配器)和 history(历史管理器)。matcher 负责根据路径匹配路由,history 则管理导航历史记录。 | 工厂模式(Factory Pattern):通过工厂方法创建路由实例,封装路由匹配和历史管理的具体实现。 |
| 2 | 创建路由匹配器 | 路由匹配器由 createMatcher 创建,它将路由配置转换为路由记录,并通过 path-to-regexp 将路径转换为正则表达式,生成匹配函数,用于后续匹配用户访问的 URL。 | createMatcher 会递归处理路由配置数组,将每个路由转换为内部的路由记录,存储在 pathMap 中。每次导航时,都会调用匹配函数,根据用户请求的 URL 匹配合适的路由记录。 | 策略模式(Strategy Pattern):为不同的路径规则动态生成正则表达式,使用不同策略匹配用户请求的 URL。 |
| 3 | 初始化历史管理器 | 根据路由模式(history 或 hash),通过 createWebHistory 或 createWebHashHistory 创建历史管理器,负责监听 URL 的变化并控制路由切换。 | history 模式基于 HTML5 的 pushState 和 replaceState,hash 模式则通过监听 URL 中的 # 部分变化来实现。Vue Router 在内部使用 createWebHistory 或 createWebHashHistory 方法封装了浏览器原生的 History API。 | 适配器模式(Adapter Pattern):根据不同的环境,Vue Router 提供 history 和 hash 两种适配器,适配不同的导航策略。 |
| 4 | 注册路由导航守卫 | 在路由实例上注册全局导航守卫(如 beforeEach、beforeResolve),并在每次路由切换时依次执行这些守卫,用于在路由导航过程中进行权限检查、数据预加载等操作。 | 源码中,导航守卫通过 router.beforeEach、router.beforeResolve 等钩子函数进行注册,runGuardQueue 函数用于依次执行这些守卫。守卫函数可以是同步或异步,内部使用 Promise 链管理导航守卫的执行顺序,保证所有守卫执行完毕后才会进入目标路由。 | 职责链模式(Chain of Responsibility Pattern):导航守卫形成职责链,依次执行,直到某个守卫通过或阻止导航,所有守卫通过后导航才会完成。 |
| 5 | 监听 URL 变化 | 初始化完成后,路由开始监听 URL 的变化,基于当前的路由模式,history 模式使用 popstate 事件监听,hash 模式使用 hashchange 事件监听 URL 的变化,并触发路由匹配和导航。 | 在 history.pushState 和 replaceState 后,Vue Router 通过 window.addEventListener ('popstate') 监听浏览器的前进 / 后退事件。hash 模式则使用 window.addEventListener ('hashchange') 监听 URL 的 # 部分变化,触发导航更新。 | 观察者模式(Observer Pattern):通过监听 URL 的变化来通知路由系统触发路由更新,视图与 URL 保持同步。 |
| 6 | 路由匹配与导航确认 | 当 URL 发生变化时,路由实例调用路由匹配器,使用正则表达式匹配 URL,找到符合的路由记录。如果匹配成功,路由系统进入导航确认阶段,执行所有守卫。 | 路由匹配过程由 matcher.resolve 负责,它会根据当前的 URL 查找 pathMap 中的路由记录。如果找到匹配项,则生成新的 Route 对象,并将其传递给导航确认阶段,执行导航守卫。所有守卫通过后,才会更新路由状态并加载新的组件。 | 状态模式(State Pattern):导航过程包括多个阶段(路由匹配、守卫执行、路由确认等),每个阶段对应不同的状态,所有状态执行完毕后完成导航。 |
| 7 | 执行组件内守卫与异步组件加载 | 在全局守卫执行完毕后,Vue Router 会调用目标组件的路由守卫(如 beforeRouteEnter、beforeRouteUpdate 等),并异步加载目标组件(如果使用了路由懒加载)。如果组件守卫中存在异步操作,Vue Router 会等待这些操作完成后再进入目标路由。 | 源码中,beforeRouteEnter 等组件守卫通过 setupRouteGuard 函数注册,loadAsyncComponents 负责加载异步组件。Vue Router 会先加载组件,再执行组件的路由守卫,确保组件加载和守卫执行的顺序正确。如果守卫中包含异步逻辑,Vue Router 会等待其完成。 | 命令模式(Command Pattern):组件守卫类似于命令的执行,异步加载组件和执行守卫形成命令队列,按照顺序执行所有守卫和异步操作,确保流程的完整性和可控性。 |
| 8 | 导航成功与组件渲染 | 当所有守卫和异步操作都执行完毕后,导航被确认,Vue Router 会更新路由状态,并通知 Vue 组件重新渲染页面。此时,路由切换完成,目标组件被成功渲染到页面中。 | 源码中,confirmTransition 函数确认导航成功后,调用 routerView 组件的渲染函数,将目标组件渲染到页面中。Vue Router 还会触发全局的 afterEach 钩子函数,通知开发者路由切换完成。组件渲染通过 Vue 的虚拟 DOM 系统进行更新和渲染。 | 观察者模式(Observer Pattern):当路由状态变化时,Vue Router 通知 Vue 组件系统更新页面,保持视图与路由状态同步。 |
| 9 | 路由滚动行为处理 | 在导航完成并渲染页面后,Vue Router 会根据 scrollBehavior 配置执行页面滚动操作,如返回顶部或保持之前的滚动位置,确保路由切换时页面滚动行为符合预期。 | 源码中,scrollBehavior 函数会根据目标路由的 meta 信息或默认配置确定滚动行为,并调用 window.scrollTo 或 history.scrollRestoration 控制页面的滚动位置。开发者可以自定义 scrollBehavior 来实现更复杂的滚动行为控制。 | 策略模式(Strategy Pattern):根据不同的路由配置和导航场景动态选择合适的滚动策略,如返回顶部、保持滚动位置等。 |
| 10 | 异步路由更新与导航取消 | 如果在导航过程中用户再次触发导航,Vue Router 会取消当前未完成的导航,并重新执行新的导航操作,确保应用的路由状态与用户操作保持同步。如果当前导航未完成,但新的导航开始,Vue Router 会中断当前导航流程,执行新的导航。 | abortPendingNavigation 函数用于取消正在执行的导航,Vue Router 会检查当前是否有未完成的导航,如果用户发起了新的导航请求,Vue Router 会调用该函数中止当前导航,并重新开始新的导航流程,确保路由系统处于最新状态。 | 中断模式(Cancellation Pattern):在导航过程中,如果新的导航请求被触发,当前的导航操作会被中断,保证路由系统与用户操作保持同步 |
13. vuex4实现原理
总结:
- 实现顺序:Vuex 的核⼼实现包括初始化 state 、注册 getters、 mutations、 actions ,⽀持模块化管理和依赖追踪,同时提供了插 件系统和严格模式来增强状态管理的灵活性和安全性。
- 核⼼设计模式:
- 单例模式:Vuex 的 store 是全局唯⼀的,保证了应⽤状态的集中管理。
- 观察者模式:通过 Vue 的响应式系统,确保状态变化时⾃动通知依赖的组件更新。
- 命令模式: mutations 和 actions 将状态变更和异步逻辑封装为命令,确保状态的可控性。
- **组合模式:**通过模块化设计,Vuex 的状态管理可以进⾏模块的组合,简化⼤型应⽤中复杂状态的管理
| 序号 | 实现步骤 | 描述 | 源码解析 | 设计模式 |
|---|---|---|---|---|
| 1 | Vuex 初始化 | Vuex 在 Vue 应用初始化时通过 Vue.use(Vuex) 注册插件,注入 $store 实例到每个 Vue 组件中。Vuex.Store 是核心构造函数,它接受用户定义的 state、getters、mutations、actions。 | Vuex 在初始化时通过 install 方法将 $store 挂载到 Vue 原型上。Vuex.Store 构造函数负责初始化 state,并将 getters、mutations、actions 注册到对应的模块系统中,所有状态和逻辑集中管理。 | 单例模式(Singleton Pattern):Vuex 通过 Store 创建一个全局的状态管理对象,并在应用中通过注入的方式共享该状态对象。 |
| 2 | 定义状态 state | state 是 Vuex 的核心,所有应用的共享状态都保存在 state 中。Vuex 将 state 对象转换为响应式对象,Vue 组件可以通过 $store.state 来访问共享状态。 | Vuex 通过 Vue.observable 将 state 转化为响应式对象,借助 Vue 的响应式系统,当 state 发生变化时,所有依赖于该状态的组件会自动更新。每个模块的 state 会被注册到 rootState 中,模块化管理状态。 | 观察者模式(Observer Pattern):state 是 Vuex 的核心数据,通过 Vue 的响应式系统,保证数据变化时通知依赖该数据的组件进行更新。 |
| 3 | Getters 计算属性 | getters 是 Vuex 中的计算属性,允许对 state 中的数据进行派生和过滤。组件可以通过 this.$store.getters 访问这些派生数据,getters 具有缓存特性,只有当依赖的 state 变化时才会重新计算。 | getters 在初始化时被注册到 store.getters 对象中。Vuex 会为每个 getter 创建一个 computed 属性,并通过 Object.defineProperty 将其代理到 getters 对象中。依赖于 state 的 getter 会通过 Vue 的响应式系统追踪依赖。 | 惰性计算模式(Lazy Evaluation Pattern):getters 通过缓存机制,只有在依赖的状态变化时才会重新计算,减少不必要的计算。 |
| 4 | Mutations 修改状态 | Vuex 通过 mutations 进行同步状态的修改,所有的状态变更必须通过 mutations,确保状态变更的可追踪性。mutations 只能进行同步操作,组件可以通过 this.$store.commit 提交一个 mutation。 | mutations 在 store 中被注册为函数,调用 commit 方法时,Vuex 会根据 mutation 的类型调用对应的函数并传递参数。mutation 触发时会直接修改 state,并通过 Vue 的响应式系统触发依赖于该 state 的组件更新。 | 命令模式(Command Pattern):mutations 是修改状态的唯一方式,每个 mutation 就像一个命令,描述状态的变更过程,并且是同步执行的。 |
| 5 | Actions 异步操作 | actions 是 Vuex 中处理异步操作的方式,它通过 dispatch 方法触发,actions 可以包含异步逻辑,并且可以调用 mutations 来修改状态。组件可以通过 this.$store.dispatch 来触发一个 action。 | actions 是异步操作的入口,Vuex 在调用 dispatch 时,会异步执行对应的 action 函数,并传入 context(包含 commit、dispatch、state 等)。actions 可以包含异步操作,执行完成后通过 commit 调用 mutations 更新状态。 | 命令模式(Command Pattern):actions 负责处理异步任务,类似命令的调度,处理完成后通过 commit 修改状态。 |
| 6 | 模块化管理 | Vuex 支持通过模块化管理复杂的状态,每个模块拥有自己的 state、getters、mutations 和 actions,模块可以嵌套并注册到 store 的根模块中。 | store 的模块化通过递归注册实现,registerModule 函数会递归遍历每个模块,将模块的 state 合并到 rootState,并将 mutations、getters、actions 注册到全局的 store 中,模块间可以通过 namespaced 进行命名空间隔离。 | 组合模式(Composite Pattern):通过模块化设计,Vuex 的状态管理可以进行模块的组合,简化大型应用中复杂状态的管理。 |
| 7 | 依赖追踪与响应式更新 | Vuex 依赖 Vue 的响应式系统,所有的 state 变化都会自动触发视图的更新。当组件依赖 Vuex 的 state 时,Vue 会自动追踪这些依赖,并在状态变化时触发组件重新渲染。 | 由于 Vuex 直接使用了 Vue 的响应式系统,因此 state 通过 Vue.observable 变为响应式,依赖于该 state 的组件会在 state 变化时重新渲染。watch 和 subscribe 方法允许开发者监听状态变化,实现更复杂的响应式更新逻辑。 | 观察者模式(Observer Pattern):Vuex 的状态变化会自动触发依赖该状态的组件更新,确保视图与状态的同步。 |
| 8 | 插件系统 | Vuex 通过插件系统允许开发者对状态管理进行扩展。插件函数在 store 初始化时被调用,并可以监听 mutations 和 actions 的触发,插件可以用于状态的持久化、调试工具等。 | Vuex 插件通过传入 store 实例进行扩展,插件函数会在 store 初始化时被调用。通过 subscribe 方法可以监听 mutations 和 actions 的执行,插件可以通过这些钩子实现诸如本地存储、调试日志等功能。例如,Vuex 插件常用于持久化状态或调试工具。 | 装饰器模式(Decorator Pattern):Vuex 的插件系统允许在不修改核心逻辑的前提下为状态管理增加额外的功能,例如状态持久化、调试工具等。 |
| 9 | 严格模式与时间旅行调试 | Vuex 提供了严格模式,确保状态只能通过 mutations 修改,防止开发者直接修改 state。此外,Vuex 与 Vue Devtools 结合,支持时间旅行调试(time travel debugging),开发者可以查看和回溯状态的变更历史。 | 在严格模式下,Vuex 通过 watcher 监听 state 的修改,若非通过 mutations 修改,则抛出错误。Vuex 与 Vue Devtools 集成,通过插件拦截 mutations 并记录状态的变更历史,开发者可以通过时间旅行功能回溯或还原应用的状态。 | 代理模式(Proxy Pattern):严格模式下,Vuex 通过代理 state 的修改操作,确保状态变更只能通过 mutations,提高了状态管理的可靠性和可维护性。 |
| 10 | SSR 支持 | Vuex 支持服务端渲染(SSR),服务端的 state 会在渲染完成后序列化,并在客户端挂载时将 state 注入到客户端的 store 中,确保客户端和服务端的状态保持一致。 | Vuex 支持在服务端生成初始状态,并通过 store.replaceState 方法将服务端生成的状态同步到客户端。Vuex 的状态序列化和反序列化过程在服务端和客户端同步进行,确保页面的初始状态一致,避免 SSR 页面在客户端渲染时出现状态不一致的问题。 | 备忘录模式(Memento Pattern):通过状态的序列化和反序列化,Vuex 实现了服务端渲染时的状态保持,确保服务端和客户端的状态一致。 |
Nuxt.js服务端渲染
| 类别 | 核心知识点 | 详细说明 |
|---|---|---|
| 渲染模式 | 服务端渲染(SSR) | Nuxt.js 的核心特性之一是支持服务端渲染 (SSR)。通过 SSR,应用程序在服务器端渲染 HTML,并在客户端进行进一步的交互。相比客户端渲染 (CSR),SSR 可以提升 SEO 和首屏加载速度。适合需要高 SEO 优化和初始页面加载速度快的应用,如电商平台、博客等。 |
| 静态⽣成 | 静态生成 静态站点生成 (SSG) | Nuxt.js 提供了强大的静态站点生成功能,通过 nuxt generate 可以将应用预渲染为静态文件,并在部署时提供极快的页面加载体验。静态生成适合内容较为稳定的场景,例如博客、产品介绍等,Nuxt.js 在构建时生成 HTML,避免每次请求都进行服务器端渲染。 |
| 自动路由生成 | 文件系统路由 | Nuxt.js 基于文件系统自动生成路由,开发者无需手动配置路由。通过在 pages 目录下创建 .vue 文件即可生成对应的 URL 路由,支持动态路由和嵌套路由,同时也支持 Catchall 路由,用于处理复杂的多层级路径结构。 |
| 布局与页面管理 | 布局系统与视图管理 | Nuxt.js 提供了强大的布局系统,可以在 layouts 目录下定义全局布局,并通过页面级别的 layout 属性指定不同页面的布局。同时支持 default.vue 作为默认布局。通过 layout 属性可以轻松实现公共部分复用,尤其适合管理后台、门户网站等需要多层次视图管理的项目。 |
| 数据获取 | asyncData 与 fetch | Nuxt.js 提供了两种数据获取方式:asyncData 用于在页面渲染前获取数据并将其注入组件中,fetch 则用于获取数据后更新组件的状态。asyncData 支持 SSR,而 fetch 可在客户端和服务端通用,结合 Vuex 状态管理,适用于需要预渲染和动态交互的场景,提升用户体验和应用的性能。 |
| API 路由与服务端开发 | API 路由与服务端集成 | Nuxt.js 支持通过 serverMiddleware 配置服务端中间件处理 API 路由,并与 Express、Koa 等 Node.js 框架集成。可以将 API 集成在 Nuxt 应用中,实现前后端一体化开发。 ServerMiddleware 在 API 设计、身份验证、日志记录、代理等服务端逻辑处理上非常灵活,适合全栈应用开发。 |
| 插件与模块化扩展 | 插件系统与 Nuxt.js 模块化架构 | Nuxt.js 提供了灵活的插件系统,可以在应用启动时运行自定义代码,常用于引入第三方库或设置全局混入。同时,Nuxt.js 的模块化架构使其可扩展性极高,社区提供了丰富的模块,如 PWA、Google Analytics、Auth 等。模块化设计支持在 modules 配置中快速引入和集成功能,提升开发效率和应用功能。 |
| 国际化支持 | 内置国际化与本地化支持 | Nuxt.js 支持通过 nuxti18n 模块实现国际化,支持动态切换语言和区域化设置。基于 URL 或 Cookie 自动识别用户的语言偏好,并加载对应的语言包。结合静态生成功能,Nuxt.js 可以根据不同的语言预生成静态页面,适合需要多语言支持的全球化应用。 |
| SEO 优化 | 动态 Meta 管理与页面优化 | Nuxt.js 通过 head 属性可以动态管理每个页面的 <head> 元素,动态设置标题、描述、关键词等 SEO 相关的 Meta 标签。结合 SSR 和静态生成,Nuxt.js 提供了极佳的 SEO 优化效果。对于内容动态变化的页面,可以使用 asyncData 结合 API 进行动态数据渲染,确保搜索引擎抓取最新的内容。 |
| 性能优化 | 代码分割与懒加载 | Nuxt.js 通过自动代码分割功能优化性能,每个页面只加载当前所需的 JS 代码,避免了不必要的资源加载。同时,支持对组件和路由进行懒加载,通过 import() 函数动态加载组件和页面资源,提升初始加载速度。对于需要处理大量图像或视频的应用,Nuxt.js 提供了内置的 nuxt/image 模块用于图像优化。 |
| 状态管理 | Vuex 状态管理 | Nuxt.js 集成了 Vuex 作为状态管理解决方案,支持模块化管理全局状态。结合 nuxtServerInit 方法,可以在服务端初始化时获取全局数据并注入 Vuex 仓库,适合处理复杂的应用状态和多页面共享数据场景。 |
| 开发体验 | 热模块替换与自动编译 | Nuxt.js 提供了优秀的开发者体验,支持模块热替换(HMR),在保存文件后无需刷新页面,保持组件状态的持久性。同时,Nuxt.js 会自动编译并更新代码,结合 nuxt dev 实现实时反馈,提升开发效率。 |
| PWA 支持 | 渐进式 Web 应用(PWA)支持 | 通过 @nuxt/pwa 模块,Nuxt.js 支持将应用升级为 PWA,包括离线访问、缓存管理、推送通知等功能。PWA 提升了移动设备上的用户体验,允许用户在离线时继续使用应用,并通过 Service Worker 实现资源预缓存和性能优化,适合构建响应迅速且高效的移动 Web 应用。 |
| 静态资源管理 | static 与 assets 目录管理 | Nuxt.js 提供了 static 和 assets 两个目录用于管理静态资源。static 目录中的文件会直接映射到根目录,可以通过 /static 路径直接访问,而 assets 目录主要用于存放未编译的资源(如 SCSS、图片等),通过 webpack 处理后用于组件中。静态资源可以通过 CDN 加速,提升全站加载速度。 |
| 中间件与守卫 | 路由中间件与页面守卫 | Nuxt.js 支持全局和页面级别的中间件,通过 middleware 属性可以定义路由守卫,用于控制页面访问权限和验证用户身份。中间件在页面渲染前执行,适合身份验证、权限控制等逻辑。结合 Nuxt.js 的插件系统,可以实现灵活的身份验证与权限管理机制,常用于保护后台管理系统和用户隐私数据。 |
| TypeScript 支持 | TypeScript 原生支持与类型安全 | Nuxt.js 原生支持 TypeScript,开发者可以通过 @nuxt/typescript-build 模块启用 TypeScript,确保在开发过程中进行类型检查和错误提示,提升代码的可靠性和维护性。结合 Vuex 的类型支持,Nuxt.js 应用中的全局状态管理和 API 数据处理可以实现全面的类型安全。 |
| 部署与集成 | Vercel、Netlify 与 Docker 部署支持 | Nuxt.js 支持多种部署方式,可以通过 Vercel、Netlify 等平台实现一键部署,结合 CI/CD 自动化流程,简化部署操作。Nuxt.js 还支持通过 Docker 镜像进行自托管部署,适合需要更高安全性和定制化的生产环境。在生产模式下,Nuxt.js 会自动进行代码优化和性能调优,确保应用的高效运行。 |
| 安全性与 CSP 策略 | 内容安全策略(CSP)与防御 XSS 攻击 | Nuxt.js 提供了内置的安全设置,支持通过 @nuxtjs/helmet 模块设置内容安全策略(CSP),防止跨站脚本攻击(XSS)。可以强制所有资源通过 HTTPS 加载,并限制外部脚本的来源。结合 SSR,Nuxt.js 在页面渲染时可以有效防止注入攻击,确保用户数据的安全性,适合金融、医疗等对安全性要求较高的应用。 |
| SSG 与 SSR 混合渲染 | 静态生成与服务端渲染混合使用 | Nuxt.js 支持在同一应用中灵活使用 SSG(静态站点生成)与 SSR(服务端渲染)模式,开发者可以根据页面的需求选择合适的渲染方式。例如,首页可以使用静态生成提高加载速度,而某些动态页面则使用 SSR 保证数据的实时性,结合缓存策略最大化提升性能和 SEO。 |
| 缓存与性能优化 | 缓存策略与页面性能优化 | Nuxt.js 通过内置的缓存策略和懒加载机制优化页面性能。可以通过 cache-control 头部设置静态资源的缓存过期时间,并结合 CDN 实现全局加速。同时,支持使用 Webpack 的持久化缓存功能,减少每次编译时的打包时间。对于需要处理大量图像的应用,Nuxt.js 提供了 @nuxt/image 模块,支持自动图像优化和懒加载。 |
| SSR 性能优化 | 缓存和持久化服务端渲染 | Nuxt.js 在 SSR 模式下支持通过 nuxtServerInit 方法实现全局数据的预获取,并且可以通过 Redis、Memcached 等缓存方案对渲染结果进行缓存,减少服务端负载。同时,Nuxt.js 可以通过负载均衡和自动扩展服务器实例来支持高并发访问,适合电商、社交平台等高流量应用。 |
| 模块联邦与微前端架构 | Module Federation 与微前端支持 | Nuxt.js 支持通过 Webpack 的 Module Federation 实现微前端架构,支持多个应用共享模块。开发者可以将不同的功能模块独立开发和部署,并通过模块联邦实现动态加载和集成,适合大型应用的拆分与维护。结合 Nuxt.js 的模块化架构设计,可以在项目中逐步引入微前端技术,提升应用的扩展性和团队协作效率。 |
1. 水合技术
SSR(服务器端渲染)和 CSR(客户端渲染)结合的关键部分,主要解决了服务端渲染(SSR)后⻚⾯静态 HTML 在浏览器加载后重新与 React 组件树关联,使⻚⾯具备动态交互能⼒。
2. 水合原理
| 模块 | 描述 | 源码解析 | 中文注释 |
|---|---|---|---|
| 服务端渲染 (SSR) | Nuxt.js 通过 SSR 在服务器上生成静态 HTML 页面,并将其发送给客户端,注入预渲染的数据。 | Nuxt.js 通过 nuxtServerInit、getServerSideProps、getStaticProps 等 API 来在服务端获取数据,并将其传递给组件,生成静态 HTML。使用 vue-server-renderer 的 renderToString() 方法将 Vue 组件渲染为 HTML 字符串,并注入页面。 | 在 SSR 阶段,Nuxt.js 会生成 HTML 页面并注入数据,确保页面的首屏渲染快速完成。 |
| 客户端水合 (Hydration) | 在客户端接收到 SSR 生成的 HTML 后,Nuxt.js 使用 Vue 的 hydrate() 方法将服务端生成的 HTML 与 Vue 组件结合。 | 在客户端,Vue 会通过 hydrate() 方法复用 SSR 生成的 DOM 结构,并将其与 Vue 组件进行关联。此过程通过 Vue.$mount() 方法实现,Vue 组件挂载到已有的 DOM 上,而不重新渲染所有内容。 | Nuxt.js 使用 Vue 的水合机制,复用服务端渲染的 DOM,避免重新渲染,提高性能。 |
| 虚拟 DOM 对比 | Vue 通过虚拟 DOM 的 patch 机制,将内存中的虚拟 DOM 树与 SSR 生成的 HTML 进行对比,决定哪些部分需要更新。 | Vue 的 patch 函数会在客户端进行虚拟 DOM 与真实 DOM 的比对,确保数据的一致性。如果存在不一致部分,Vue 会仅更新需要修改的 DOM 节点,而不会重新渲染整个页面。 | 虚拟 DOM 对比确保客户端的 DOM 结构与服务端一致,避免重复渲染,提升渲染效率。 |
| 事件绑定 | 水合过程中,Vue 为 SSR 生成的 DOM 元素绑定事件处理器,实现页面的动态交互能力。 | 在水合过程中,Vue 会为每个现有的 DOM 节点绑定事件监听器(如 click、input 等),确保在水合完成后,页面具备完整的交互能力。事件绑定在客户端进行,因为服务端无法绑定事件。 | 事件绑定在水合过程中完成,使得页面从静态 HTML 转变为动态可交互的 Vue 应用。 |
| SSR 数据注入 | 服务端生成的数据通过 NUXT 变量注入到 HTML 中,供客户端渲染时复用,避免重复请求。 | 在生成的 HTML 中,Nuxt.js 会通过 <script> 标签注入 NUXT 全局变量,包含了服务端渲染的数据。客户端通过 window.NUXT 获取并使用这些数据进行水合,避免二次请求。 | 通过 NUXT 注入数据,确保客户端渲染时可以复用服务端的数据,提升渲染性能。 |
| 水合不匹配问题 | 如果 SSR 生成的 HTML 与客户端渲染的 Vue 组件不一致,水合可能会失败,导致页面重新渲染。 | 如果 SSR 和 CSR 的渲染结果不同,Vue 会抛出警告并重新渲染不一致的部分。为了避免这个问题,Nuxt.js 会确保服务端和客户端渲染使用相同的数据源和逻辑,以避免水合失败。 | 确保 SSR 和 CSR 数据一致是防止水合不匹配的关键。Nuxt.js 会优先复用 SSR 生成的 HTML,只有在内容不一致时才重新渲染。 |
| 性能优化 | 使用懒加载、分片水合等优化技术,减少初次渲染时的 JavaScript 大小和渲染负担。 | Nuxt.js 支持通过 dynamic import 进行组件的懒加载,避免加载所有组件,减少初次水合的 JavaScript 文件大小。同时支持分片水合,将页面划分为多个独立模块,逐步加载和水合,提升渲染性能,适用于大型页面或复杂应用。 | 通过懒加载和分片水合,减少初次渲染时的资源消耗,提升首屏加载速度,适合需要高性能的复杂应用。 |
15. uniapp实现原理
| 模块/步骤 | 源码级实现原理 | 实际应用场景 |
|---|---|---|
| 1. 平台适配 | 🔧 自定义编译器解析Vue代码 → 生成各平台模板(WXML/WXSS等) 🚀 适配器模式对接原生API | ✅ 跨端运行:一套代码输出微信/H5/iOS/Android 🚫 无需重复开发基础组件 |
| 2. 组件渲染 | 📦 Vue组件 → 编译为平台组件(小程序自定义组件等) ⚡ 虚拟DOM动态适配(H5保留/DOM映射优化) | 🔄 多端一致性:生命周期/属性/事件自动转换 💨 性能优化:智能选择最优渲染路径 |
| 3. 事件系统 | ⚡ 统一事件代理层: - @click → bindtap(小程序) - 跨平台事件冒泡/捕获机制同步 | 🖱️ 交互统一:开发者用Vue事件语法 📡 自动适配:屏蔽平台事件差异 |
| 4. 生命周期 | 🔄 生命周期映射器: - created → onLoad(小程序) - mounted → onReady | ⏳ 无缝衔接:Vue生命周期跨端执行 🔗 保持业务逻辑一致性 |
| 5. 样式处理 | 🎨 CSS多态编译器: - 小程序:CSS → WXSS(自动补全rpx) - H5:PostCSS优化 | 🖌️ 样式跨端:Flex布局自动适配 📱 响应式设计多端生效 |
| 6. 编译优化 | 🛠️ 条件编译: - #ifdef 指令 → 打包剔除无关代码 📦 智能打包: - 小程序分包/H5懒加载 | 🚀 性能提升: - 小程序主包≤2MB - H5首屏加载≤1s |
1. uniapp自定义编辑器原理
| 步骤 / 模块 | 源码级别实现原理 | 深入解释及应用场景 |
|---|---|---|
| 解析 Vue 文件 | 通过 Vue 编译器解析 .vue 文件,拆解出 template、script、style,并将 template 转换为平台无关的 AST。 | 将 Vue 的三大模块分离,生成中间抽象语法树(AST),为跨平台编译和适配打下基础。适用于不同平台的统一解析和初步转换。 |
| 生成 AST | 使用 Vue 编译器将模板编译成平台无关的 AST,表示模板的抽象结构,用于后续平台相关的优化与生成。 | AST 是代码的结构化抽象表示,编译器通过它为多平台构建提供通用基础,确保代码结构一致性。适用于复杂组件的跨平台转换。 |
| 组件转换 | 在 AST 基础上,将 Vue 组件转换为目标平台的等价组件,如小程序的 <view> 或 H5 的 <div>。 | 不同平台的组件实现存在差异,编译器将 Vue 组件转换为平台对应的实现形式,确保一致的跨平台组件逻辑。用于复杂 UI 组件的跨平台兼容处理。 |
| 生命周期转换 | 将 Vue 生命周期(如 created、mounted)转换为目标平台的生命周期方法(如小程序的 onLoad、onReady)。 | 统一开发体验,保证跨平台生命周期钩子的一致性,自动映射 Vue 的生命周期至不同平台的原生生命周期。适用于统一生命周期管理的复杂应用场景。 |
| 事件系统转换 | 解析 Vue 的事件绑定(如 @click ),并转换为目标平台的事件系统(如小程序的 bindtap ),确保跨平台的事件兼容性。 | 跨平台的事件绑定机制转换,保证不同平台的事件触发逻辑保持一致,减少平台特性差异对事件系统的影响。适用于高频交互的场景,如按钮、表单等操作。 |
| 样式处理 | 根据目标平台特性,将 Vue 的 style 部分转换为相应的样式语言,如小程序的 WXSS 或 H5 的标准 CSS,处理平台差异。 | 样式转换保障跨平台的一致视觉体验,不同平台根据自身样式系统(如 WXSS)进行编译,确保界面外观一致。适用于大型项目的多端样式统一。 |
| 条件编译 | 通过 #ifdef 等条件编译指令,根据目标平台选择性编译代码块,剔除非目标平台的代码,确保代码按需输出。 | 平台特定代码段的处理,编译器依据条件编译语法,保留目标平台特定代码,剔除无关代码。适用于多平台特定功能差异的项目场景。 |
| 生成平台代码 | 根据转换后的 AST,生成目标平台代码(如小程序的 WXML,H5 的 HTML),将其写入输出目录,供不同平台运行时使用。 | 编译器最终输出平台原生代码,确保 Vue 逻辑能无缝运行在各个平台中,适配小程序、H5、App 等多种平台环境。适用于跨平台交付项目。 |
| 打包与优化 | 根据平台特性进行打包优化,如小程序采用分包加载机制减少主包大小,H5 通过懒加载与按需加载提升初始加载速度和运行性能。 | 针对不同平台的性能优化,减少包体积与加载时间,确保各平台运行性能最佳。适用于需要高效加载和高性能表现的复杂应用场景。 |
2. Vue编译器解析
| 阶段 / 模块 | 实现原理 | 详细解释及应用场景 |
|---|---|---|
| 解析 | 使用 parse 函数将 Vue 模板解析为 AST,通过词法分析生成 Token 流,语法分析构建出抽象语法树(AST)。 | 解析模板结构,包括标签、属性、指令等,生成 AST 作为模板的抽象表示,适用于初始模板解析和组件树的构建。 |
| 词法分析 | 将模板字符串转化为 Token 流,识别出模板中的标签、属性、文本节点等。 | 将模板分解为最小的语言单元,便于后续语法分析,如识别出 <div> 、 id="app" 等结构。 |
| 语法分析 | 将 Token 流转换为 AST,构建模板的结构化表示,包括元素节点、文本节点、指令节点等。 | 构建出 Vue 模板的层次结构,AST 用于表示模板中的嵌套、属性、事件等信息,便于后续转换和优化。 |
| 优化 | 通过 markStatic 和 markStaticRoots 标记静态节点,避免不必要的重新渲染。 | 静态节点标记用于减少渲染时的计算,优化性能,适用于含有大量静态内容的场景,如静态文本、不会变化的组件等。 |
| 标记静态节点 | 递归遍历 AST,标记不会随着数据更新而变化的节点为静态节点。 | 静态节点可以在后续的渲染过程中跳过,避免重新渲染,提升渲染性能。 |
| 标记静态根节点 | 标记包含静态子树的根节点,静态根节点在渲染时可直接复用,减少虚拟 DOM 的计算开销。 | 静态根节点提升了整个子树的渲染效率,尤其在复杂的页面结构中,减少大量静态内容的重复渲染。 |
| 代码生成 | 使用 generate 函数将 AST 转换为渲染函数,生成可以执行的 JavaScript 渲染代码。 | 渲染函数用于生成虚拟 DOM,随着数据变化动态更新 DOM,适用于所有 Vue 模板的最终渲染流程。 |
| 渲染函数生成 | 根据 AST 生成包含虚拟 DOM 的渲染函数代码,如 c('div', {attrs: {"id":"app"}}, [_v(_s(message))])。 | 渲染函数是最终用于创建和更新 DOM 的代码,适用于 Vue 的虚拟 DOM 更新机制,确保数据变化时高效更新视图。 |
10. CSS && JavaScript
盒子模型和BFC
一、盒子模型与 BFC 对比
| 特性 | 盒子模型 (Box Model) | BFC (Block Formatting Context) |
|---|---|---|
| 定义 | 页面元素布局的基础模型,描述元素占用的空间结构 | 一种独立的渲染区域,内部布局规则与外部隔离的 CSS 机制 |
| 核心组成 | 由 content、padding、border、margin 四部分组成 | 触发 BFC 的元素及其子元素构成的独立区域 |
| 核心作用 | 控制元素尺寸计算(如 width 默认作用于 content 区域) | 解决布局问题(如外边距重叠、浮动元素环绕等) |
| 触发条件 | 无,所有元素默认遵循盒子模型 | 通过 CSS 属性触发(如 overflow: hidden、float、display: inline-block 等) |
| 典型问题 | 标准模型与 IE 模型的差异(box-sizing 属性控制) | 清除浮动、避免外边距合并、阻止元素被浮动覆盖 |
二、盒子模型类型对比
| 类型 | 标准盒子模型 | IE 盒子模型 |
|---|---|---|
| 计算方式 | width = content 宽度 | width = content + padding + border |
| 控制属性 | box-sizing: content-box(默认值) | box-sizing: border-box |
| 示意图 | content → padding → border → margin | border+padding+content → margin |
三、BFC 的常见触发方式
| 触发条件 | 示例代码 |
|---|---|
float 不为 none | float: left; |
position 为 absolute/fixed | position: absolute; |
display 为 inline-block | display: inline-block; |
overflow 不为 visible | overflow: hidden; |
根元素(<html>) | 无需设置 |
四、BFC 的典型应用场景
| 场景 | 作用 | 示例代码 |
|---|---|---|
| 避免外边距重叠(Margin Collapse) | 将相邻元素包裹在 BFC 容器中 | <div style="overflow: hidden;">...</div> |
| 清除浮动(Clear Float) | 触发 BFC 的容器会自动包含浮动子元素 | 父容器设置 overflow: hidden;`` |
| 阻止元素被浮动覆盖 | 非浮动元素触发 BFC 后不再环绕浮动元素 | 非浮动元素设置 overflow: auto;`` |
五、代码示例
<!-- 盒子模型示例 -->
<div style="width: 100px; padding: 10px; border: 2px solid black; margin: 20px; box-sizing: content-box;">
标准模型(总宽度 = 100 + 10*2 + 2*2 = 124px)
</div>
<!-- BFC 解决外边距重叠 -->
<div style="overflow: hidden;">
<div style="margin: 20px;">子元素 1</div>
<div style="margin: 20px;">子元素 2</div> <!-- 外边距不再合并 -->
</div>
CSS汇总
一、CSS 核心概念
| 概念 | 描述 | 相关属性/示例 |
|---|---|---|
| 盒子模型 | 元素布局的基础模型,包含 content、padding、border、margin 四层结构 | width, height, padding, border, margin, box-sizing |
| BFC | 块级格式化上下文,隔离布局环境,解决浮动、外边距重叠等问题 | overflow: hidden, display: flow-root, float, position: absolute |
| 层叠上下文 | 控制元素层级关系,决定元素覆盖顺序 | z-index, position: relative/absolute/fixed, opacity < 1, transform |
二、CSS 选择器
| 类型 | 语法 | 示例 | 说明 |
|---|---|---|---|
| 元素选择器 | element | div { ... } | 选择所有 <div> 元素 |
| 类选择器 | .class | .container { ... } | 选择所有 class="container" 元素 |
| ID 选择器 | #id | #header { ... } | 选择 id="header" 元素 |
| 后代选择器 | parent child | ul li { ... } | 选择 <ul> 内所有 <li> |
| 子元素选择器 | parent > child | .menu > .item { ... } | 选择直接子元素 |
| 伪类选择器 | :pseudo-class | a:hover { ... } | 鼠标悬停时的状态 |
| 伪元素选择器 | ::pseudo-element | p::first-line { ... } | 选择段落首行文本 |
| 属性选择器 | [attribute=value] | input[type="text"] { ... } | 选择特定属性值的元素 |
三、布局模型对比
| 布局模型 | 特点 | 核心属性 | 适用场景 |
|---|---|---|---|
| 普通流 | 默认布局方式,元素按 HTML 顺序从上到下排列 | display: block/inline | 基础文本/块级元素布局 |
| Flexbox | 一维弹性布局,通过主轴和交叉轴控制子元素对齐和分布 | display: flex, flex-direction, justify-content, align-items | 水平/垂直居中、等分空间 |
| Grid | 二维网格布局,精准控制行和列的分布 | display: grid, grid-template-columns/rows, grid-gap, grid-area | 复杂网格布局(如仪表盘) |
| 浮动布局 | 元素脱离文档流,其他元素环绕其排列 | float: left/right, clear: both | 图文混排、旧版多列布局 |
| 定位布局 | 通过绝对/相对定位精确控制元素位置 | position: relative/absolute/fixed, top, left, z-index | 弹出层、悬浮按钮、覆盖效果 |
四、常见问题与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 垂直居中困难 | 传统布局方式对垂直对齐支持不足 | 使用 Flexbox (align-items: center) 或 Grid (place-items: center) |
| 外边距重叠(Margin Collapse) | 相邻元素的外边距合并 | 触发 BFC(如父容器设置 overflow: hidden)或使用 padding 替代 |
| 浮动元素导致父容器高度塌陷 | 浮动元素脱离文档流,父容器无法计算高度 | 触发 BFC(如 overflow: auto)或使用伪元素清除浮动(::after { clear: both }) |
| 移动端 1px 边框模糊 | 高清屏设备物理像素与 CSS 像素差异 | 使用 transform: scale(0.5) 或媒体查询结合 border-image |
| 文本溢出显示省略号 | 内容过长超出容器 | css<br>.ellipsis {<br> overflow: hidden;<br> text-overflow: ellipsis;<br> white-space: nowrap;<br>} |
五、响应式设计核心
| 技术 | 作用 | 示例代码 |
|---|---|---|
| 媒体查询(Media Queries) | 根据设备特性应用不同样式 | @media (max-width: 768px) { ... } |
| 视口控制(Viewport) | 移动端适配基础 | <meta name="viewport" content="width=device-width, initial-scale=1.0"> |
| 相对单位 | 实现弹性布局 | rem(基于根字体大小)、vw/vh(视窗百分比)、%(父容器百分比) |
| 图片自适应 | 避免图片超出容器 | img { max-width: 100%; height: auto; } |
六、CSS 动画与过渡
| 特性 | 描述 | 核心属性 | 示例 |
|---|---|---|---|
| 过渡(Transition) | 平滑改变 CSS 属性值 | transition: property duration timing-function; | transition: all 0.3s ease-in; |
| 动画(Animation) | 定义复杂动画序列 | @keyframes, animation-name, animation-duration | css<br>@keyframes slide {<br> from { transform: translateX(-100%); }<br> to { transform: translateX(0); }<br>} |
七、实用代码片段
css
复制
/* 水平垂直居中(Flexbox) */
.center-flex {
display: flex;
justify-content: center;
align-items: center;
}
/* 水平垂直居中(Grid) */
.center-grid {
display: grid;
place-items: center;
}
/* 清除浮动 */
.clearfix::after {
content: "";
display: block;
clear: both;
}
/* 移动端适配 1px 边框 */
@media (-webkit-min-device-pixel-ratio: 2) {
.thin-border {
position: relative;
&::after {
content: "";
position: absolute;
left: 0;
top: 0;
width: 200%;
height: 200%;
border: 1px solid #000;
transform: scale(0.5);
transform-origin: 0 0;
}
}
}
八、高阶特性
| 特性 | 描述 | 应用场景 |
|---|---|---|
| CSS 变量(Custom Properties) | 定义可复用的样式变量 | 主题切换、统一管理颜色/尺寸 |
| 伪元素与内容生成 | 通过 ::before/::after 插入内容 | 图标、装饰性元素 |
| 混合模式(Blend Modes) | 控制元素叠加效果(如 mix-blend-mode) | 图片特效、文字与背景融合 |
| CSS-in-JS | 将 CSS 写入 JavaScript(如 styled-components) | React/Vue 组件化开发 |
和传统css的区别
一、原子化 CSS 的核心概念
| 特性 | 描述 |
|---|---|
| 定义 | 将 CSS 样式拆解为单一功能的原子类(每个类只对应一个样式属性) |
| 目标 | 通过组合原子类构建样式,减少重复代码,提升复用性 |
| 典型框架 | Tailwind CSS、UnoCSS、Tachyons |
二、原子化 CSS vs 传统 CSS
| 对比维度 | 原子化 CSS | 传统 CSS |
|---|---|---|
| 类名语义 | 类名直接描述样式(如 .text-red) | 类名描述组件/功能(如 .error-message) |
| 代码复用 | 高复用性,通过组合原子类复用样式 | 复用性依赖组件或模块化设计 |
| 维护成本 | 类名与样式直接关联,修改风险低 | 修改样式可能影响多个组件,需谨慎 |
| 文件体积 | 通过按需生成原子类,最终体积更小 | 随着项目增长,CSS 文件可能臃肿 |
| 开发体验 | 需记忆原子类名,但借助工具可自动补全 | 需手动编写语义化类名和样式 |
三、原子化 CSS 的代码示例
1. 原子类定义
css
复制
/* 原子类库示例 */
.text-red { color: #ff0000; }
.mb-4 { margin-bottom: 1rem; }
.flex { display: flex; }
.items-center { align-items: center; }
2. HTML 中使用原子类
html
复制
<!-- 通过组合原子类构建样式 -->
<div class="flex items-center mb-4">
<p class="text-red">Error: Invalid input</p>
</div>
运行 HTML
四、原子化 CSS 的优缺点
| 优点 | 缺点 |
|---|---|
| ✅ 减少重复代码,CSS 文件更小 | ❌ HTML 类名冗长,可读性下降 |
| ✅ 样式与结构紧密绑定,便于维护 | ❌ 需学习原子类命名规则(如 Tailwind) |
| ✅ 避免全局样式污染 | ❌ 复杂样式组合可能难以调试 |
| ✅ 适合组件化开发(如 React/Vue) | ❌ 对设计稿自由度高的项目不友好 |
五、适用场景
| 场景 | 说明 |
|---|---|
| 高频复用简单样式 | 如边距、颜色、字体大小等基础样式 |
| 组件化框架开发 | 结合 React/Vue 等框架,通过原子类快速构建组件样式 |
| 设计系统标准化 | 强制遵循统一的设计规范,减少样式冲突 |
| 性能敏感型项目 | 通过按需加载原子类,减少未使用的 CSS 代码 |
六、原子化 CSS 工具推荐
| 工具 | 特点 |
|---|---|
| Tailwind CSS | 最流行的原子化框架,支持自定义主题、响应式设计 |
| UnoCSS | 按需生成原子类,极高性能,支持多种预设(如 Tailwind、Windi CSS) |
| Tachyons | 轻量级原子化 CSS,强调功能性类名 |
七、实用技巧
1. 结合 CSS 变量增强灵活性
css
复制
:root {
--primary-color: #007bff;
}
.text-primary { color: var(--primary-color); }
2. 使用工具生成原子类
通过构建工具(如 PostCSS)按需生成原子类,避免手动编写:
javascript
复制
// postcss.config.js
module.exports = {
plugins: {
'@unocss/postcss': {} // 使用 UnoCSS 自动生成原子类
}
}
3. 响应式设计
利用 Tailwind 的响应式前缀:
html
复制
<div class="text-base md:text-lg lg:text-xl">响应式文本大小</div>
运行 HTML
八、总结
原子化 CSS 是一种通过 极简、组合式 的类名管理样式的方案,适合追求高复用性、低维护成本的项目,但对开发者的工具链依赖较高。是否采用需权衡项目规模、设计灵活性和团队习惯。
重排和重绘
在网页的渲染过程中,"重排(Reflow)"和"重绘(Repaint)"是两个重要的概念。它们描述了浏览器如何更新页面上的元素以反映样式或布局的变化。
为了更清晰地展示这两个过程的区别,以下是一个表格形式的对比:
| 特性 | 重排 (Reflow) | 重绘 (Repaint) |
|---|---|---|
| 定义 | 当对DOM的修改导致元素尺寸或位置发生变化时,需要重新计算布局,这被称为重排。 | 当对DOM的修改仅影响元素的颜色或其他不涉及尺寸与位置变化的属性时,仅需重绘该部分,这被称为重绘。 |
| 影响范围 | 较大,因为可能涉及到周围元素甚至整个文档布局的调整。 | 较小,通常只影响到元素本身或局部区域。 |
| 性能消耗 | 高,因为它涉及复杂的计算,包括元素的位置、大小等。 | 相对较低,主要消耗在于绘制新的像素值。 |
| 触发原因 | 添加或删除可见的DOM元素、元素尺寸改变、内容变化、浏览器窗口尺寸改变等。 | 色彩、背景色、可见性(visibility)的更改(注意不是display:none)。 |
| 示例 | 改变一个元素的宽度或高度、增加一个动态效果改变了某个元素的位置。 | 改变文本颜色、背景颜色或者给元素添加阴影效果。 |
理解这两个概念对于优化网页性能非常重要,尽量减少重排次数可以显著提升页面响应速度和整体性能。例如,可以通过批量修改DOM、使用CSS3硬件加速、避免逐帧动画等方式来降低重排和重绘的频率。
基础类型和复杂类型的区别
在编程语言中,通常将数据类型分为基础类型(Primitive Types)和复杂类型(Complex Types 或 Reference Types)。它们之间有几个关键的区别,尤其是在存储方式、传递方式以及操作方式上。以下是一个表格形式的对比:
| 特性 | 基础类型 (Primitive Types) | 复杂类型 (Complex Types / Reference Types) |
|---|---|---|
| 定义 | 包括数字、布尔值、字符串等简单的数据类型。 | 由多个值组成的数据结构,如对象、数组、函数等。 |
| 存储位置 | 直接存储具体的值,通常位于栈内存中。 | 存储的是指向实际值的引用或地址,实际值可能位于堆内存中。 |
| 内存占用 | 固定大小,取决于具体的基础类型。 | 可变大小,取决于包含的数据量和类型。 |
| 拷贝行为 | 赋值时进行完全拷贝,即两个独立的副本。 | 赋值时只复制引用,原始对象和新变量指向同一块内存区域。 |
| 比较 | 值比较,两个基础类型的值相同则认为相等。 | 引用比较,默认情况下是检查是否为同一引用;需要深入比较内容是否相等。 |
| 访问方式 | 直接访问其值。 | 需要通过引用间接访问。 |
示例
基础类型:
number,string,boolean,null,undefined,symbol(ES6新增),bigint(ES10新增)javascript浅色版本
let num = 10; let str = "Hello";复杂类型:
object,array,function等javascript浅色版本
let obj = {name: "Alice"}; let arr = [1, 2, 3]; let func = function() {};
理解这两种类型的区别对于编写高效且无误的代码至关重要,尤其是在处理大型应用或者性能优化时。正确地使用它们可以避免许多常见的陷阱,比如意外的副作用和错误的比较结果。
小数计算精度丢失
以下是关于 小数计算精度丢失 的表格说明,展示常见场景下由于浮点数表示法(如IEEE 754标准)导致的精度问题:
| 计算示例 | 预期结果 | 实际计算结果 | 精度丢失原因 | 常见语言/环境 |
|---|---|---|---|---|
0.1 + 0.2 | 0.3 | 0.30000000000000004 | 0.1和0.2在二进制浮点数中无法精确表示,导致舍入误差累积。 | JavaScript, Python, Java等 |
0.1 + 0.7 | 0.8 | 0.7999999999999999 | 类似原因:二进制无法精确表示十进制小数,加法后误差放大。 | 多数浮点运算环境 |
0.3 - 0.2 | 0.1 | 0.09999999999999998 | 减法操作中,浮点数的二进制近似值导致误差。 | Python, C++等 |
1.0 - 0.9 | 0.1 | 0.09999999999999998 | 十进制减法在二进制浮点运算中无法精确匹配。 | 通用浮点运算问题 |
0.1 * 0.1 | 0.01 | 0.010000000000000002 | 乘法操作会放大二进制浮点数的舍入误差。 | JavaScript, Python等 |
0.1 + 0.1 + 0.1 | 0.3 | 0.30000000000000004 | 多次加法操作中误差逐步累积。 | 大多数编程语言 |
0.3 / 0.1 | 3 | 2.9999999999999996 | 除法操作可能因浮点数的近似值导致结果偏离预期。 | Python, Java等 |
0.2 * 3 | 0.6 | 0.6000000000000001 | 即使整数倍计算,浮点数的二进制表示仍可能产生误差。 | 通用浮点运算问题 |
0.00001 * 100000 | 1 | 0.9999999999999999 | 极小值与极大值相乘时,浮点数精度限制导致误差。 | 多数编程语言 |
0.1 + 0.1 + ...(10次) | 1.0 | 0.9999999999999999 | 多次累加操作中,误差逐步累积,最终结果偏离预期。 | 通用浮点运算问题 |
备注:
- 根本原因: 计算机使用二进制浮点数(如IEEE 754标准)表示小数时,某些十进制小数(如0.1、0.2)无法精确转换为二进制形式,导致计算时产生微小误差。
- 解决方案:
- 高精度库:使用专门的高精度数值类型(如Python的
decimal模块、Java的BigDecimal)。 - 整数替代:将小数转换为整数运算(如以分代替元进行金额计算)。
- 误差容忍:比较浮点数时允许一定误差范围(如
abs(a - b) < 1e-9)。
- 高精度库:使用专门的高精度数值类型(如Python的
- 普遍性: 该问题存在于所有遵循IEEE 754标准的编程语言中(包括JavaScript、Python、Java、C++等)。
闭包
以下是关于闭包的详细总结表格:
| 类别 | 详细说明 |
|---|---|
| 定义 | 闭包(Closure)是能够访问其他函数作用域中变量的函数。闭包由函数及其相关的引用环境(词法作用域)组合而成,即使外部函数已经执行完毕,内部函数仍能保留对外部变量的引用。 |
| 原理 | 1. 词法作用域:函数在定义时确定作用域链,而非执行时。 2. 作用域链保留:内部函数持有外部函数的作用域链引用,导致外部函数的变量不会被垃圾回收。 3. 生命周期延长:闭包使得外部函数变量的生命周期被延长,直到闭包不再被引用。 |
| 创建场景 | 1. 函数返回函数:外层函数返回内层函数。 2. 事件处理:函数作为事件回调,访问外部变量。 3. 模块化模式:通过闭包封装私有变量。 4. 异步操作:如 setTimeout 中访问外部变量。 |
| 特性 | - 记忆外部变量:闭包可以“记住”定义时的环境。 - 数据封装:通过闭包隐藏私有变量,仅暴露接口。 - 动态性:闭包捕获的是变量的最终值(可通过立即执行函数解决)。 |
| 优点 | 1. 实现私有变量和模块化开发。 2. 支持函数柯里化(Currying)和偏函数应用。 3. 保持变量状态,避免全局污染。 4. 在异步编程中保留上下文(如回调函数)。 |
| 缺点 | 1. 内存泄漏:若闭包长期存在,外部函数的变量无法释放。 2. 性能影响:闭包的作用域链较长,访问外部变量比局部变量慢。 3. 意外行为:循环中创建闭包可能捕获错误的变量值(需用 let 或 IIFE 解决)。 |
| 注意事项 | 1. 避免不必要的闭包,及时解除引用(如置为 null)。 2. 在循环中谨慎使用闭包,优先使用块级作用域变量(let)。 3. 使用严格模式('use strict')防止意外创建全局变量。 4. 模块化场景下,合理设计闭包的作用域层级。 |
代码示例
javascript
复制
// 1. 基本闭包结构
function outer() {
let count = 0;
return function inner() {
count++;
console.log(count);
};
}
const counter = outer();
counter(); // 输出 1
counter(); // 输出 2
// 2. 模块化模式(封装私有变量)
const module = (function() {
let privateVar = 0;
return {
getVar: () => privateVar,
increment: () => privateVar++
};
})();
module.increment();
console.log(module.getVar()); // 输出 1
// 3. 解决循环中的闭包问题(使用 IIFE)
for (var i = 0; i < 3; i++) {
(function(j) {
setTimeout(() => console.log(j), 100); // 输出 0, 1, 2
})(i);
}
总结
闭包是 JavaScript 中实现封装、模块化和函数式编程的核心机制,但需注意内存管理和变量作用域问题。合理使用闭包可以提升代码的灵活性和可维护性。
6. Promise
| Promise 维度 | 详情 |
|---|---|
| 概述 | 1.解决回调地狱:通过链式调用.then(),将复杂异步逻辑按顺序组织,避免层层嵌套。2. 状态管理与不可逆:有 pending(进行中)、fulfilled(已成功)、rejected(已失败)三种状态,一旦状态变化就不可逆。 |
| 基本使用 | 1. 链式调⽤与错误捕获 :通过 .then() ⽅法链式调⽤,逐步处理异步操作的 成功与失败,并通过 .catch() ⽅法捕获异常,进⾏统⼀的错误处理。可以将异步逻辑按步骤拆解,提⾼代码的可读性和可维护性。2. 状态改变 :Promise 允许通过 resolve(value) 和 reject(reason) 分别返回成功和失败结果。可以结合业务需求,在不同状态下做出相应处理 |
| 静态方法 | 1.resolve(value):返回以给定值解析的 Promise 对象,用于手动创建成功的异步操作。2. reject(reason):返回带有拒绝原因的 Promise 对象,用于手动创建失败的异步操作。 3. Promise.all([p1,p2,p3....]):接收一组 Promise 实例,所有实例成功才返回成功结果,有一个失败则返回该失败结果,常用于处理多个异步任务的并发。 4. Promise.race([p1,p2,p3....]):返回最先完成(无论成功还是失败)的 Promise 结果,适合对最快结果做出响应的场景。 5. Promise.allSettled([p1,p2,p3....]):无论成功或失败,返回所有结果。 |
| 实例方法 | 1.then(onFulfilled, onRejected):添加成功和失败的回调,返回新的 Promise 对象,支持链式调用,实现顺序处理异步任务。 2. catch(onRejected):捕获链式调用中的错误,进行统一错误处理,在后续步骤依赖前面操作时很有用。 3. finally(onFinally):无论成功还是失败,finally都会在最后执行,常用于资源清理或结尾操作。 |
| 手写 Promise 源码 | 1.核心构造原理:Promise 是类,构造函数constructor接收执行器executor,包含resolve和reject两个回调函数。 2. 异步支持与回调队列:通过onFulfilledCallbacks和onRejectedCallbacks分别存储成功和失败的回调队列,确保异步任务完成后依次执行回调。 3. 状态管理与不可逆:调用resolve或reject后,状态从pending变为fulfilled或rejected,状态不可逆。 |
| 高级实现 | 1.Promise.all实现:接收多个 Promise 对象,所有 Promise 都成功时,才返回新的成功的 Promise,否则返回第一个失败的结果,适用于批量请求多个 API 等场景 2. Promise.race实现:返回最先改变状态的 Promise,无论成功还是失败,适合多服务请求时选择最快返回值的场景。 |
| 应用场景 | 1.并发任务处理:用Promise.all处理多个异步任务,所有任务完成后执行统一操作,适用于并发 API 请求或批量处理任务。 2. 竞赛任务处理:用Promise.race对比多个异步任务的速度,谁先完成返回谁的结果,适用于竞赛场景或需要快速响应的任务。 3. 统一异常处理:用Promise.catch对多个链式操作中的错误进行统一捕获和处理,提高代码可读性。 4. 异步流程控制:Promise 通过链式调用实现顺序处理异步操作,结合finally确保流程末尾资源清理。 |
| 优势 | 1.解决回调地狱问题:通过链式.then()方法,避免传统回调函数嵌套过多导致的代码可读性差的问题,在处理多层级异步操作时提供更好的结构化控制流程。 2. 错误处理机制完善:支持.catch()进行统一的错误捕获,并支持通过.finally()进行收尾操作,确保即使发生错误也能进行资源回收或状态重置。 |
| 局限性 | 1.无内置取消功能:Promise 一旦创建,无法中途取消执行,处理长时间未完成的异步任务时可能带来资源浪费。 2. 缺乏序列化处理:对于依赖前一步结果的操作,Promise 的链式调用较为繁琐且灵活性不足,Async/Await 提供了更自然的顺序处理方式。 |
7. 事件循环(eventLoop)
1. 浏览器
1. 事件循环的步骤
- 执行全局脚本代码,这可视为一个宏任务。
- 执行完毕后,检查微任务队列,若有微任务,执行微任务。
- 微任务执行完毕后,开始下一个宏任务(如
setTimeout定时器回调),重复步骤 2。- 循环此过程
2. 微任务与宏任务
JavaScript 的异步任务可分为两类:宏任务和微任务。
- 宏任务:包含整体代码 script、
setTimeout、setInterval、I/O 操作、UI 渲染等。- 微任务:包含
Promise.then、async/await、process.nextTick(Node.js 环境)等。执行规则:
- 每个宏任务执行完毕后,若存在微任务队列,会先清空微任务队列,即执行所有微任务。
- 仅当微任务队列为空时,才会继续执行下一个宏任务
2. Node环境
| 阶段名称 | 描述 | 执行顺序 |
|---|---|---|
| Timers | 执行**setTimeout和setInterval**的回调函数。定时器回调时间不保证精确,依赖于事件循环的负载。 | 事件循环的第一阶段,处理所有到期的定时器回调。 |
| Pending Callbacks | 处理延迟执行的 I/O 回调,如文件系统、网络请求结果等,不包括 close 事件。 | 第二阶段,处理挂起的 I/O 操作的回调,通常在 Timers 阶段之后。 |
| Idle, Prepare | libuv 内部阶段,用于准备下一轮事件循环的运行,一般开发者不会直接使用。 | 内部阶段,主要为事件循环的下一次迭代做准备。 |
| Poll | 事件循环的核心阶段,处理几乎所有的 I/O 操作。如果没有到期的定时器或等待的 I/O 事件,会在此阻塞。 | 核心阶段,在此等待新事件或进入 Check 阶段。 |
| Check | 执行**setImmediate**的回调,使得回调在当前 I/O 操作完成后尽快执行。 | 通常在 Poll 阶段之后执行,处理立即回调。 |
| Close Callbacks | 处理关闭事件的回调,如**socket.on('close') 。** | 最终阶段,处理如关闭网络连接或文件的相关回调。 |
事件循环的执⾏顺序:
在 Timers 阶段,执⾏所有到期的定时器回调。
进⼊ Poll 阶段:事件循环检查是否有等待处理的 I/O 事件。如果没有事件或到期的定时器,则阻塞在此阶段。
在 Check 阶段,执⾏
setImmediate回调。如果所有阶段完成,事件循环返回 Timers 阶段,进⼊下⼀个循环,继续处理回调。
8. setTimeout精度丢失
Js是⼀个单线程语⾔,同⼀时间只能做同⼀件事情。但单线程也带来了⼀些问题,⽐如线程阻塞,CPU利⽤率不⾼等问题
代码演示
let startTime = Date.now();
setTimeout(function () {
console.log('任务完成于: ' + (Date.now() - startTime) + 'ms')
}, 0)
for (let i = 0; i < 9000; i"5) {
console.log(5 + 8 + 8 + 8)
}
console.log('主线程复杂任务耗时:' + (Date.now() - startTime) + 'ms')
解决⽅案(不彻底,没办法)
使⽤ requestAnimationFrame 代替 setTimeout 可以获得更⾼的精度。requestAnimationFrame 会在浏览器的下⼀次重绘之前调⽤回 调函数,通常是 16.67ms(60帧每秒)。
let startTime = performance.now();
// 定义一个复杂任务函数,该函数执行大量计算
function complexTask() {
// 模拟一个复杂的主线程任务
for (let i = 0; i < 9000; i++) {
console.log(5 + 8 + 8 + 8); // 执行计算并输出结果
}
// 输出主线程复杂任务的耗时
console.log('主线程复杂任务耗时: ' + (performance.now() - startTime).toFixed(2) + 'ms');
}
// 定义一个动画帧回调函数
function onAnimationFrame() {
// 输出任务完成时的耗时,使用高精度时间计算
console.log('任务完成于:' + (performance.now() - startTime).toFixed(2) + 'ms');
// 在下一次动画帧调用复杂任务函数,确保任务在绘制帧之前执行
requestAnimationFrame(complexTask);
}
// 使用requestAnimationFrame调度onAnimationFrame函数
// 这确保onAnimationFrame函数会在浏览器下一次重绘前执行
requestAnimationFrame(onAnimationFrame);
9. ES6新特性
| ES6 新特性维度 | 总结 |
|---|---|
| 1.let 和 const | 块级作用域:let 和 const 定义的变量具有块级作用域,避免变量提升问题,const 用于声明不可变常量。 |
| 2.箭头函数 | 简化函数表达式:箭头函数简化函数的书写,并且不绑定自身的 this,更适合回调函数。 |
| 3.类 (Classes) | 面向对象语法糖:通过类的语法,定义构造函数、方法和继承,提供了更直观的面向对象编程模式。 |
| 4.模板字符串 | 多行字符串与插值:使用**反引号(\ ``)编写多行字符串,并通过 ${} 进行变量插值**,提升字符串处理的灵活性。 |
| 5.解构赋值 | 简化数据提取:通过解构赋值,快速从对象或数组中提取数据,减少手动赋值操作。 |
| 6.默认参数与剩余参数 | 参数默认值与灵活传参:函数参数支持默认值,剩余参数(...)允许将不定数量参数转换为数组,提升函数灵活性。 |
| 7.Promises | 异步操作管理:Promise 提供了更优雅的异步操作处理方式,避免回调地狱,通过.then () 和.catch () 实现链式调用。 |
| 8.ES6 模块化 | 模块导入与导出:import/export 提供了模块化支持,允许模块拆分与复用,替代传统的全局变量共享机制,提升代码组织性和维护性。 |
| 9.新数据结构 | Map 和 Set:Map 提供键值对存储,Set 用于存储唯一值,WeakMap 和 WeakSet 提供弱引用支持,避免内存泄漏。 |
| 10.迭代器与生成器 | 迭代与暂停机制:Iterator 提供遍历机制,Generator 函数允许函数执行的暂停与恢复,简化复杂迭代逻辑。 |
| 11.新数组与对象方法 | 数组与对象操作:Array.from 与 Object.assign:Array.from 将类数组对象转为数组,Object.assign 合并对象,简化数组与对象操作。 |
| 12.Symbol 类型 | 唯一性标识符:Symbol 创建唯一且不可变的标识符,常用于对象属性键,避免命名冲突。 |
| 13.Proxy 和 Reflect | 元编程支持:Proxy 用于拦截对象操作,Reflect 提供默认行为调用,增强了对对象的控制能力,适合元编程场景。 |
10. 数组内置高阶函数
map:不会修改原数组,返回⼀个新数组
filter:不会修改原数组,返回⼀个过滤后新数组
reduce:数组迭代器,对数组元素进⾏累计、聚合、转换或计算
forEach可以使⽤return,退出当前循环,继续下次循环**
some:有⼀个为真,结果为真
every:全部都为真,结果为真,否则结果为假
sort:数组排序
11. 原型和原型链
| 概念维度 | 总结 |
|---|---|
| 原型 (Prototype) | Prototype 是函数的一个属性,指向该函数的原型对象。当函数作为构造函数被调用时,基于该构造函数创建的实例对象会共享访问这个原型对象上的属性和方法,从而实现属性与方法的共享,节省内存。 |
| 原型链 (Prototype Chain) | __proto__是对象的一个内部属性,指向创建它的构造函数的原型对象(prototype)。每个原型对象本身也有 __proto__属性,形成链式结构,即原型链。当访问对象的属性或方法时,若对象本身没有该属性或方法,则会沿着原型链向上查找,直到找到或到达链的顶端null。 |
12. this指向
- **全局上下文:**在全局执⾏环境中(⾮严格模式下),this指向全局对象;在浏览器中是window对象,在Node.js中是global对象。在严格模 式('use strict')下,this的值为undefined。
- **函数调用:**当函数不作为对象的⽅法被调⽤时,this指向全局对象(⾮严格模式下)或undefined(严格模式下)。
- **方法调用:**当函数作为对象的⽅法被调⽤时,this指向该⽅法所属的对象。
- **构造函数:**在构造函数中,this指向新创建的对象。
- **箭头函数:**箭头函数没有⾃⼰的this,它会捕获其所在上下⽂的this值作为⾃⼰的this值,⽆法通过bind、call或apply改变。
改变this指向: bind call apply
13. 事件委托冒泡和捕获
事件委托是⼀种利用事件冒泡原理来优化事件监听的技术。通过在父元素上设置监听器来管理子元素的事件,而不是直接在子元素上设置监听器。
1. 事件冒泡
当⼀个事件触发在DOM的⼀个元素上时,这个事件会向上冒泡到其父元素,⼀直到document对象。
优点:
- 减少内存消耗:减少事件监听器的数量,降低内存占⽤。
- 动态元素管理:对于动态添加的⼦元素,⽆需重新绑定事件监听器。
2. 事件捕获:
当⼀个事件从document对象传导到⽬标节点(触发事件的元素)的过程。在事件捕获阶段,事件会从最外层的⽗元素开始,逐级向下传递到⽬标元素。
在addEventListener的第三个参数设置为true,即可在捕获阶段
14. 数据类型判断
| 数据类型判断方式 | 总结 |
|---|---|
| 1. typeof | 基本类型判断:typeof 能正确判断基本类型(除 null 外),对函数返回 "function" ,但对数组和 null 返回 "object" ,无法准确区分对象和数组。 |
| 2. instanceof | 原型链检测:instanceof 用于判断对象是否是某构造函数的实例,适用于检测对象类型,但无法用于基本类型的判断。常用于自定义类和内置对象(如数组)的类型检测。 |
| 3. Object.prototype.toString.call | 精确判断:通过 Object.prototype.toString.call () 可以精确判断包括数组、null、函数、基本类型在内的所有数据类型,返回 [object Type] 格式的字符串,是最可靠的类型判断方式。推荐使用。 |
| 4. Array.isArray() | 数组专用判断:Array.isArray () 是专门用于判断数组的函数,能够正确判断数组类型,优于 typeof 和 instanceof 。 |
15. JS作用域
全局作⽤域:在代码中任何地⽅都能访问到的变量和函数。
局部作⽤域:只能在定义它们的函数或代码块内访问到的变量和函数。
局部作⽤域:
- 函数作⽤域:变量和函数在整个函数内部都是可访问的,但在函数外部不可访问。
- 块级作⽤域(ES6引⼊):通过let和const声明的变量在其所在的代码块(如if语句、for循环)内有效。
作⽤域链:
当访问⼀个变量时,JavaScript会⾸先在当前作⽤域查找,如果没找到,会继续在上⼀层作⽤域查找,直到找到该变量或达到全局作⽤域。这种结构称为作⽤域链。
16. for in for Of 区别(掌握)
| 区别维度 | 总结 |
|---|---|
| 1. for...of原理 | 遍历可迭代对象 : for...of ⽤于遍历实现了 可迭代协议(即实现了 Symbol.iterator 接⼝)的数据结构,遍历的内容是 元素本身。常⽤于遍历 数组、字符串、 Map、 Set、 NodeList 等可迭代对象。 |
| 2. for...in原理 | 遍历对象的可枚举属性 : for...in ⽤于遍历对象的 可枚举属性,包括对象原型链上的可枚举属性。遍历的内容是 属性名(键),不适合遍历数组元素,常⽤于遍历对象的属性。 |
| 3. for...of可遍历类型 | 1. 数组(Array) :遍历数组的元素。 2. 字符串(String) :遍历字符串的每个字符。 3. Map/Set :遍历 Map 键值对、 Set 的值。 4. arguments 对象 :遍历函数参数。 5. NodeList :遍历 DOM 节点列表。 6. 生成器对象 :遍历⽣成器的每个返回值 |
| 4. for...of可遍历类型 | 1. 对象(Object) :遍历对象的可枚举属性(包括原型链上的)。 2. 数组(Array) :遍历数组的索引(不推荐⽤于数组)。 3. 字符串(String) :遍历字符串的索引。 4. arguments 对象 :遍历函数参数的索引。 5. ⽤户⾃定义可枚举属性 :遍历对象上⼿动添加的可枚举属性。 |
17. url输入地址到浏览器的一个过程
1-8 可只说文字加粗部分,9要详细说
1. **URL解析**:浏览器先解析URL,包括协议、主机名、端⼝号、路径等信息。
2. **DNS解析**:将域名解析为IP地址。
3. **建⽴TCP连接**:浏览器与服务器之间通过TCP协议建⽴连接,这个过程通常包括三次握⼿。
4. **发送HTTP请求**:浏览器向服务器发送HTTP请求
5. **服务器处理请求**:可能是返回请求的资源,也可能是执⾏后台逻辑。
6. **服务器返回响应**:服务器处理完请求后,将响应内容发送给浏览器。
7. **浏览器接收响应**:根据响应内容渲染HTML、解析JavaScript。
8. **关闭TCP连接**:响应完成后会被关闭,释放资源。
9. **`渲染⻚⾯(重点说)`**:浏览器将接收到的HTML、CSS、JavaScript等内容解析并渲染成可视化⻚⾯,显示给⽤户。
解析HTML:把HTML⽂档解析成DOM树。
构建DOM树:构建DOM树
解析CSS:解析css,构建CSS树
合并DOM和CSSOM:浏览器将DOM树和CSSOM合并,⽣成渲染树
布局:浏览器根据渲染树计算每个元素在⻚⾯中的位置和⼤⼩,这个过程是重排。
绘制:浏览器根据布局结果将每个元素绘制到⻚⾯上,包括背景、边框、⽂本等。
渲染完成:⻚⾯渲染完成后,浏览器会将渲染好的⻚⾯显示给⽤户。
18. defer 和 async 的区别是什么?

绿线:HTML 的解析时间
蓝线:JS 脚本的加载时间
红⾊:JS 脚本的执⾏时间
1.defer和async属性让JS在⽹络加载过程都不会阻塞HTML的解析,都是异步执⾏的。
2.两者的区别, 脚本加载完成之后,async是⽴刻执⾏,defer会在DOMContentLoaded之前执⾏
铺垫:
DOMContentLoaded事件不需要等待⻚⾯的所有资源加载完成;load事件在⻚⾯的所有资源加载完成后触发。3.先执⾏DOMContentLoaded事件 再执⾏load事件。
19. 前端存储的区别是什么?
| 存储方式 | 定义 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| LocalStorage | 浏览器提供的本地存储机制,可存储最大约 5MB 的数据,存储的数据永久有效,除非主动删除。 | 1. 数据持久化,刷新页面或重启浏览器数据仍存在。 2. API 简单易用,几乎所有现代浏览器支持。3. 无网络依赖。 | 1. 存储空间有限,仅支持字符串格式存储。 2. 不适合存储敏感数据,无数据加密机制。 | 适合存储非敏感的用户偏好、主题设置等持久化数据。 |
| SessionStorage | 浏览器提供的会话存储机制,存储在当前会话窗口内,关闭页面或浏览器后数据即消失。 | 1. 存储空间充足,最大约 5MB。2. 数据** 随会话生存**页面关闭后自动清除3. 同样易用,API 一致。 | **1. 生命周期短,**仅限于当前会话。 2. 与 LocalStorage 一样,不适合存储敏感信息。 | 适合存储临时数据,如分页、过滤器状态,表单未提交数据等。 |
| Cookie | 客户端与服务器之间传递的小数据,最大存储约 4KB,通常用于持久化状态或跨域请求认证。 | 1. 跨域通信,可与服务器交互。2. 持久性强,可设置过期时间。 3. 可用于身份验证和跟踪。 | 1. 存储空间极小,约 4KB。 2. 每次请求都会携带,增加网络负担。 3. 需谨慎处理安全性问题。 | 适用于身份验证、跟踪用户行为、存储会话信息,如登录状态、购物车数据等。 |
| IndexedDB | 浏览器内建的 NoSQL 数据库,用于存储大量结构化数据,允许事务、索引、多种数据类型操作。 | 1. 存储容量大,理论上无上限,适合存储大数据。 2. 异步操作,性能好。 3. 支持多种数据格式,如对象存储。 | **1. 复杂度高,**API 使用复杂,不如 LocalStorage 易用。 2. 浏览器兼容性问题较多。 | 适用于需要存储大量数据或复杂结构的场景,如离线应用、客户端缓存。 |
| Cache API | 基于 Service Worker 的缓存机制,用于存储网络请求和响应,实现离线访问和加速页面加载。 | 1. 离线支持,可缓存请求资源,提高加载速度。2. 资源管理灵活,可手动管理缓存。 3. 支持文件、请求、响应。 | 1. 复杂性较高,需配合 Service Worker 使用。2. 无法用于结构化数据存储。 | 适合离线优先场景,如 PWA、缓存静态资源等。 |
| WebSQL | 早期的浏览器数据库,提供了使用 SQL 查询存储数据的能力,但已被弃用,不建议使用。 | 1. SQL 支持,适合熟悉 SQL 的开发者。 2. 数据查询、过滤功能强大。 | 1. 被弃用标准,未来兼容性堪忧。 2. 使用较复杂,不如 IndexedDB 灵活。 | 已被淘汰,建议使用其他替代方案。 |
20. 深拷贝 浅拷贝
// ⼿写深拷⻉
function deepClone(source, storage = new WeakMap()) {
// 针对基本数据类型
if (typeof source !== 'object' || source === null) {
return source
}
// 是否是日期
if (source.constructor === Date) {
return new Date(source)
}
// 是否是正则
if (source.constructor === RegExp) {
return new RegExp(source)
}
// 是否是数组
let target = source instanceof Array ? [] : {}
// 循环引用 返回存储的引用数据
if (storage.has(source)) return storage.get(source)
// 开辟存储空间设置临时存储值
storage.set(source, target)
// 是否包含 Symbol 类型
let isSymbol = Object.getOwnPropertySymbols(source)
// 包含 Symbol 类型
if (isSymbol.length) {
isSymbol.forEach((item) => {
if (typeof source[item] === 'object') {
target[item] = deepClone(source[item], storage);
return
}
target[item] = source[item]
})
}
// 不包含 Symbol
for(let key in source) {
if (source.hasOwnProperty(key)) {
target[key] = typeof source[key] === 'object' ? deepClone(sourcep[key], storage) : source[key]
}
}
return target;
}
1. 递归深拷贝如何解决对象相互引用的问题
总结:
1.解决循环引⽤:使⽤ WeakMap 避免对象的重复拷⻉,安全有效地处理循环引⽤。
2.⽀持复杂数据类型:可以正确处理 Date 、 RegExp 等特殊类型的拷⻉。
3.性能优化:通过 WeakMap 的弱引⽤机制,避免了内存泄漏,并减少了对基本类型的冗余操作。
最佳⽅案(递归深拷⻉解决循环引⽤)
function deepClone(value, map = new WeakMap()) {
//检查是否为基本类型
if (value===null || typeof value!== 'object') {
return value;
}
// 处理特殊类型,如 Date 和 RegExp
if (value instanceof Date) {
return new Date(value);
}
if (value instanceof RegExp) {
return new RegExp(value);
}
// 如果对象已经被拷⻉,直接返回之前的引⽤,防⽌循环引⽤
if (map.has(value)) {
return map.get(value);
}
// 创建一个新对象或数组,并将其存⼊ map 以便后续引⽤
const result = Array.isArray(value) ? [] : {};
map.set(value, result);
// 遍历对象的属性
for (const key in value) {
if (value.hasOwnProperty(key)) {
// 递归拷⻉对象的每个属性
result[key] = deepClone(value[key], map);
}
}
return result;
}
21. JS继承
| 继承⽅式 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| 原型链继承 | 将⼦类 prototype 指向⽗类实例,实现继承。 | 简单直接,继承⽗类属性和⽅法。 | 共享引⽤类型属性,实例间互相影响,⽆法向⽗类构造函数传参。 |
| 借⽤构造函数继承 | 在⼦类构造函数中调⽤⽗类构造函数,使⽤call 或 apply 改变上下⽂。 | 可以传参,避免引⽤属性共享。 | ⽆法继承⽗类原型⽅法,⽗类构造函数被多次调⽤,性能低。 |
| 组合继承 | 结合原型链和借⽤构造函数,继承原型⽅法和实例属性。 | 继承实例属性和原型⽅法,解决引⽤属性共享问题。 | ⽗类构造函数被调⽤两次,浪费内存。 |
| 原型式继承 | 使⽤ Object.create() 基于现有对象创建新对象。 | 不需要构造函数,轻量继承,适合对象继承。 | 共享引⽤类型属性,不能传参。 |
| 寄⽣式继承 | 基于原型式继承增强对象,返回新对象。 | 增强继承对象,适合一次性增强对象。 | ⽆法复⽤增强⽅法,性能差。 |
| 寄⽣组合式继承 | 在组合继承基础上优化,避免调⽤⽗类构造函数两次。 | ⾼效继承,避免⽗类构造函数重复调⽤,最优继承⽅式。 | 相对复杂,理解成本⾼。 |
| ES6class继承 | 使⽤ class 和 extends 实现继承。 | 语法简洁,继承关系清晰,⽀持传参和继承原型⽅法。 | 本质上基于原型链,底层问题依旧。 |
1. new发生了什么
1.创建新对象:在内存中分配一个新对象。
2.链接原型链:将新对象的原型指向构造函数的 prototype 。
3.绑定this :将构造函数的 this 绑定到新对象,执⾏构造函数中的逻辑。
4.返回对象:默认返回新对象,或构造函数返回的对象。
22. 模块化开发
分 CommonJS、AMD、UMD、ES6模块化,推荐使⽤ ES6 模块化
真正的模块化,它包括 CJS 、 AMD 、 CMD 、 UMD 和 ESM ,经过多年演变,⽬前 Web开发 倾向于 ESM , Node开发 倾向于 CJS
| 特性 | CJS | ESM |
|---|---|---|
| 语法类型 | 动态 | 静态 |
| 关键声明 | require | import 和 export |
| 加载⽅式 | 运⾏时加载 | 编译时加载 |
| 加载⾏为 | 同步加载 | 异步加载 |
| 书写位置 | 任意位置 | 必须在顶层 |
| 指针指向 | this指向当前模块 | this指向undefined |
| 执⾏顺序 | ⾸次引⽤时加载模块,之后读取缓存 | 引⼊时⽣成引⽤,执⾏时才正式取值 |
| 属性引⽤ | 基本类型值复制不共享,引⽤类型浅拷⻉共享 | 所有类型动态读取引⽤ |
| 属性修改 | ⼯作空间可修改引⽤的值 | ⼯作空间不可修改引⽤值,但可通过修改⽅法 |
| 模块化⽅案 | 定义 | 特点 |
|---|---|---|
| IIFE | 使⽤⽴即执⾏函数表达式封装模块化。 | 避免变量污染,全局唯一命名空间,适⽤于早期⽆模块化⼯具的场景。 |
| CJS | Node.js 的模块化标准,每个⽂件是一个独⽴模块。 | ⽀持模块缓存和同步加载,常⽤于服务器端开发。 |
| AMD | 浏览器端模块化标准,通过 define 和require 实现异步加载。 | 适合浏览器端异步加载模块,不符合现今⼴泛使⽤的模块化思维⽅式。 |
| CMD | 使⽤ Sea.js 规范,依赖就近,异步加载。 | 模块加载量更⼩,适合依赖就近的场景。 |
| UMD | 通⽤模块定义,兼容 CJS 和 AMD,且⽀持浏览器和服务器环境。 | 适⽤于混合开发环境的模块加载⽅案。 |
| ESM | ES6 的原⽣模块标准,⽀持静态分析和异步加载。 | 现代 Web 开发的主流⽅案,⽀持 import/export ,浏览器原⽣⽀持,提升了开发体验和性能。 |
23. ajax
1.原⽣XMLHttpRequest实现ajax
| 步骤 | 代码 | 描述 |
|---|---|---|
| 1.创建对象 | var xhr = new XMLHttpRequest(); | 创建 XMLHttpRequest 对象,作为请求的核⼼。 |
| 2.打开连接 | xhr.open('GET', 'https: $example.com', true); | 使⽤ open() ⽅法指定请求类型、URL 和是否异步( true 为异步)。 |
| 3.发送请求 | xhr.send(); | 使⽤ send() ⽅法发送请求, GET 请求不需要参数, POST 请求则需要传递参数。 |
| 4.监听响应 | xhr.onreadystatechange = function() { if (xhr.readyState === 4 && xhr.status ===200) { onsole.log(xhr.responseText); } }; | 通过 onreadystatechange 监听状态变化,当readyState ===4 且 status ===200 时处理成功响应。 |
| 5.取消请求 | xhr.abort(); | 通过 abort() ⽅法可以取消已发出的请求,适⽤于需要中⽌请求的场景。 |
2.ajax3种⽅案
| 对⽐项 | XMLHttpRequest (XHR) | Fetch API | Axios |
|---|---|---|---|
| ⻛格 | 基于回调函数,需⼿动处理状态变化,代码冗⻓且复杂。 | 基于 Promise,简洁明了,⽀持链式调⽤,现代浏览器原⽣⽀持。 | 基于 Promise,封装完善,⽀持链式调⽤,功能强⼤,语法简洁。 |
| 取消请求 | 通过 xhr.abort() 直接取消请求。 | 使⽤ AbortController 创建控制器,并通过controller.abort() 取消请求。 | 使⽤ CancelToken 创建取消标记,通过source.cancel() 取消请求。 |
| 拦截器 | 不⽀持拦截器,需⼿动处理每次请求和响应。 | 不⽀持拦截器,错误处理较为繁琐。 | ⽀持请求和响应拦截器,⽅便处理请求重试、鉴权、全局错误等逻辑。 |
| ⾃动解析 | ⼿动解析响应数据,特别是 JSON,需要 JSON.parse() 。 | 原⽣⽀持 .json() ⾃动解析响应数据,简化数据处理。 | ⾃动解析 JSON 响应,⽆需⼿动处理,默认封装常⻅场景。 |
| 错误处理 | 需⼿动处理状态码和错误,容易忽略异常状态。 | 基于 Promise 的 .catch() 进⾏统一错误处理。 | 提供全⾯的错误处理机制,⽀持 HTTP 错误和⽹络错误的统一处理。 |
| 进度监听 | ⽀持上传/下载进度事件监听。 | 不⽀持进度事件监听。 | ⽀持上传/下载进度事件监听,适合⼤⽂件传输场景。 |
| 跨域 | CORS 处理复杂,需⼿动配置。 | 默认⽀持 CORS,跨域处理相对简单。 | ⽀持 CORS,提供简洁的跨域请求⽅式。 |
24. hash路由和history路由区别
| 路由⽅式 | 核⼼总结与应⽤场景 |
|---|---|
| 1.Hash路由 | 基于 URL hash 部分的路由管理 ,使⽤ # 号管理⻚⾯导航,浏览器不会将 hash 部分发送到服务器,因此 不需要服务器配置。适⽤于⽆需 SEO ⽀持的应⽤,通过 hashchange 事件监测 URL 变化。 |
| 场景 | Vue Router 会维护一个路由表,通过 hash 变化找到对应的组件加载到⻚⾯中。⽆需服务器配置,适合⽆需刷新⻚⾯的应⽤。 |
| 2. History路由 | 基于 HTML5 History API 的路由管理 ,使⽤ pushState 和 replaceState 实现⽆刷新跳转。需要服务器端配置来处理直接访问和⻚⾯刷新,确保返回正确的⻚⾯,适合需要 SEO ⽀持的单⻚应⽤。 |
| 场景 | 需要与服务器配合,特别是在刷新⻚⾯时必须让服务器处理所有的路由请求,适合 SEO 友好的应⽤场景和更加现代的前端应⽤开发⽅式。 |
25. JS 执行上下文和生命周期以及执行栈
| JS执⾏机制维度 | 精简优化与核⼼总结 |
|---|---|
| 1. 执⾏上下⽂ | 1. 全局执⾏上下⽂ :全局作⽤域下的上下⽂,在浏览器中是 window ,在 Node.js 中是 global 。 2. 函数执⾏上下⽂ :每次调⽤函数时都会创建,包含局部变量、参数和作⽤域链。 3. Eval 执⾏上下⽂:仅在执⾏ eval() 时创建,不推荐使⽤。 |
| 2. 执⾏上下⽂组成 | 1. 变量对象 (VO) :存储变量、函数声明和形参,在函数上下⽂中称为 活动对象 (AO)。 2. 作⽤域链 :⽤来解析变量,包含当前上下⽂和⽗级上下⽂。 3. this 指向 :上下⽂会绑定 this ,依据调⽤⽅式决定指向。 |
| 3. 执⾏上下⽂⽣命周期 | 1. 创建阶段 :完成函数提升、变量提升和 this 的绑定。 2. 执⾏阶段 :代码按顺序执⾏,变量和函数被赋值和调⽤。 3. 销毁阶段 :上下⽂执⾏完毕后销毁,释放内存。 |
| 4. 执⾏栈 | 调⽤栈是后进先出结构 :⽤于跟踪函数调⽤。 1. ⼊栈:函数被调⽤时,将其执⾏上下⽂推⼊栈顶。 2. 出栈:函数执⾏完毕后,执⾏上下⽂从栈顶弹出。 3. 栈底永远是全局上下⽂,所有函数执⾏完毕后只剩全局上下⽂。 |
26. 前端跨域解决方案
| 跨域解决⽅案 | 精简优化与核⼼总结 |
|---|---|
| 1. Proxy 代理 | 开发环境代理解决⽅案 :通过 Vue 和 React 项⽬的 proxy 配置,可以将请求代理到不同的服务器,避免跨域问题。常⽤于开发环境,通过本地服务器转发请求实现跨域。 |
| 2.CORS(跨域资源共享) | 服务器端配置跨域 :通过服务器设置响应头,控制哪些域名可以访问资源,最常⻅的跨域解决⽅案,配置简单且适⽤于⼤部分场景。如设置 Access-Control-Allow-Origin 允许特定域名跨域访问。 |
| 3. Nginx 反向代理 | ⽣产环境的反向代理 :通过 Nginx 配置反向代理,将前端请求转发⾄⽬标服务器,实现跨域请求,常⽤于前后端分离架构下。 |
| 4. PostMessage | 跨窗⼝通信 :使⽤ window.postMessage 实现不同⻚⾯或 iframe 之间的通信,适⽤于⼦⻚⾯与⽗⻚⾯之间的数据传递。缺点是只适⽤于⻚⾯之间的通信,且需要⼿动管理安全性。 |
| 5. WebSocket跨域 | 不受同源策略限制的⻓连接 :WebSocket 可以⽤于实时通信场景,前后端可以双向通信,不受同源策略限制。常⽤于实时数据更新的应⽤。缺点是需要服务器⽀持 WebSocket 协议。 |
| 6. document.domain | 主域相同,⼦域不同的跨域 :通过设置 document.domain 为相同的主域,允许⼦域之间跨域。此⽅案只适⽤于同一主域下的跨域请求,简单且有效,但局限性较⼤。 |
| 7. window.name | 利⽤ window.name 跨⻚⾯传递数据 : window.name 属性⽀持⻚⾯跳转后保留数据,可以⽤于跨域数据传递。优点是兼容性好,缺点是只能传递字符串数据,适⽤场景有限。 |
27. 图片懒加载 接口懒加载
| 懒加载类型 | 精简优化与核⼼总结 |
|---|---|
| 1.图⽚懒加载 | 核⼼思想:滚动加载 。图⽚懒加载指的是图⽚不在⻚⾯初始加载时全部加载,⽽是当图⽚即将进⼊视⼝时才进⾏加载。 实现思路: 1. ⻚⾯初始加载时使⽤占位图或 data-src 存储真实图⽚ URL。 2. 通过 IntersectionObserver 或滚动监听来监测图⽚是否进⼊视⼝。 3. 当图⽚进⼊视⼝时,替换 src 属性为真实 URL,加载图⽚资源。 4. 加载完成后取消对该图⽚的监听,优化性能。 |
| 应⽤场景 | 提⾼⻚⾯初始加载性能 :适⽤于包含⼤量图⽚的⻚⾯,如电商⽹站、社交媒体等。通过懒加载减少图⽚资源的初始加载量,提升⻚⾯性能,降低⽤户⾸次加载时间。 |
| 2. 接⼝懒加载 | 核⼼思想:分⻚或⽆限滚动加载 。接⼝懒加载是指仅在⽤户需要时才发起请求,避免一次性加载⼤量数据。 实现思路: 1. ⻚⾯初始加载时仅请求第一⻚的数据。 2. 监听⽤户滚动事件,当⻚⾯接近底部时,触发新数据请求。 3. 将新请求的数据追加到已有列表中,并更新⻚⾯内容。 4. 当所有数据加载完成时,停⽌发起新请求。 |
| 应⽤场景 | 减少不必要的接⼝请求 :适⽤于需要分⻚加载或⽆限滚动的场景,如社交媒体、新闻⽹站、数据列表等。通过懒加载减少服务器压⼒,同时提升⽤户体验。 |
28. 设计模式
| 序号 | 设计模式 | 应⽤场景 | 具体实施措施 | 可落地步骤 |
|---|---|---|---|---|
| 1 | 单例模式(Singleton) | 全局状态管理,如应⽤配置、⽇志管理等。 | 1. 确保某个类只有一个实例,提供全局访问⼊⼝,适⽤于全局配置或状态管理。 | 1. 在前端项⽬中,使⽤ ES6 模块化机制导出单一实例,例如在 Vuex 中导出 store实例。 2.在 React 中,使⽤ Context 创建全局状态单例。3.⽤模块或闭包包装实例,确保应⽤中状态共享统一。 |
| 2 | ⼯⼚模式(Factory) | 组件创建,如动态创建不同类型的表单组件、图表组件等。 | 1. ⼯⼚模式封装对象创建逻辑,通过同一接⼝返回不同的组件或对象实例。 | 1. 在表单⽣成场景下,根据输⼊类型动态创建组件实例,例如在 Vue.中中通过 render函数动态创建输入框。 2.在数据可视化中,使用工厂模式返回不同类型图表组件,如 ECharts图表实例。 3.在 React 中封装组件工厂,根据配置生 |
| 3 | 观察者模式(Observer) | 事件驱动系统,如响应⽤户交互、数据流更新等场景。 | 1、通过订阅/发布模式,将状态变更⾃动通知给依赖该状态的对象或组件。 2、适⽤于事件系统、状态管理。 | 1.在 vue 中通过watch 监听数据变化,通知相应组件更新。 2.在 React 中使用 useEffect 监听依赖项变化,触发副作用更新。 3.使用 RxJS 或EventEmitter 实现数据流的观察者模式,内应用于前端数据流场景,如实时数据处理、Websocket 通信。 |
| 4 | 策略模式(Strategy) | 表单验证、不同算法选择,如根据不同表单字段动态选择验证规则。 | 1.策略模式定义多种算法,并通过策略类将不同的操作封装起来动态选择策略。 | 1.在表单验证场景,使用策略模式定义必填、格式验证等规则,通过配置动态应用验证策略。 2.在支付场景,使用策略模式封装不同支付方式,根据用户选择动态切换支付策略。 3.在搜索场景中,根据不同筛选条件动态应用不同的排序算法。 |
| 5 | 装饰器模式(Decorator) | 扩展组件功能,如给组件添加权限控制、日志记录等附加功能。 | 1.动态为对象添加额外功能,不改变原对象结构。 | 1.在 React 中使用 HOC(高阶组件)模式,实现装饰器模式,动态给组件添加权限控制或日志功能。 2.在 Vue 中使用自定义指令扩展功能,如权限指令或点击统计指令。 3.使用 TypeScript 装饰器语法,在类方法中添加日志记录、性能监控等功能。 |
| 6 | 代理模式(Proxy) | 数据缓存、权限控制如对某些请求进行缓存或限制访问。 | 1.代理模式为其他对象提供代理,控制对该对象的访问。 | 1.在前端缓存场景,使用代理模式拦截 API请求,根据缓存状态返回数据或继续请求。 2.在权限控制场景,使用 Proxy 拦截资源访问操作,验证用户权限后再决定是否访问资源。 3.使用 ES6 的 Proxy 对象拦截属性操作,动态生成数据或验证访问权限。 |
| 7 | 适配器模(Adapter) | 接口兼容,如新旧系统对接时将不同接口的功能兼容起来。 | 1.将不同的接口转化为兼容格式,适应不同系统或库之间的接口。 | 1.在前端缓存场景,使用代理模式拦截 API请求,根据缓存状态返回数据或继续请求。 2.在权限控制场景,使用 Proxy 拦截资源访问操作,验证用户权限后再决定是否访问资源。 3.使用 ES6 的 Proxy 对象拦截属性操作,动态生成数据或验证访问权限。 |
| 8 | 外观模式(Facade) | 简化复杂逻辑,如对复杂 API 或操作进行封装,提供简化的接口。 | 1.外观模式封装多个复杂子系统接口,提供简化的接口调用方式。 | 1.在 API 请求场景,使用外观模式封装多个复杂请求,统一处理错误与响应,提供简化接口。 2.在权限管理中,使用外观模式封装权限检查逻辑,简化权限验证。 3.在复杂表单处理场景中,使用外观模式封装表单验证与数据处理逻辑,简化用户操作。 |
| 9 | 组合模式(Composite) | 树形结构处理,如菜单栏、文件系统等场景。 | 1.组合模式将对象组合成树形结系,统一"国年个对 和经公对象。 | 1.在树形菜单或侧边栏中,使用组合模式实现递归渲染,统一处理菜单项与子菜单。 2.在文件系统中,使用组合模式统一处理文件和文件夹,递归遍历其子项。 3.在前端复杂组件系统中,使用组合模式创建嵌套组件,灵活构建布局结构。 |
| 10 | 命令模式(Command) | 可撤销操作,如编辑器中的撤销、重做功能。 | 1. 命令模式将操作封装为对象,⽀持请求队列、操作撤销和重做等场景。 | 1. 在⽂本编辑器中,使⽤命令模式记录⽤户的操作历史,⽀持撤销和重做。 2.在图形编辑器或绘图⼯具中,使⽤命令模式记录⽤户的操作序列,⽀持撤销和回放。 3、在操作队列中,使⽤命令模式将⽤户操作封装为命令对象,进⾏队列处理,简化操作管理。 |
29. PWA
| 序号 | ⾯试⾼频知识点 | 描述 | 详细可落地场景及实现 |
|---|---|---|---|
| 1 | Service Worker | 提供离线功能、拦截⽹络请求、后台同步、消息推送等,独⽴于主线程运⾏。 | 电商应⽤:⽤户⽆⽹络时依然可以浏览已缓存的商品⻚⾯,实现离线购物体验。实现:navigator.serviceWorker.register('/sw.js') 注册 Service Worker,并在 sw.js 中监听 fetch事件拦截⽹络请求,将缓存的静态资源返回。结合 Cache API 缓存产品数据,提升加载速度和离线访问能⼒。 |
| 2 | 离线缓存(Cache API) | 通过缓存静态资源实现离线访问,减少⽹络请求,提升应⽤加载性能。 | 新闻应⽤:⽤户可以离线阅读已缓存的新闻⽂章,提升⽤户在弱⽹和离线环境下的体验。实现:使⽤ Cache API,在 sw.js 中监听 install 事件,通过 caches.open('news-cache').then(cache* cache.addAll(['/index.html', '/article1.html'])) 缓存所有⻚⾯和资源,确保离线状态时资源可⽤。 |
| 3 | Web App Manifest | 定义 PWA 的元数据,使 Web 应⽤可以像原⽣应⽤一样安装、运⾏、全屏显示。 | 打⻋应⽤:⽤户可以将打⻋应⽤安装到主屏幕,像原⽣应⽤一样操作,并⽀持全屏模式。实现:在 manifest.json 中定义 name 、 short_name 、 icons 、 start_url 等元数据,确保在浏览器中安装时显示正确的图标和名称,结合 display: fullscreen 实现全屏显示。 |
| 4 | Push Notifications | 使⽤ Service Worker 实现消息推送,增强⽤户粘性,常⽤于⽤户互动和通知功能。 | 社交应⽤:⽤户在未打开应⽤时收到新消息通知,提升⽤户粘性。实现:通过 self.registration.showNotification('New message', { body: 'You have a new message',icon: '/icon.png', tag: 'message-group' }) 在后台推送通知,使⽤ Service Worker 处理后台的推送消息逻辑。确保服务器发送推送消息的 API 与应⽤⽆缝集成。 |
| 5 | Background Sync | 保障数据可靠性,在⽹络恢复时⾃动同步后台数据,避免数据丢失。 | 任务管理应⽤:⽤户离线提交任务,⽹络恢复后⾃动同步,确保操作不丢失。实现:在 sw.js 中使⽤ registration.sync.register('sync-tasks') 注册后台同步任务,当⽹络恢复时⾃动调⽤后台 API 提交任务数据。结合 IndexedDB 在本地存储待同步的任务列表,确保数据完整性。 |
| 6 | HTTPS | PWA 必须使⽤ HTTPS 确保安全通信,Service Worker 仅在HTTPS 环境下⼯作。 | ⽀付应⽤:确保⽀付信息通过 HTTPS 安全传输,防⽌中间⼈攻击。实现:使⽤ TLS/SSL 配置 HTTPS 服务器,所有资源和 API 都通过 https: $ 协议传输,确保⽤户隐私和⽀付安全。通过浏览器的 Content Security Policy (CSP) 限制第三⽅脚本的执⾏,提升安全性。 |
| 7 | 应⽤外壳架构(App Shell) | 缓存核⼼ UI 框架,提升离线访问和⾸次加载速度,适合需要快速响应的应⽤。 | 任务管理应⽤:即使⽤户在离线状态下,应⽤的基础 UI 框架(如侧边栏、导航栏)也能快速加载。实现:将 App Shell(HTML、CSS、JavaScript)资源提前缓存,通过 caches.open('app-shell').then(cache* cache.addAll(['/index.html', '/styles.css', '/app.js'])) 缓存 UI 框架,确保在⽤户访问时即刻渲染核⼼界⾯。 |
| 8 | 响应式设计 | 保障 PWA 在多设备上的一致性体验,⽀持⾃适应设计,提升跨平台⽤户体验。 | ⾳乐播放应⽤:确保应⽤在⼿机、平板、桌⾯设备上显示一致,并⽀持不同设备的操作习惯。实现:使⽤ CSS Flexbox 和 Grid 布局,配合 Media Queries 实现跨设备的响应式布局,确保应⽤在不同分辨率设备上均能良好呈现。通过 pointer-events 和键盘事件监听,⽀持触屏和键盘操作。 |
| 9 | 渐进增强 | 确保在⽀持的浏览器中启⽤ PWA功能,在不⽀持的浏览器中提供基础功能,平滑升级。 | 新闻应⽤:确保应⽤在⽀持 PWA 的浏览器中拥有完整的 PWA 功能,旧版浏览器依然能正常浏览内容。实现:在代码中进⾏浏览器功能检测,如 if ('serviceWorker' in navigator) 判断是否⽀持 ServiceWorker,根据检测结果决定是否启⽤ PWA 特性,同时为旧版浏览器提供基本的新闻浏览功能。 |
| 10 | ⽹络智能感知(Network Awareness) | 根据⽹络状态动态调整资源加载策略,优化弱⽹环境下的应⽤体验。 | 视频流应⽤:在弱⽹环境下⾃动降低视频质量,提升⽤户体验。实现:使⽤ navigator.connection.effectiveType 检测⽹络状态,如检测到 2g 或 slow-2g 时,动态切换到低分辨率视频资源。结合 Service Worker 实现弱⽹下的资源预加载和缓存,进一步提升体验。 |
30. 排序算法
| 序号 | 排序算法 | 描述 | 时间复杂度 | 空间复杂度 | 稳定性 | 适⽤场景 |
|---|---|---|---|---|---|---|
| 1 | 快速排序 | 选择基准元素,递归划分数组,左侧⼩于基准,右侧⼤于基准,最后合并。 | 平均 O(nlog n) | O(logn) | 不稳定 | 适⽤于⼤规模数据,性能⾼效,但不适合稳定排序场景。 |
| 2 | 归并排序 | 分治法,将数组递归分成两半,分别排序后合并,结果有序。 | O(n log n) | O(n) | 稳定 | 适合⼤规模需要 稳定排序 的场景,尤其是链表数据。 |
| 3 | 堆排序 | 基于堆结构,先构建最⼤堆或最⼩堆,再将堆顶元素与末尾元素交换,重新调整堆。 | O(n log n) | O(1) | 不稳定 | 适⽤于⼤规模数据,空间复杂度低,内存有限时表现优异。 |
| 4 | 希尔排序 | 插⼊排序的改进版,通过分组减少数据的移动次数,逐渐缩⼩增量⾄ 1。 | 平均O(n^1.3) | O(1) | 不稳定 | 适⽤于中等规模数据集,性能优于插⼊排序。 |
| 5 | 冒泡排序 | 每次⽐较相邻元素,将较⼤或较⼩的元素逐步“冒泡”到数组一端,重复进⾏。 | O(n²) | O(1) | 稳定 | 适⽤于⼩规模数据或基本有序的数据,算法简单但性能差。 |
| 6 | 插⼊排序 | 每次从未排序部分取出元素,插⼊到已排序部分的正确位置。 | O(n²) | O(1) | 稳定 | 适合⼩规模数据或 近乎有序 数据集,插⼊成本低,局部有序时性能较好。 |
| 7 | 选择排序 | 每次选择未排序部分的最⼩元素,放到已排序部分末尾,重复操作。 | O(n²) | O(1) | 不稳定 | 适⽤于数据量⼩且不需要稳定排序的场景,简单但性能较差。 |
| 8 | 基数排序 | 按位排序,⾸先对个位进⾏排序,再对⼗位、百位等进⾏排序,最终结果有序。 | O(d* (n+k)) | O(n+k) | 稳定 | 适⽤于 定⻓整数 或 定⻓字符串 的排序,适合⼤规模整数排序。 |
| 9 | 桶排序 | 将数据按范围划分为多个桶,每个桶内分别使⽤其他排序算法进⾏排序。 | O(n + k) | O(n + k) | 稳定 | 适⽤于 数据分布均匀 的场景,通过分桶降低排序复杂度。 |
| 10 | 计数排序 | 统计每个元素出现的次数,根据统计结果进⾏排序。 | O(n + k) | O(k) | 稳定 | 适⽤于范围较⼩且为整数的数据集,如成绩排序,时间复杂度低。 |
1. 快速排序
快速排序是一种基于分治法的⾼效排序算法,平均时间复杂度为 O(n log n),在⼤多数情况下表现最佳。
/** 快速排序的主函数
*快速排序的主函数
*@param {Array} arr -需要排序的数组
*returns {Array}-已排序的数组
**/
function quickSort(arr) {
// 基线条件:如果数组⻓度⼩于等于 1,则不需要排序
if (arr.length ( 1) {
return arr;
}
// 选择数组的中间元素作为基准(pivot),提⾼性能,减少最坏情况的发⽣
const pivotIndex = Math.floor(arr.length / 2);
const pivot = arr.splice(pivotIndex, 1)[0]; // 从数组中移除基准值
// 定义左右两个数组,分别存放⼩于和⼤于基准值的元素
let left = [];
let right = [];
// 遍历数组,将⼩于基准值的放⼊ left,⼤于基准值的放⼊right
for (let i = 0; i < arr.length; i++) {
if (arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
// 递归对左右两个⼦数组进⾏排序,并拼接结果
return quickSort(left).concat([pivot], quickSort(right));
}
2. 归并排序
归并排序是一种稳定的排序算法,时间复杂度为 O(n log n),适⽤于需要稳定排序的场景。
// 归并排序实现
function mergeSort(arr) {
if (arr.length <= 1) return arr; // 如果数组⻓度为 1 或更⼩,直接返回
const mid = Math.floor(arr.length / 2); // 取数组中间位置
const left = mergeSort(arr.slice(0, mid)); // 递归排序左半部分
const right =mergeSort(arr.slice(mid)); // 递归排序右半部分
return merge(left, right); // 合并排序后的数组
}
function merge(left, right) {
let result = [], i = 0, j = 0;
// 合并两个有序数组
while (i < left.length && j < right.length) {
if (left[i] < right[j]) {
result.push(left[i++]); // 将左侧较⼩元素加⼊结果
} else {
result.push(right[j++]); // 将右侧较⼩元素加⼊结果}
}
}
// 将剩余元素加⼊结果数组
return result.concat(left.slice(i)).concat(right.slice(j));
}
console.log(mergeSort([3, 6, 8, 10, 1, 2, 1])); // 输出:[1, 1, 2, 3, 6, 8, 10]
3. 堆排序
堆排序使⽤堆数据结构,时间复杂度为 O(n log n),不需要额外空间。
// 堆排序实现
function heapSort(arr) {
const len = arr.length;
// 构建最⼤堆
for (let i = Math.floor(len / 2) - 1; i>= 0; i--) {
heapify(arr, len, i);
}
// 将堆顶元素与最后一个元素交换,然后重新调整堆
for (let i = len - 1; i > 0; i--) {
[arr[0], arr[i]] = [arr[i], arr[0]]; // 交换堆顶与当前元素
heapify(arr, i, 0); // 调整剩余堆
}
return arr;
}
function heapify(arr, len, i) {
let largest = i; // 初始化最⼤值为⽗节点
let left = 2 * i + 1; // 左⼦节点
let right = 2 * i + 2; // 右⼦节点
// 如果左⼦节点⼤于⽗节点
if (left < len && arr[left] > arr[largest]) {
largest = left;
}
// 如果右⼦节点⼤于最⼤值
if (right < len && arr[right] > arr[largest]) {
largest = right;
}
// 如果最⼤值不是⽗节点,则交换并递归调整
if (largest!== i) {
[arr[i], arr[largest]] = [arr[largest], arr[i]];
heapify(arr, len, largest);
}
}
console.log(heapSort([3, 6, 8, 10, 1, 2, 1])); $ 输出:[1, 1, 2, 3, 6, 8, 10]
4. 插入排序
插⼊排序适⽤于⼩规模数据集,或者数据接近有序的情况,时间复杂度为 O(n²)。
//插入排序实现
function insertionSort(arr){
for (let i=1;i<arr.length;i+){
Let current=arr[i];//当前待排序的元素
Let j=i-1;
// 寻找当前元素的插入位置
while(j>0&& arr[j]>current){
arr[j+1]= arr[j];// 将较大的元素向右移动
j--;
}
arr[j+1]= current;// 插入当前元素
}
return arr;
}
console.log(insertionSort([3,6,8,10,1,2,1]));// 输出:[1,1,2,3,6,8,10]
5. 选择排序
选择排序每次选择未排序部分的最⼩元素进⾏交换,时间复杂度为 O(n²)。
// 选择排序实现
function selectionSort(arr) {
for (let i = 0; i < arr.length; i++) {
let minIndex = i; // 假设当前元素是最⼩值
for (let j = i + 1; j < arr.length; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j; // 找到更⼩的元素
}
}
if (minIndex !== i) {
[arr[i], arr[minIndex]] = [arr[minIndex], arr[i]]; // 交换最⼩值与当前位置的元素
}
}
return arr;
}
console.log(selectionSort([3, 6, 8, 10, 1, 2, 1])); // 输出:[1, 1, 2, 3, 6, 8, 10]
31. 链表
| 数据结构 | 定义 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 链表 | 由节点组成,每个节点包含数据和指向下⼀个节点的指针,节点不要求连续内存存储,适合动态内存管理。 | 1. 动态内存分配,插⼊、删除效率⾼,时间复杂度为O(1)(已知位置)。 2. ⽆需移动数据,只需修改指针。 | 1. 随机访问效率低,查找需线性遍历,时间复杂度为 O(n)。 2. 指针带来额外的内存开销。 | 动态数据管理、频繁插⼊删除场景,如队列、栈等。 |
| 单链表 | 每个节点只包含⼀个指针,指向下⼀个节点,数据只能单向访问。 | 1. 实现简单,占⽤内存⼩,插⼊、删除效率⾼。 2. 適合实现栈和队列等线性数据结构。 | 1. 只能单向遍历,⽆法反向访问,查找效率低,查找元素需从头遍历。 | 简单线性结构,如栈、队列等不需要双向遍历的应⽤。 |
| 双链表 | 每个节点包含两个指针,分别指向前⼀个和后⼀个节点,⽀持双向遍历,适合复杂的插⼊和删除操作。 | 1. 双向遍历,更灵活,插⼊、删除任意节点操作效率⾼,时间复杂度 O(1)。 2. 前向、后向操作都⽅便,适合复杂场景。 | 1. 内存占⽤较⾼,每个节点需要额外的指针。 2. 维护指针复杂,增加编程难度。 | 双向操作需求场景,如LRU缓存、双向队列等。 |
| 二叉树 | 每个节点最多有两个⼦节点,形成层次结构,⼴泛⽤于表示分层数据、搜索和排序。 | 1. 层次结构清晰,插⼊、删除、查找操作在平衡情况下时间复杂度为 O(log n)。 2. ⽀持多种遍历⽅式,如前序、中序、后序。 | 1. 不平衡时,性能退化为线性,时间复杂度为O(n)。 2. 维护平衡需要额外的逻辑和操作。 | 搜索、排序等场景,如表达式解析、数据存储和检索。 |
| 二叉搜索树 | 特殊的⼆叉树,左⼦节点⼩于根节点,右⼦节点⼤于根节点,常⽤于⾼效的搜索和动态集合操作。 | 1. 查找、插⼊、删除效率⾼,平衡状态下时间复杂度为O(log n)。 2. 中序遍历输出结果为有序序列。 | 1. 不平衡时性能退化,操作时间复杂度降为O(n)。 2. 需要额外维护树的平衡。 | 适⽤于⾼效动态搜索和数据排序场景,如数据库索引、内存存储管理。 |
32. 请简述前端中遇到过处理二进制的场景
总结:
- ⾼效传输与处理: ⼆进制数据的处理可以⼤幅提升前端的传输效率与性能,尤其在处理⼤⽂件、⾳视频流、实时通信等⾼数据量场景中尤为重 要。
- 核⼼数据结构: ArrayBuffer 和 TypedArray 是核⼼数据结构,提供了灵活的⼆进制数据处理能⼒,同时结合 Blob 实现⽂件相关操 作。
- 应⽤⼴泛: 涉及⽂件处理、流媒体、加密解码、协议解析、可视化等场景,前端的⼆进制数据处理已成为现代 Web 应⽤的关键技术。
| 场景 | 描述 | 常用数据结构 | 应用场景 |
|---|---|---|---|
| ⽂件上传与下载 | 在处理⽤户上传的⽂件(如图⽚、PDF等)时,前端需要将⽂件数据读取为⼆进制格式,或下载时处理⼆进制流。 | ArrayBuffer ,Blob | 上传⼤⽂件、预览⽂件、⽂件下载,尤其在需要⽂件流的场景下⾼效处理⼆进制⽂件。 |
| 图⽚、⾳视频资源处理 | 图像压缩、视频剪辑等涉及到直接操作⼆进制数据,通过 Blob 对象或⼆进制数据流对媒体资源进⾏处理。 | ArrayBuffer ,Blob | 媒体⽂件操作,如图像处理(压缩、裁剪)、⾳频或视频剪辑与合并,前端媒体资源优化。 |
| WebSocket ⼆进制传输 | 通过 WebSocket 传输⽂件、图像、⾳视频等⼆进制数据流以提⾼传输效率,尤其在实时性要求⾼的应⽤中。 | ArrayBuffer | 实时通讯,⽂件传输,视频流推送,在线游戏中的低延迟⼆进制数据传输。 |
| ⾳视频流处理 | 处理⾳频、视频数据的流式传输或解码操作,如通过 MediaSource API 进⾏视频流播放或⾳频流传输。 | ArrayBuffer ,TypedArray | WebRTC、⾳频录制、流媒体播放(直播、录播),⾼效处理⼤规模⾳视频流数据。 |
| Base64 编码的图⽚处理 | 将⼆进制图⽚数据转换为 Base64 格式⽤于嵌⼊HTML 或与后端传输,或从 Base64 恢复为⼆进制图⽚进⾏显示。 | Base64 ,Blob | 图⽚数据转换,⽤于减少 HTTP 请求次数,将图⽚直接嵌⼊⽹⻚或表单数据中进⾏传输。 |
| WebAssembly | 通过 WebAssembly 加载和执⾏编译后的⼆进制代码(如 C/C++),处理性能要求⾼的操作。 | ArrayBuffer | ⾼性能运算,如图形渲染、加密算法、⾳视频处理,以及需要与原⽣代码交互的场景。 |
| ⽂件压缩与解压缩 | 前端在处理上传或下载时进⾏⽂件压缩/解压缩,直接操作⼆进制⽂件流,提⾼传输效率。 | ArrayBuffer ,Blob | ⽂件压缩处理(如 ZIP、PDF),尤其是传输⼤⽂件时的带宽优化,适⽤于⽂件预处理。 |
| ⼆进制协议解析 | 处理和解析⾃定义⼆进制协议的数据流,通常在通信协议或物联⽹数据传输场景中使⽤。 | ArrayBuffer ,DataView | 物联⽹设备通信、传感器数据传输、⾃定义协议处理,⽤于解析和构造特定格式的⼆进制数据。 |
| 前端加密与哈希算法 | 在前端实现⽂件加密、哈希算法(如 SHA-256)时,需要处理⽂件的⼆进制数据块。 | ArrayBuffer ,Uint8Array | ⽂件加密、身份认证、数据完整性校验,前端需要对敏感数据进⾏安全性处理。 |
| ⼆进制数据的可视化 | 在⼤数据展示中,直接处理⼆进制数据流来⽣成图表或视觉效果。 | ArrayBuffer ,TypedArray | 数据可视化,尤其在处理⼤量实时流数据(如传感器数据、股票⾏情)时,利⽤⼆进制数据的⾼效性提升渲染性能。 |
12. 构建打包工具
1. webpack
Webpack 默认只会识别js⽂件和JSON ⽂件,但通过翻译官(Loaders),Webpack打包所有类型⽂件 loader: 翻译官 plugin: 增强webpack功能
1. 工作流程
1. 初始化:从 webpack.config.js 获取配置信息
↓
2. 解析⼊⼝:根据 entry 指定的⼊⼝⽂件,开始解析依赖图
↓
3. 模块解析:对每个⽂件进⾏依赖解析,并应⽤ loader 处理
↓
4. 编译模块:递归解析每个模块的依赖,⽣成依赖关系图
↓
5. 打包输出:根据依赖关系将模块打包为 bundle
↓
6. ⽣成输出⽂件:输出到指定的 output ⽬录
2. Webpack 热更新HMR
- **Webpack 监听⽂件变动:**Webpack 开启 HMR 后,会监听项⽬中的模块⽂件。当⽂件发⽣变化时,Webpack 通过 webpack-dev-server 或 webpack-dev-middleware 进⾏模块热替换,⽽不是刷新整个⻚⾯。
- **增量更新:**Webpack 只会重新打包变化的模块,并通过 HMR runtime(运⾏时)将新模块推送到浏览器。
- **模块热替换:**浏览器收到更新的模块后,通过 HMR 运⾏时动态地替换⻚⾯上的模块内容,⽽⽆需刷新整个⻚⾯。
- **模块回调:**如果⼀个模块启⽤了 HMR,那么它会有⼀个 module.hot.accept 函数,可以定义如何处理更新后的模块。
3. webpack打包优化
| 优化维度 | 核心优化建议 | 备注 |
|---|---|---|
| 代码分割 | 1. 使⽤ SplitChunksPlugin 将依赖分割成多个 bundle,优化加载速度 2. 通过 动态导⼊ (Dynamic Import) 按需加载模块 | 减少⾸屏加载时间,优化资源利⽤ |
| Tree Shaking | 1. 启⽤ Tree Shaking 移除未使⽤的代码 2. 配置 sideEffects: false 优化依赖库打包 | 减少打包体积,移除⽆⽤代码 |
| 缓存 | 1. 启⽤ 缓存,使⽤ Cache-Control 缓存策略 2. 为静态资源添加 hash 或 chunkhash | 提升重复访问时的加载速度 |
| 图⽚和资源优化 | 1. 使⽤ image-webpack-loader 等⼯具压缩图⽚ 2. 使⽤ url-loader 或 file-loader 处理静态资源 | 优化资源加载速度,减少资源占⽤ |
| 代码压缩 | 1. 启⽤ TerserPlugin 压缩 JavaScript ⽂件 2. 使⽤ css-minimizer-webpack-plugin 压缩 CSS | 减少打包体积,提升加载性能 |
| 多线程打包 | 1. 使⽤ thread-loader 启⽤多线程打包 2. 使⽤ parallel-webpack 提⾼打包速度 | 提升打包性能,减少打包时间 |
| 预编译依赖 | 1. 使⽤ DllPlugin 和 DllReferencePlugin 预编译依赖库 2. 缓存未变化的第三⽅库 | 减少构建时间,提⾼打包效率 |
| 按需加载 | 1. 配置 lazy loading 按需加载⾮关键资源 2. 使⽤ import( ) 动态导⼊模块 | 优化资源利⽤,减少不必要的加载 |
| 使⽤⽣产模式 | 1. 使⽤ mode: 'production' 启⽤⽣产环境配置 2. 启⽤ webpack.DefinePlugin 配置环境变量 | 启⽤默认优化选项,优化打包效果 |
| CSS 和 JS 分离 | 1. 使⽤ MiniCssExtractPlugin 分离 CSS ⽂件 2. 避免将所有 CSS 打包到⼀个⽂件中,使⽤按需加载 | 减少⾸屏加载时间,提升加载性能 |
| 模块联邦 (Module Federation) | 1. 使⽤ Module Federation 共享跨应⽤模块 2. 在多个项⽬之间共享依赖库 | 提升模块复⽤,减少重复打包依赖 |
| DevTool 优化 | 1. 在开发环境中使⽤ cheap-module-source-map 提升构建速度 2. 在⽣产环境中禁⽤ source-map 减少体积 | 优化开发体验,减少⽣产环境体积 |
4. webpack实现原理
| 模块/步骤 | 源码级别实现原理 | 实际应⽤场景 |
|---|---|---|
| 1. 初始化阶段 | 通过 webpack() ⽅法创建 Compiler 实例,读取配置⽂件(包括 entry 、output 、loaders 、plugins 等),调⽤ run ⽅法开始打包流程。 | 项⽬启动时,读取 webpack.config.js 中的所有配置信息,设置打包环境。 |
| 2. Compiler 和 Tapable | Compiler 是 Webpack 的核⼼引擎,基于 Tapable (事件发布订阅库)调度钩⼦函数,插件机制依赖于此。 | 插件系统通过 compiler.hooks 插⼊⾃定义逻辑,实现如热更新、分析等功能。 |
| 3. 模块解析 | Webpack 使⽤ enhanced-resolve 解析模块路径,处理 import 和 require ,依据resolve 配置项(如 alias 、extensions 等)确定模块路径。 | 使⽤ alias 重定向模块路径,或通过extensions 补全模块后缀名等场景。 |
| 4. Loader 处理 | Webpack 通过配置 rules 查找合适的 loader ,通过链式调⽤转换资源⽂件(如 ES6 转换为 ES5)。 | 使⽤ babel-loader 转换 JavaScript,或使⽤ css-loader 处理 CSS ⽂件。 |
| 5. 依赖图构建 | Compilation 递归解析模块依赖,构建完整依赖图,创建 Module 实例并递归分析依赖。 | 项⽬中使⽤模块化开发,Webpack 根据依赖图⾃动处理模块间引⽤关系。 |
| 6. Code Splitting | 通过识别动态 import() 实现代码分割,⽣成新 chunk ,按需加载。 | 在⼤型项⽬中,使⽤代码分割提⾼性能,按需加载不同模块。 |
| 7. Tree Shaking | Webpack 通过 ES6 静态分析移除未使⽤代码, sideEffects 配置⽀持。 | 通过 Tree Shaking 移除未引⽤模块,减⼩包体积,优化输出。 |
| 8. 插件机制 | 基于 Tapable 的事件流系统,插件通过 apply 注册到⽣命周期钩⼦上扩展功能。 | 使⽤如 HtmlWebpackPlugin ⽣成 HTML,或⾃定义插件实现⽇志分析。 |
| 9. 输出阶段 (Emit) | 根据 output 配置,将打包后的 chunks 写⼊⽂件系统,使⽤ fs 模块处理输出。 | 输出打包后的 JS/CSS ⽂件到指定⽬录,⽣成hash 版本号确保缓存更新。 |
| 10. 热更新 (HMR) | 通过 webpack-dev-server 和 HotModuleReplacementPlugin 实现模块增量打包,推送⾄浏览器,替换旧模块。 | 开发环境中修改代码实时⽣效,⻚⾯不刷新,提升开发效率。 |
| 11. 缓存 (Caching) | Webpack 通过模块、chunk 的 hash 持久化缓存,减少重复构建时间。 | 使⽤ cache 减少重复构建时间,适⽤于⼤型项⽬。 |
2. Vite
| 模块/步骤 | 源码级别实现原理 | 实际应⽤场景 |
|---|---|---|
| 1. 启动流程 | Vite 基于 esbuild 进⾏超快的依赖预构建,启动时通过 vite.config.js 读取配置,创建 Server 实例,处理静态资源服务和热更新。 | 启动项⽬时,Vite 在开发模式下使⽤原⽣ ESM 进⾏模块加载,减少打包时间,提升启动速度。 |
| 2. 依赖预构建 | 使⽤ esbuild 作为依赖解析器,将第三⽅依赖(如 node_modules 中的包)预构建为浏览器友好的 ESM 格式,加快后续加载速度。 | 在项⽬启动时预先打包第三⽅依赖,如 Vue、React等库,加快依赖解析,提升热更新性能。 |
| 3. 模块热更新 (HMR) | 通过 WebSocket 实现 HMR, Vite 只会重编译被修改的模块,利⽤ import.meta.hot 来局部更新模块,不刷新整个⻚⾯。 | 在开发环境中,修改源代码时可以实时更新浏览器⻚⾯⽽不需要完全刷新,极⼤提升开发效率。 |
| 4. 按需加载 | Vite 基于 ESM 原⽣⽀持模块按需加载,在代码运⾏时只会加载被使⽤到的模块,且不需要进⾏额外的配置。 | 在⼤型应⽤中,减少初始加载时间,按需加载模块,提升运⾏时性能。 |
| 5. 构建阶段 | Vite 使⽤ Rollup 作为⽣产构建⼯具,解析vite.config.js 的 build 配置,将开发时的 ESM 模块打包为优化的⽣产环境⽂件。 | 在⽣产环境中,Vite 会使⽤ Rollup 进⾏打包,⽣成浏览器友好的 JS、CSS ⽂件,⽀持代码分割与 Tree Shaking。 |
| 6. 插件机制 | Vite 的插件系统与 Rollup 兼容,基于 plugin 的钩⼦机制,开发者可以⾃定义插件来扩展 Vite 的功能。 | 开发者可以通过编写⾃定义插件扩展 Vite 的功能,例如⽀持新语法、⽂件格式转换等。 |
| 7. ⽂件监听与缓存 | Vite 使⽤ chokidar 监听⽂件变化,在 HMR 过程中缓存已编译的模块,避免重复编译,加快响应速度。 | 通过⽂件监听与模块缓存机制,加快代码热更新的响应速度,尤其在⼤规模项⽬中⾮常有效。 |
| 8. ESM⽀持 | Vite 使⽤浏览器原⽣ ESM 加载模块,在开发环境中不需要打包,直接利⽤浏览器模块能⼒实现快速启动与更新。 | 通过原⽣ ESM 进⾏模块化开发,避免了打包时间的消耗,极⼤提升了开发效率,尤其在开发初期。 |
| 9. 快速构建 | 利⽤ esbuild 的⾼效编译能⼒,将源码快速转换为浏览器可以理解的格式,极⼤减少开发环境下的构建时间。 | 在开发环境下进⾏代码改动时,通过 esbuild 的极速编译能⼒,可以⽴即看到⻚⾯变化。 |
3. webpack和vite区别
| 对比点 | Webpack 实现原理 | Vite 实现原理 | 实⽤性差异 |
|---|---|---|---|
| 打包模式 | 基于打包概念,构建依赖图,将模块打包为⼀个或多个⽂件。 | 基于原⽣ ESM,开发时不打包,利⽤浏览器按需加载模块。 | Vite 更快,Webpack 更适合复杂打包需求。 |
| 模块解析 | 使⽤内部 enhanced-resolve 递归解析依赖,⽣成依赖图。 | 依赖浏览器 ESM,按需加载,⽆需复杂依赖解析。 | Vite 开发时不依赖复杂依赖解析,启动速度快。 |
| 依赖预构建 | 每次构建递归解析所有依赖,耗时较⻓。 | 启动时⽤ esbuild 预构建依赖,缓存结果,加快后续加载。 | Vite ⼤型项⽬启动速度显著提升。 |
| 热更新 (HMR) | 基于 webpack-dev-server ,重新编译依赖树,通过 WebSocket 刷新⻚⾯。 | 基于 WebSocket,只更新修改的模块,利⽤ ESM 进⾏模块热替换。 | Vite 热更新速度明显快,尤其在⼤型项⽬中。 |
| 编译速度 | 逐个模块编译,依赖复杂的依赖图解析,编译时间⻓。 | 使⽤ esbuild ,开发时不打包,极快编译速度。 | Vite 开发时编译速度远超Webpack。 |
| 构建⼯具 | 内置插件系统,依赖 Compiler 和 Compilation 进⾏复杂打包。 | 使⽤ Rollup 作为构建⼯具,⽀持代码分割与按需加载。 | Webpack 更适合⾼度定制的构建,Vite 适合现代化开发和快速部署。 |
| 插件机制 | 基于 Tapable 事件流,插件通过 apply 注册钩⼦。 | 兼容 Rollup 插件系统,插件通过 rollup-plugin API 扩展。 | Vite 插件开发更简单灵活,Webpack 插件⽣态成熟。 |
| 缓存机制 | 通过 cache 选项缓存模块,增量更新时依赖 Module 缓存。 | 启动时缓存依赖预构建结果,热更新时模块不会重新编译。 | Vite 缓存机制轻量⾼效,Webpack 缓存适⽤于复杂构建。 |
| ⽣产环境优化 | 提供 Tree Shaking、代码分割、懒加载、压缩优化等⾼级配置,⽀持复杂项⽬需求。 | ⽣产时基于 Rollup ⽀持 Tree Shaking,默认开箱即⽤,⽆需复杂配置。 | Webpack 适合复杂应⽤,Vite 更轻量,适合现代化应⽤场景。 |
4. babel工作原理
使⽤ES6转ES5举例
| 过程 | 实现步骤 |
|---|---|
| 1. 解析 | 1. 使⽤ Babylon 解析源码为 AST(抽象语法树) 2. 将代码结构化为可操作的节点 |
| 2. 转换 | 1. 使⽤ Babel 插件对 AST 进⾏修改 2. 执⾏语法转换,⽣成兼容⽬标环境的代码 |
| 3. 生成 | 1. 使⽤ @babel/generator 将 AST 转回 JavaScript 代码 2. 输出⽬标代码 |
1. AST
总结
- **编译器与代码转换:**AST 是现代编译器(如 Babel、TypeScript)中不可或缺的核⼼⼯具,通过解析源代码并转换为可执⾏的⽬标代码, 适⽤于代码兼容性(如 ES6+ 转 ES5)、语法升级等场景。
- **代码检查与分析:**AST 能深度分析代码结构,应⽤于代码规范检查⼯具(如 ESLint)、格式化⼯具(如 Prettier)中,⽤于规范代码⻛ 格、避免潜在错误。
- **代码优化:**在编译阶段,AST ⽀持⾼级优化操作,如 Tree-shaking、死代码消除、性能优化等,提升代码运⾏效率和质量。
- **⾃动化重构:**通过 AST,可以实现代码重构和⾃动化⼯具(如 Prettier),优化代码的结构和⼀致性
2. AST核心API
| API 名称 | 功能描述 | 应⽤场景 | 优势 | 劣势 |
|---|---|---|---|---|
| parse | 将源代码转换为 AST | 代码规范⼯具(如 ESLint)、代码格式化⼯具(如 Prettier) | 能精准解析代码,⽀持多语⾔ | 对⼤⽂件处理较慢 |
| traverse | 遍历 AST,操作每个节点 | 代码转换⼯具(如 Babel),⽤于重构代码 | 灵活⾼效,⽀持对AST 任意操作 | 需要深度理解 AST,复杂遍历影响性能 |
| generate | 将 AST ⽣成源代码 | 代码压缩、格式化⼯具,⽀持代码⽣成 | 保持代码结构,适合多种转换场景 | ⼤型 AST ⽣成过程耗时较⻓ |
| visit | 访问特定 AST 节点类型 | 编译器中针对特定节点的分析,如统计函数调⽤或变量声明 | 精确⾼效操作特定节点 | ⾮⽬标节点⽆法处理,缺乏全局优化 |
| types | 创建、判断、转换 AST 节点类型 | Babel 插件中⽤于类型判断和转换(如箭头函数转普通函数) | 提供丰富类型判断,⽀持精确转换 | 复杂类型定义可能导致误判 |
| transform | 转换 AST 并输出结果 | 编译器⼯具链中,⽤于代码转换(如 ES6 转 ES5) | 丰富转换功能,⽀持⾃定义逻辑 | 转换链过⻓时性能下降,⽣成代码不够⾼效 |
| scope | 处理作⽤域,分析变量和函数的声明与引⽤ | 编译器优化、Tree-shaking、死代码消除 | 精确处理作⽤域关系,提升代码执⾏效率 | 分析复杂代码时增加编译时⻓ |
| template | 快速创建 AST 模板 | 在 Babel 中⽤于快速⽣成代码模板(如函数调⽤、变量声明) | 提升开发效率,简化⼿动创建 AST | 适⽤场景有限,复杂结构不够灵活 |
13. Electron
| 序号 | 面试题 | 详细描述 |
|---|---|---|
| 1 | 什么是 Electron? | Electron 是一个用于构建跨平台桌面应用的框架,使用 Web 技术(如 HTML、CSS、JavaScript)结合 Node.js 和 Chromium 来构建应用程序。它允许开发者使用前端技术来构建与桌面原生应用类似的 UI,并提供对操作系统底层功能的访问。主要特点包括: 1. 跨平台:支持 Windows、macOS、Linux。 2. 基于 Web 技术。 3. Node.js 支持。 |
| 2 | 主进程和渲染进程的区别是什么? | Electron 应用由两个主要进程组成: 1. 主进程 (Main Process):负责管理应用的生命周期(如创建和管理窗口)、与操作系统交互等。主进程可以访问所有 Node.js API。 2. 渲染进程 (Renderer Process):每个窗口运行在自己的渲染进程中,渲染进程负责窗口的 UI 渲染。渲染进程使用 Chromium 渲染 HTML、CSS 和 JavaScript,并与用户交互。渲染进程中的 JavaScript 代码默认不能直接使用 Node.js API,除非显式启用。 两者通过 IPC(进程间通信)进行通信。 |
| 3 | Electron 中如何进行进程间通信 (IPC)? | IPC (Inter-Process Communication) 是 Electron 中主进程和渲染进程之间通信的方式。通过 IPC,可以实现主进程和渲染进程之间的数据交互: 1. ipcRenderer:渲染进程中使用,用于发送消息到主进程。2. ipcMain:主进程中使用,用于接收来自渲染进程的消息并处理请求。使用方法: 渲染进程: ipcRenderer.send('channel', data)主进程: ipcMain.on('channel', (event, data) => { ... }) |
| 4 | Electron 如何实现自动更新? | Electron 提供了一个自动更新的机制,通过 electron-updater 模块实现自动更新。主要步骤如下:1. 在主进程中使用 autoUpdater 监听更新事件,如 update-available、update-downloaded。2. 下载最新版本的应用并提示用户安装。 3. 自动更新通过查询更新服务器的更新信息,检查是否有新版本发布。 使用 autoUpdater.checkForUpdates() 检查更新,下载完成后调用 autoUpdater.quitAndInstall() 安装新版本并重启应用。 |
| 5 | 如何在 Electron 中实现多窗口应用? | 通过 BrowserWindow 创建和管理多个窗口,每个窗口运行在自己的渲染进程中:1. 使用 new BrowserWindow() 创建新窗口,每个窗口独立运行渲染进程。2. 使用 window.open() 打开新的窗口,适合在应用内跳转到新窗口的场景。3. 通过 webContents 获取和控制窗口的内容。4. 窗口间通过 IPC 实现通信,或者通过 window.webContents 控制多个窗口间的交互。 |
| 6 | Electron 中如何操作本地文件系统? | Electron 中可以使用 Node.js 的 fs 模块访问和操作本地文件系统。渲染进程中默认不能直接使用 Node.js 模块,但可以通过 IPC 与主进程通信,让主进程执行文件操作。常用的文件操作包括:1. 读取文件: fs.readFile(path, callback)2. 写入文件: fs.writeFile(path, data, callback)3. 删除文件: fs.unlink(path, callback)Node.js 模块可以在主进程中直接使用,主进程可以完全控制文件的读写操作。 |
| 7 | Electron 中的打包和发布过程是怎样的? | Electron 提供了多种工具用于应用的打包和发布: 1. electron-builder:最常用的打包工具,支持打包应用为 .exe、.dmg 和 .AppImage,并可以为应用签名。2. electron-packager:用于将 Electron 应用打包成跨平台的可执行文件。3. 打包时可以指定应用的图标、版本信息、平台等。 4. 通过 package.json 配置打包选项,并使用命令 npm run build 进行打包。 |
| 8 | 如何提升 Electron 应用的安全性? | 为了防止渲染进程执行恶意代码,Electron 提供了多种安全措施: 1. 禁用 Node.js 集成:通过 nodeIntegration: false 防止渲染进程直接访问 Node.js API。2. 启用沙盒模式 (sandbox):通过 sandbox: true 启用沙盒进程,提升安全性。3. 使用 contextIsolation:防止渲染进程访问 Electron API,提高安全性。4. 禁用 remote 模块:通过 remote 模块可能导致安全问题,建议禁用并使用 IPC 进行通信。 |
| 9 | 如何在 Electron 中使用本地数据库? | Electron 支持多种本地数据库,通过 Node.js 模块可以轻松与数据库交互: 1. SQLite:使用 sqlite3 模块操作 SQLite 数据库,适合需要轻量级数据库的场景。2. NeDB:适用于简单项目的小型嵌入式数据库。 3. IndexedDB:在渲染进程中使用,适合在前端存储大量数据,通常与浏览器 API 一起使用。 4. 文件数据库:如 JSON 数据存储,适用于简单数据存储的场景。 |
| 10 | 如何优化 Electron 应用的性能和内存使用? | 优化 Electron 应用性能和内存使用的方法包括: 1. 减少渲染进程的负担:避免渲染进程执行大量计算,将计算任务放在主进程或 Web Worker 中执行。 2. 定期清理内存:使用 session.clearCache() 清理渲染进程缓存,减少内存消耗。3. 使用懒加载:按需加载模块和窗口,避免一次性加载所有资源。 4. 减少 DOM 操作:减少渲染进程中的 DOM 更新和复杂的 UI 交互,降低渲染负担。 |
| 11 | 如何调试 Electron 应用? | 调试 Electron 应用时,可以通过以下方法: 1. 开发者工具:使用 win.webContents.openDevTools() 打开开发者工具,调试渲染进程。2. 控制台日志:使用 console.log() 在主进程和渲染进程中输出调试信息。3. remote 调试:通过 Chrome DevTools 远程调试应用。 4. electron-debug:可以为 Electron 应用提供更多调试功能。 |
| 12 | Electron 应用的生命周期是什么? | Electron 应用的生命周期事件包括: 1. ready:应用初始化完成后触发,通常用于创建窗口。2. window-all-closed:所有窗口关闭时触发,Windows 平台通常会调用 app.quit() 退出应用。3. before-quit:应用即将退出时触发,可以用于保存状态或清理资源。4. will-quit:应用退出时触发,应用退出的最后阶段。 |
| 13 | 如何处理 Electron 应用中的跨域问题? | Electron 应用默认启用了跨域支持,可以通过以下方式处理跨域问题: 1. 使用 webSecurity: false 禁用 Web 安全策略,但不推荐在生产环境中使用。2. 使用 protocol 模块自定义协议,绕过跨域限制。3. 通过主进程代理请求,将跨域请求转发到主进程处理。 4. 使用 CORS(跨源资源共享)在后端配置允许的跨域请求。 |
| 知识点 | 优化后的详细说明 | 优化后的项目实战经验 |
|---|---|---|
| 基础架构 | 是一个结合 Chromium 和 Node.js 的桌面应用框架,基于双进程架构:主进程负责系统资源调用、窗口管理和生命周期控制;渲染进程负责 UI 渲染和用户交互。核心优势在于可复用 Web 技术栈,并通过 Node.js 与操作系统进行交互。 | 在项目中,为确保 Electron 应用的性能与稳定性,主进程集中处理与操作系统相关的重任务,渲染进程保持轻量化,专注于 UI 和交互,避免阻塞。 |
| 主进程 | 主进程负责控制应用生命周期、窗口创建、菜单、托盘、通知等。它还可以直接调用 Node.js API 与操作系统交互,如文件系统、网络请求等。主进程应保持简单,复杂逻辑尽量通过子进程或渲染进程完成,以保持主进程响应速度。 | 在一个项目中,为了实现文件操作的异步执行,我们使用了子进程处理密集型任务,并通过 IPC 与主进程通信,避免主进程卡顿。 |
| 渲染进程 | 渲染进程类似于浏览器中的 Web 页面,运行在 Chromium 环境下。渲染进程主要用于处理应用的 UI 部分,使用 HTML、CSS 和 JavaScript 构建页面。通过 IPC 与主进程通信,将复杂计算移交给主进程或使用 Web Worker,可以有效优化 UI 的响应速度。 | 开发中,我们结合 React/Vue 框架构建复杂的单页面应用(SPA),通过 Web Worker 处理后台计算,保证 UI 的流畅性。 |
| IPC 通信 | 主进程与渲染进程通过 IPC(Inter-Process Communication)进行异步通信。Electron 提供了 ipcMain 和 ipcRenderer 模块用于发送和接收消息。使用单向和双向通信实现模块间通信,同时应避免频繁通信造成性能瓶颈。 | 在复杂业务场景下,例如文件上传和状态更新,主进程通过 IPC 接收渲染进程请求并反馈处理结果,减少通信频率以避免资源占用过高。 |
| 窗口管理 | BrowserWindow 是 Electron 用于创建和管理窗口的核心模块。通过该模块可以设置窗口属性(大小、位置、透明度等)以及窗口行为(最大化、最小化、关闭等)。多窗口应用开发时需注意窗口的独立性和通信,以及窗口关闭时的资源释放。 | 在多窗口应用开发中,确保每个窗口独立,使用 session 和 localStorage 共享数据,通过 win.on('close') 释放窗口资源,提升性能。 |
| 安全性 | Electron 提供的功能强大,但也带来了安全隐患。启用 contextIsolation 和 sandbox 限制渲染进程的权限,禁用 nodeIntegration 避免恶意代码访问 Node.js API,实现内容安全策略(CSP)防止 XSS 攻击,限制远程资源加载,确保用户数据的安全性。 | 实际项目中,禁用了 nodeIntegration 并使用 preload 脚本处理安全通信,配合 CSP 白名单确保只加载可信的资源,减少攻击面。 |
| 自动更新 | 自动更新是 Electron 应用的重要功能之一。通过 electron-updater 实现自动更新,支持增量更新以减少更新包大小,配合更新服务端,主进程监听更新事件,自动下载新版本并提示用户安装,用户体验友好且维护简单。 | 为确保平台包自动更新顺利进行,我们在项目中实现了增量更新机制,配置了 GitHub 作为更新服务器,并在发布前通过 CI/CD 流程进行全量测试。 |
| 打包和发布 | Electron 支持通过 electron-builder 和 electron-packager 进行打包发布,生成多个平台的安装文件(如 .exe、.dmg),打包时可进行定制,如图标、启动脚本等,为不同平台配置 extraResources 和 extraFiles,以确保资源文件的正确打包。 | 在一个企业级项目中,我们使用 electron-builder 生成多平台安装包,并配置了 extraResources 和 extraFiles 以确保资源文件的正确打包。 |
| 原生 API 调用 | Electron 提供与操作系统交互的能力,允许调用原生 API,如系统通知、剪贴板、文件拖放等。通过 Node.js 的 API 可以直接进行文件操作、网络请求等,在多平台应用中需根据不同系统进行适配,如 Windows 和 macOS 的通知方式不同。 | 实际开发中,我们通过 Electron 的 Notification API 实现了跨平台通知功能,适配 Windows 和 macOS 的不同通知格式,提供一致的用户体验。 |
| 上下文隔离 | 上下文隔离用于提升安全性,确保渲染进程运行在与 Electron 主进程分离的沙盒环境中。通过启用 contextIsolation: true,可以阻止渲染进程直接访问 Node.js API,有效避免 XSS 和注入攻击。 | 在实际项目中,我们为渲染进程启用 contextIsolation,同时通过 preload 脚本安全地暴露 API 与主进程交互,有效阻止渲染进程中潜在的安全威胁。 |
| 持久化存储 | Electron 支持多种持久化存储方式,如 localStorage、IndexedDB 以及通过文件系统实现的持久化存储。对于需要存储大量数据的应用,建议使用 SQLite 等数据库,确保数据的高效读写。 | 在实际项目中,为了持久化用户设置和应用状态,我们使用了 electron-store 作为轻量级存储解决方案,并结合 SQLite 存储大量用户数据。 |
| 快捷键绑定 | Electron 允许通过 globalShortcut 注册全局快捷键,可以在系统范围内拦截用户按键事件。这对于需要全局操作的桌面应用非常有用,但应避免与系统快捷键冲突,并在应用关闭时注销快捷键绑定。 | 在开发中,通过 globalShortcut 注册了应用内快捷键功能,结合 clipboard 实现了用户自定义截图的快捷操作,极大提升了使用便捷性。 |
| 原生菜单和托盘 | Electron 支持创建与操作系统集成的原生菜单和托盘图标。可以使用 Menu 和 Tray API 实现右键菜单、系统托盘的快捷操作等功能。对于需要长时间后台运行的应用,托盘图标可以提供高效的功能入口,用户可以直接从托盘控制应用状态。 | 实际项目中,我们为后台运行的长时间任务应用开发了托盘图标,通过 Tray API 实现了功能菜单快捷入口,用户可以直接从托盘控制应用状态。 |
| 多平台支持 | Electron 支持跨平台桌面应用开发,Windows、macOS 和 Linux 共享相同代码库。为确保应用在不同平台上的行为一致,需根据平台差异配置窗口行为、文件路径等。使用 process.platform 区分平台,并使用适配器模式的代码差异处理。 | 在多平台开发中,我们根据 process.platform 区分不同系统的行为,例如在 macOS 上启用透明窗口,在 Windows 上支持任务栏动态更新。 |
| 调试工具 | Electron 内置了 Chromium 的开发者工具,允许开发者在渲染进程中调试代码。此外,还可以使用外部调试工具如 VS Code 远程调试主进程。调试时应注意主进程和渲染进程的不同错误日志,并确保性能分析工具的正确使用。 | 在开发大型应用时,我们通过 DevTools 进行性能分析和调试,使用 chrome://inspect 对渲染进程进行详细性调试。 |
Electron 实际项⽬应⽤
| 系统业务模块 | 功能描述 | 具体实现功能 | 技术实现方案 |
|---|---|---|---|
| 用户管理 | 处理用户的注册、登录、权限管理。 | 1. 用户注册、登录。 2. 角色权限分配。 3. 用户数据持久化和管理。 | 1. 使用 Electron 和 Node.js 搭建后端 API,处理用户注册与登录逻辑。 2. 使用 JWT 或 OAuth2 进行用户身份验证。 |
| 数据可视化 | 展示系统中收集的各类数据,支持动态图表显示和实时更新。 | 1. 支持不同类型图表(折线图、柱状图等)。 2. 实时更新数据源,并动态更新图表展示。 | 1. 使用 ECharts 或 D3.js 结合渲染进程实现数据可视化。 2. 使用 WebSocket 实现实时数据通信。 |
| 文件管理 | 允许用户上传、下载、查看本地文件,并支持大文件断点续传。 | 1. 文件上传、下载功能。 2. 支持大文件分片上传和断点续传。 3. 文件操作历史记录和版本控制。 | 1. 使用 fs 模块与操作系统文件系统交互。2. 使用 stream 和 multiparty/form-data 处理大文件上传和下载。 |
| 系统通知 | 提供系统级别的消息通知,用户可以收到任务提醒、操作提示等。 | 1. 系统消息通知功能。 2. 通知优先级和提醒设定。 | 1. 使用 Electron 的 Notification API 实现跨平台系统通知功能。 2. 配合 Node.js 处理后台定时任务提醒。 |
| 多窗口管理 | 支持多窗口操作,允许用户在不同窗口中处理不同任务。 | 1. 创建、管理多个窗口。 2. 支持窗口间通信和状态共享。 | 1. 使用 BrowserWindow 创建和管理多个窗口。2. 使用 ipcMain 和 ipcRenderer 实现窗口之间的通信。 |
| 快捷键管理 | 支持用户自定义快捷键,提升操作效率。 | 1. 系统级快捷键绑定。 2. 用户自定义快捷键设置。 | 1. 使用 Electron 的 globalShortcut API 实现全局快捷键绑定。2. 提供设置界面让用户自定义快捷键。 |
| 自动更新 | 应用的自动更新功能,确保用户始终使用最新版本。 | 1. 应用版本检测和更新下载。 2. 支持增量更新,减少更新包体积。 | 1. 使用 electron-updater 实现跨平台自动更新功能。2. 使用增量更新机制减少更新时的下载量,提升更新速度。 |
| 持久化存储 | 应用需要保存用户的设置、缓存数据、历史记录等。 | 1. 用户偏好设置持久化。 2. 离线模式下的数据缓存。 3. 用户操作历史的保存。 | 1. 使用 electron-store 处理小型数据持久化。2. 对于大型数据,使用 SQLite 或 IndexedDB 进行持久化存储。 |
| 权限管理 | 针对不同用户分配不同的操作权限,控制用户访问系统的不同模块和功能。 | 1. 用户角色与权限配置。 2. 权限校验和动态控制用户界面显示内容。 | 1. 使用基于角色的访问控制(RBAC),结合 JWT 进行用户身份验证。 2. 渲染进程动态显示或隐藏界面元素。 |
| 日志与监控 | 对用户的操作日志、系统错误进行监控和记录,支持错误报警功能。 | 1. 记录用户操作日志和系统错误。 2. 错误发生时,实时告警并发送通知。 | 1. 使用 winston 记录用户日志并生成日志文件。2. 通过 Electron 与第三方日志系统(如 Sentry)集成,进行错误监控和告警。 |
| 数据库交互 | 允许应用与后端数据库进行交互,支持数据库查询和数据同步。 | 1. 数据库查询、增删改操作。 2. 数据同步和缓存。 | 1. 使用 Electron 中的 Node.js 连接 MySQL、MongoDB 等后端数据库。 2. 使用 axios 或 fetch 与后端 API 交互。 |
| 跨平台支持 | 应用能够在 Windows、macOS 和 Linux 系统上无缝运行,并支持各平台的特性差异。 | 1. 统一代码库支持多平台。 2. 针对不同操作系统的功能差异(如托盘、通知)进行适配。 | 1. 使用 process.platform 检测平台,动态加载不同的模块。2. 针对 Windows 和 macOS 不同的托盘图标进行适配。 |
| 窗口最小化到托盘 | 用户可以将应用最小化到系统托盘以便后台运行,提供便捷的托盘菜单操作。 | 1. 将窗口最小化到系统托盘。 2. 在托盘菜单中提供快捷操作。 | 1. 使用 Tray API 创建托盘图标和菜单。2. 通过 ipcRenderer 实现托盘菜单与主窗口的交互。 |
| 在线与离线模式 | 支持用户在没有网络连接的情况下使用应用,并在恢复网络后同步数据。 | 1. 离线数据缓存与同步。 2. 恢复网络连接后数据同步至服务器。 | 1. 使用 IndexedDB 或 localStorage 高效缓存离线数据。2. 使用 Service Worker 管理网络状态变化并触发数据同步。 |
| 主题和个性化设置 | 用户可以切换不同的主题风格,并自定义界面外观。 | 1. 提供不同的 UI 主题选择。 2. 支持用户自定义界面颜色和布局。 3. 保存用户的个性化设置到本地。 | 1. 使用 CSS 变量或 CSS-in-JS 实现动态主题切换。 2. 保存用户的个性化设置到 electron-store 进行持久化。 |
14. 3D
| 序号 | 解决方案 | 应用场景 | 特点 | 可落地步骤 |
|---|---|---|---|---|
| 1 | Three.js | 3D 渲染、产品展示、建筑设计、数据可视化 | 1. 封装复杂的 WebGL API,提供高层次的 3D 渲染接口,适合快速构建 3D 应用。 2. 支持多种 3D 模型格式(GLTF、OBJ 等),易于使用。 3. 提供场景、相机、光照、材质等丰富的 3D 功能模块。 | 1. 初始化 Three.js 场景:创建一个 THREE.Scene() 对象作为渲染的根节点。 2. 设置相机:使用 THREE.PerspectiveCamera() 创建相机,设置视角和可视范围。 3. 渲染器:使用 THREE.WebGLRenderer() 创建渲染器,将 3D 场景渲染到 HTML Canvas 上。 4. 加载 3D 模型:使用 GLTFLoader 或 OBJLoader 加载模型资源,添加到场景中。 5. 设置光照:添加 THREE.AmbientLight(环境光)和 THREE.DirectionalLight(方向光)实现模型的光照效果。 6. 交互控制:通过 OrbitControls 实现缩放、旋转和拖动功能,使用户能自由操作 3D 场景。 7. 渲染循环:使用 requestAnimationFrame() 实现逐帧渲染,确保场景的实时更新。 8. 窗口适配:监听浏览器窗口大小变化,调用渲染器的 setSize() 方法调整渲染尺寸,同时调整相机的长宽比。 |
| 2 | Canvas + 2D/3D 混合 | 2D 和 3D 结合的可视化应用,如复杂的 3D 数据可视化仪表盘和地图等场景。 | 1. 结合 Canvas 2D 绘图和 Three.js 3D 渲染,实现复杂的 2D 和 3D 场景。 2. 适合需要 2D 图表和 3D 场景互动的场景,如地图和数据可视化。 | 1. 初始化 2D Canvas:通过 canvas.getContext('2d') 获取 2D 上下文,绘制 2D 图表或 UI 内容。 2. 初始化 Three.js 3D 场景:使用 THREE.Scene() 创建 3D 场景,使用 THREE.PerspectiveCamera() 和 THREE.WebGLRenderer() 渲染 3D 对象。 3. 同步 2D 与 3D 交互:通过共享的状态或事件监听,将 2D 图表的更新与 3D 场景的变化关联起来。例如,在点击 2D 图表时,调整 3D 场景中的摄像机位置。 4. 渲染循环:使用 requestAnimationFrame() 实现 2D 和 3D 场景的同步渲染更新,确保两者的动画效果一致。 5. 交互事件处理:对 2D 和 3D 场景中的用户输入(如点击、拖动等)进行监听,确保交互流畅,并根据用户操作实时更新场景。 |
15. websocket
1. 3种方案
| 序号 | 解决方案 | 应用场景 | 特点 | 核心使用 |
|---|---|---|---|---|
| 1 | Socket.IO | 实时聊天应用、多人协作编辑、实时通知系统 | 1. 提供 WebSocket 的高级封装,支持自动降级为其他协议(如 HTTP 长轮询)以保持连接。 2. 内置重连机制,支持高并发场景,广泛应用于实时互动、实时通知场景。 | 1. 安装依赖:npm install socket.io。2. 创建 WebSocket 连接: const socket = io('ws://server')。3. 监听事件:使用 socket.on('message', callback) 监听服务器推送的数据。4. 发送数据:通过 socket.emit('event', data) 向服务器发送数据。5. 重连机制:Socket.IO 内置自动重连功能,默认情况下自动重连。 |
| 2 | ws (Node.js) | 高性能实时通信、后台服务与客户端实时交互 | 1. 轻量级 WebSocket 库,主要用于 Node.js 后端开发。 2. 支持 WebSocket 原生 API,适合高性能需求的场景。 | 1. 安装依赖:npm install ws。2. 创建 WebSocket 服务器: const WebSocket = require('ws'); const wss = new WebSocket.Server({ port: 8080 });。3. 监听连接: wss.on('connection', (ws) => { ws.on('message', (message) => { /* 处理消息 */ }) });。4. 发送数据: ws.send(data) 将数据发送给客户端。 |
| 3 | 原生 WebSocket API | 简单实时交互、数据监控系统、实时图表更新 | 1. 原生 WebSocket API,轻量级,浏览器端直接支持。 2. 不依赖外部库,适合简单的实时交互场景。 | 1. 创建连接:const ws = new WebSocket('ws://server')。2. 监听连接状态:使用 ws.onopen 和 ws.onclose 处理连接的开启与关闭。3. 接收消息:使用 ws.onmessage 处理接收到的数据。4. 发送消息:通过 ws.send(data) 将数据发送到服务器。5. 连接关闭:使用 ws.close() 关闭 WebSocket 连接。 |
2. websocket优缺点
| 方面 | 优点 | 缺点 |
|---|---|---|
| 实时通信 | 全双工通信,低延迟,适用于实时应用(如聊天、游戏、股票推送)。 | 长连接占用资源,并发量大时对服务器压力大,需优化连接管理。 |
| 效率 | 建立一次连接后,数据持续传输,避免 HTTP 多次握手,通信效率高。 | 短期交互场景连接开销大,非持续通信不划算。 |
| 带宽使用 | 传输轻量,按需发送数据,减少不必要的带宽消耗,适合大数据量实时传输场景。 | 长时间不活跃仍占用连接,需心跳机制维持,增加管理复杂度。 |
| 复杂度 | 简化数据同步,单一连接实现复杂通信,适合前后端实时交互。 | 需要处理连接中断、重连等问题,维护成本较高,需完善的异常处理机制。 |
| 兼容性 | 现代浏览器广泛支持,应用场景多样,如金融、协作等。 | 部分老旧浏览器不支持,需降级方案(如轮询、SSE)。 |
3. websocket 处理亿万级大数据
| 序号 | 性能瓶颈 | 详细可落地解决方案 |
|---|---|---|
| 1 | 高频数据推送导致页面频繁重绘,渲染卡顿 | 1. 数据流与节流:通过前端的节流(throttle)技术,限制 WebSocket 的数据接收频率。例如,每秒最多处理 1 次数据更新,避免数据高频率传输导致频繁重绘。 2. 批量数据处理:将一段时间内收到的多条数据合并为一个批次进行渲染。使用 requestAnimationFrame 控制批量更新时机,减少 DOM 更新次数,确保页面流畅渲染。 |
| 2 | 大数据量传输导致网络带宽和数据解析压力 | 1. 数据压缩:在服务器端使用 gzip 或 Brotli 等压缩算法压缩 WebSocket 传输的数据,减少带宽消耗。特别是对于 JSON 格式的压缩,可以显著减少数据体积。2. 二进制传输:将 WebSocket 的 JSON 数据转换为 protobuf 或 MessagePack 的二进制格式,传输二进制数据不仅节省带宽,还能加快前端的解析速度。适用于需要高效传输大量数据的实时应用场景。 |
| 3 | 大量数据渲染导致内存占用过高,页面响应慢 | 1. 虚拟滚动技术:对于长列表或海量数据展示的页面,使用虚拟滚动(virtual scrolling)技术。仅渲染当前视口区域的数据,而非一次性渲染全部数据列表。可结合前端库(如 React-Virtualized 或 Vue Virtual Scroll List)来实现,适用于处理亿万级数据表格或列表的场景。 2. 分页加载:将数据按分页方式处理,结合按需加载策略,保证每次只加载当前页面的数据,避免一次性加载全部数据导致内存占用过高,特别适合大数据量可视化场景中的表格、列表展示。 |
| 4 | 高频数据更新导致 DOM 操作过多 | 1. 防抖与节流处理:对于高频率数据更新操作(如设备状态或市场数据),使用防抖(debounce)或节流技术。防抖可以在数据稳定后再进行 DOM 更新,而节流可以控制更新频率,确保每隔一段时间(如 2 秒)才触发一次更新,减少不必要的 DOM 操作。 2. 合并更新 DOM:通过数据的合并处理,在每次更新时合并多条数据并一次性更新 DOM,避免频繁操作 DOM,提升页面性能。 |
| 5 | WebSocket 长时间连接不稳定,可能断开 | 1. 心跳机制:在 WebSocket 中设置定期发送心跳包(如每 30 秒发送一次 ping 消息),检测连接状态,防止 WebSocket 连接断开。 2. 自动重连机制:使用 WebSocket 的 onclose 事件监听连接断开,并在断开时自动重连,恢复 WebSocket 会话的同时确保之前的状态或数据被完整恢复。此方案可以保证长时间的稳定连接,适用于需要长时间实时连接的业务场景,如在线监控系统。 |
| 6 | 大数据量图表的实时渲染压力大 | 1. 分块渲染:对于大数据量的图表,使用分块渲染技术。将数据分为多个小块,逐步渲染,避免一次性加载和渲染过多数据造成的性能问题。适用于实时数据可视化中的大规模数据展示,如实时监控中的数据曲线或市场趋势图。 2. 按需加载:在实时数据图表中,只加载当前视图内的数据,未展示的数据推迟加载或不加载,减少一次性渲染的数据量,适用于实时监控大屏中需要频繁更新的数据图表场景。 |
| 7 | 高并发数据导致前端处理能力不足 | 1. Web Workers 多线程处理:使用 Web Workers 将复杂的计算任务或大数据解析任务放到后台线程处理,避免阻塞主线程,提升前端的处理能力。Web Workers 可以用于处理数据分片、数据压缩解压等耗时任务,保证主线程专用于渲染。 2. 优先级调度:为关键数据(如告警信息或核心业务数据)设置高优先级,优先处理和渲染,延迟处理非关键数据。 |
| 8 | 前端内存泄漏导致性能下降 | 1. 内存优化与资源清理:确保 WebSocket 连接、数据缓存和事件监听器在不需要时被正确释放,避免内存泄漏。可以通过 ws.close() 正确关闭 WebSocket,移除所有事件监听器,确保对象在不使用时被垃圾回收。2. 内存检测和优化工具:使用浏览器内置的开发者工具(如 Chrome DevTools)进行内存泄漏检测,找到长时间运行后内存持续增长的原因,并优化数据缓存和事件处理机制,适用于需要长时间运行的大数据监控场景。 |
| 9 | 海量数据图表渲染导致页面崩溃 | 1. 简化图表数据:对于海量数据展示,简化图表中的非关键数据,仅显示核心数据指标,减少图表数据量,提升渲染性能。可以通过降低数据采样频率(如每分钟显示一次数据)或数据聚合(如每小时的最大值)来减少渲染压力,适用于需要展示高频变化数据的场景。 2. 高性能图表库:使用专为大数据量优化的图表库,如 ECharts 的大数据模式,或者 Highcharts 提供的 DataGrouping 功能,减少数据点渲染压力,提高整体性能。 |
16. 代码题
1. 百度
1. flex三行三列布局

代码实现
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<style>
.container {
width: 400px;
padding: 20px;
box-sizing: border-box;
display: flex;
flex-wrap: wrap;
justify-content: space-between;
/* gap: 20px 0;:为 flex 布局中的项⽬增加了垂直⽅向的 20px 间距,同时保持⽔平⽅向上的⾃动间距。这样可以确保
盒⼦之间的间距更加均匀,不需要额外的 margin。*/
gap: 20px 0;
border: 1px solid red;
}
.box {
width: 100px;
height: 50px;
background-color: red;
color: white;
text-align: center;
line-height: 50px;
}
</style>
</head>
<body>
<div class="container">
<div class="box">宽: 100px</div>
<div class="box">宽: 100px</div>
<div class="box">宽: 100px</div>
<div class="box">宽: 100px</div>
<div class="box">宽: 100px</div>
<div class="box">宽: 100px</div>
<div class="box">宽: 100px</div>
<div class="box">宽: 100px</div>
</div>
</body>
</html>
2. 自定义弹框次数限制
1.封装⼀个⾃定义弹框,每天弹框限制次数 次⽇重置弹框次数
function showPopupLimited() {
const maxPopupsPerDay = 3; // 每天弹框限制次数
const today = new Date().toLocaleDateString(); // 获取今天的⽇期,格式为 YYYY/MM/DD
// 从 LocalStorage 中获取弹框数据
let popupData = JSON.parse(localStorage.getItem('popupData')) || { date: today, count: 0 };
// 检查⽇期是否已改变,如果⽇期不同则重置计数器
if (popupData.date !== today) {
popupData.date = today;
popupData.count = 0;
}
// 如果今天的弹框次数⼩于 3,则继续弹框
if (popupData.count < maxPopupsPerDay) {
alert('这是弹框'); // 弹框内容
popupData.count++; // 增加弹框计数
}
// 更新 LocalStorage 中的数据
localStorage.setItem('popupData', JSON.stringify(popupData));
}
// ⻚⾯加载时执⾏
window.onload = showPopupLimited;
3. 获取数组出现频率最高的前两个数字
// 示例⽤法
let arr = [1, 3, 5, 3, 1, 3, 5, 1, 5, 5, 5, 7, 7, 7, 7, 7, 7, 9, 9];
console.log(findTopTwoFrequentNumbers(arr)); // 输出 [7, 5]
function findTopTwoFrequentNumbers(arr) {
// 使⽤ Map 来存储数字和它们的出现频率
const frequencyMap = new Map();
// 遍历数组,记录每个数字的频率
for (let num of arr) {
if (frequencyMap.has(num)) {
frequencyMap.set(num, frequencyMap.get(num) + 1);
} else {
frequencyMap.set(num, 1);
}
}
// 将 Map 转换为数组,并按频率进⾏降序排序
const sortedByFrequency = Array.from(frequencyMap.entries()).sort(
(a, b) => b[1] - a[1]
);
console.log(sortedByFrequency, 11);
// 获取频率最⾼的前两个数字
const topTwoNumbers = sortedByFrequency
.slice(0, 2)
.map((item) => item[0]);
return topTwoNumbers;
}
2. 美团
1. 定义一个 getDetails 方法,1秒内没有返回的话就取消请求
// 定义⼀个 getDetails ⽅法,1秒内没有返回的话就取消请求
function getDetailsWithTimeout(url) {
// 创建 AbortController 实例,⽤于取消请求
const controller = new AbortController();
const signal = controller.signal;
// 创建⼀个超时的 Promise,在1秒后触发
const timeoutPromise = new Promise((_, reject) => {
const timeoutId = setTimeout(() => {
// 超时后调⽤ controller.abort() 取消请求
controller.abort();
reject(new Error('请求超时,已取消'));
}, 1000); // 设置超时时间为 1 秒
});
// ⼯作中 都是规范 驼峰命名 有意义的名字
// 发送⽹络请求
const fetchPromise = fetch(url, { signal })
.then(response => {
// 检查请求是否成功
if (!response.ok) {
throw new Error('⽹络请求失败');
}
return response.json(); // 解析返回的 JSON 数据
});
// 使⽤ Promise.race 来同时处理超时和⽹络请求
return Promise.race([fetchPromise, timeoutPromise])
.catch(error => {
if (error.name === 'AbortError') {
console.error('请求被取消');
}
throw error; // 抛出错误,供调⽤⽅处理
});
}
// 调⽤⽅法并处理结果
getDetailsWithTimeout('https://api.example.com/details')
.then(data => {
console.log('请求成功:', data);
})
.catch(error => {
console.error('请求失败:', error.message);
});
2. 任意层级的数组拍平
任意层级的数组拍平 [123,[1],[[123] => [123,1,123]
// 任意层级数组拍平
const flattenArray = (arr) => arr.reduce((acc, val) => acc.concat(Array.isArray(val) ? flattenArray(val) :
val), []);
// 测试⽤例
const nestedArray = [123, [1], [[123]]];
console.log(flattenArray(nestedArray)); // 输出: [123, 1, 123]
3. 版本号数组排序
给定⼀组版本号数组 ["0.1.1", "2.3.3", "0.302.1", "4.2", "4.3.5", "4.3.4.5", "4.3.5.5"] ,现在需要对其进⾏排序。 排序后的结果为: ["4.3.5.5", "4.3.4.5", "4.3.5", "4.2", "2.3.3", "0.302.1", "0.1.1"] 要求:按照版本号从⼤到⼩进⾏排序。
// 版本号排序函数
const sortVersions = (versions) =>
versions.sort((a, b) => {
// 将版本号按 "." 分割并转成数字数组
const aParts = a.split('.').map(Number);
const bParts = b.split('.').map(Number);
// 找到最⻓的版本号部分⻓度
const maxLength = Math.max(aParts.length, bParts.length);
// 逐位⽐较每⼀部分的版本号
for (let i = 0; i < maxLength; i++) {
const aVal = aParts[i] || 0; // 如果该位不存在,视为 0
const bVal = bParts[i] || 0; // 如果该位不存在,视为 0
if (aVal !== bVal) return bVal - aVal; // 若该位不等,进⾏降序排序
}
return 0; // 若所有部分相等,视为相同版本
});
// 示例⽤例
const versions = ["0.1.1", "2.3.3", "0.302.1", "4.2", "4.3.5", "4.3.4.5", "4.3.5.5"];
console.log(sortVersions(versions));
// 输出: ["4.3.5.5", "4.3.4.5", "4.3.5", "4.2", "2.3.3", "0.302.1", "0.1.1"]
4. react 自定义hooks
实现倒计时功能10-0,到0时⾃动停⽌,并提供开始、暂停及重置⽅法
import { useState, useEffect, useRef } from 'react';
/**
* ⾃定义Hook⽤于实现倒计时功能
* @param {number} initialCount - 倒计时开始的秒数,默认为10秒
* @returns {Array} 包含倒计时的秒数、开始、暂停和重置功能的⽅法数组
**/
function useCountdown(initialCount = 10) {
// 倒计时的当前秒数
const [count, setCount] = useState(initialCount);
// 控制倒计时是否激活的状态
const [isActive, setIsActive] = useState(false);
// 使⽤ref来存储定时器ID,避免重新创建影响性能
const intervalRef = useRef(null);
// 副作⽤处理倒计时逻辑
useEffect(() => {
// 如果倒计时激活且当前秒数⼤于0,则开始计时
if (isActive && count > 0) {
intervalRef.current = setInterval(() => {
setCount((prevCount) => prevCount - 1);
}, 1000);
} else if (count === 0 || !isActive) {
// 如果当前秒数为0或倒计时不激活,清除定时器
clearInterval(intervalRef.current);
}
// 组件卸载时清除定时器,防⽌内存泄漏
return () => clearInterval(intervalRef.current);
}, [isActive, count]); // 依赖项包括倒计时激活状态和当前秒数
// 开始倒计时的⽅法
const start = () => {
setIsActive(true);
};
// 暂停倒计时的⽅法
const pause = () => {
setIsActive(false);
clearInterval(intervalRef.current);
};
// 重置倒计时的⽅法
const reset = () => {
setIsActive(false);
setCount(initialCount);
clearInterval(intervalRef.current);
};
// 返回倒计时的秒数和控制⽅法
return [count, start, pause, reset];
}
export default useCountdown;
3. 其他
1. 函数柯里化
function curry(fn) {
// ⿏标划线
// 获取原函数的参数个数
const arity = fn.length;
return function curried(...args) {
// 如果传⼊的参数数量⼤于或等于原函数的参数个数,则调⽤原函数
if (args.length >= arity) {
return fn(...args);
} else {
// 否则返回⼀个新的函数,继续收集参数
return function (...moreArgs) {
return curried(...args, ...moreArgs);
};
}
};
}
// 示例函数
function sum(a, b, c) {
return a + b + c;
}
// 柯⾥化 sum 函数
const curriedSum = curry(sum);
console.log(curriedSum(1)(2)(3)); // 输出: 6
console.log(curriedSum(1, 2)(3)); // 输出: 6
console.log(curriedSum(1)(2, 3)); // 输出: 6
2. 最长递增子序列
function lengthOfLIS(nums) {
// 边界情况处理:如果数组为空,直接返回0
if (nums.length === 0) return 0;
// tails 数组⽤于存储当前最⻓递增⼦序列的最⼩末尾元素
const tails = [];
// 遍历数组中的每个元素
for (let num of nums) {
// 使⽤⼆分查找在 tails 数组中寻找 num 的插⼊位置
let left = 0, right = tails.length;
while (left < right) {
let mid = Math.floor((left + right) / 2);
if (tails[mid] < num) {
left = mid + 1;
} else {
right = mid;
}
}
// 如果 num ⼤于 tails 中所有元素,则将 num 添加到 tails 末尾
// 否则,替换掉第⼀个⼤于或等于 num 的元素,保持 tails 有序
if (left === tails.length) {
tails.push(num);
} else {
tails[left] = num;
}
}
// tails 数组的⻓度就是最⻓递增⼦序列的⻓度
return tails.length;
}
// 示例测试
const nums = [10, 9, 2, 5, 3, 7, 101, 18];
console.log(lengthOfLIS(nums)); // 输出: 4
3. 旋转链表
题⽬描述: 给定⼀个链表的头节点,将链表每个节点向右移动 k 个位置。原链表中最后 k 个节点将依次移动到表头,⽽其他节点依次向右移动。要求返回旋转后的链表。
输⼊:
- 链表头节点 head 。
- 整数 k ,表示右移的位数。
输出:
- 旋转后的链表。
// 定义链表节点的类
class ListNode {
constructor(val, next = null) {
this.val = val;
this.next = next;
}
}
// 旋转链表的函数,最优⽅案
function rotateRight(head, k) {
// 边界情况处理:空链表或 k 为 0 时,直接返回原链表
if (!head || !head.next || k === 0) return head;
// 计算链表⻓度,并同时找到尾节点
let length = 1;
let tail = head;
while (tail.next) {
tail = tail.next;
length++;
}
// 实际的旋转步数应是 k 对链表⻓度取模
k = k % length;
if (k === 0) return head; // 如果 k 是 0,链表⽆需旋转
// 将链表连成环
tail.next = head;
// 找到新的尾节点,新的头节点是新尾节点的下⼀个
let newTail = head;
for (let i = 1; i < length - k; i++) {
newTail = newTail.next;
}
let newHead = newTail.next; // 新头节点
newTail.next = null; // 断开环
return newHead;
}
// 测试⽤例
function createLinkedList(arr) {
let dummy = new ListNode(0);
let current = dummy;
for (let num of arr) {
current.next = new ListNode(num);
current = current.next;
}
return dummy.next;
}
function printLinkedList(head) {
let result = [];
while (head) {
result.push(head.val);
head = head.next;
}
console.log(result);
}
// 示例测试
let head = createLinkedList([1, 2, 3, 4, 5]);
let k = 2;
let newHead = rotateRight(head, k);
printLinkedList(newHead); // 输出 [4, 5, 1, 2, 3]
4. 根据某个字段去重
题⽬: 给定⼀个对象数组 list ,每个对象包含⼀个 name 字段。实现⼀个 list.unique ⽅法,该⽅法按照对象的 name 字段去重,并返 回去重后的 name 字段集合。 要求:
- 每个对象都包含 name 和其他字段。
- 去重时只考虑 name 字段。
- 返回结果为去重后的 name 字段集合,格式为数组。
// 输⼊:
list = [
{ name: "a", age: 18 },
{ name: "b", age: 20 },
{ name: "a", age: 22 },
{ name: "c", age: 19 },
{ name: "b", age: 25 }
]
// 输出:
["a", "b", "c"]
代码实现
// 定义list的结构
const list = [
{ name: "a", age: 18 },
{ name: "b", age: 20 },
{ name: "a", age: 22 },
{ name: "c", age: 19 },
{ name: "b", age: 25 }
];
// 添加unique⽅法到Array的原型上
Array.prototype.unique = function () {
// 使⽤Set保存name字段的唯⼀值
const uniqueNames = new Set();
// 遍历当前数组,提取name字段
for (const item of this) {
if (item && item.name) {
uniqueNames.add(item.name); // 利⽤Set的特性去重
}
}
// 返回去重后的name集合,转换为数组返回
return [...uniqueNames];
};
// 调⽤unique⽅法
const uniqueNames = list.unique();
console.log(uniqueNames); // 输出去重后的结果 ["a", "b", "c"]
16. 非技术面试
| ⾯试问题 | 最优⽅案 | 口语化话术示例 |
|---|---|---|
| 离职原因 | 清晰、专业地说明离职原因,重点强调对职业发展的追求,不涉及负⾯评价。 | 组织架构调整,个⼈原因,项⽬增量少,维护多,在那家公司,我已经实现了主要的项⽬⽬标,并且在技术和管理⽅⾯都得到了很好的锻炼。现在,我希望找到⼀个能够提供更⼤技术挑战和领导机会的⻆⾊,以便继续提升⾃⼰。 |
| 你有什么问题要问我吗 | 提出有针对性的问题,显示对公司的深⼊了解和兴趣,关注公司⽂化、技术⽅向和团队合作。 | ⾯试反馈,⼏轮⾯试,技术栈,公司业务,如果我能⼊职,我主要负责哪⼀块,我对贵公司⾮常感兴趣,特别想了解贵公司在技术创新⽅⾯的具体策略是什么?团队合作的流程和⽂化是怎样的?还有,公司未来 1-2 年内在技术领域有怎样的发展计划?这些信息将帮助我更好地了解我能如何融⼊贵公司的团队和⽬标。 |
| 为什么考虑来xx城市 | 明确城市的职业和⽣活优势,突出与个⼈职业规划的契合度。 | 家⼈,朋友,同学都在这⾥,打算⻓期发展,我选择 XX 城市主要是因为这⾥拥有⼀个活跃的技术社区和丰富的职业机会。此外,城市的⽣活质量和环境也⾮常适合我。这些因素都与我的职业⽬标和⽣活需求⾼度契合。 |
| 期望薪资 | 给出明确的薪资范围,并解释该范围如何基于市场⾏情和个⼈经验。 | 我的薪资期望在 X 万到 Y 万之间。这⼀范围是基于我对市场薪资⽔平的了解以及我在前端开发领域的丰富经验来设定的。我相信这个薪资⽔平能够与我为公司带来的价值和我的技能背景相匹配。 |
| 你手上有offer吗 | 诚实地回答是否有其他offer,并简要说明这些offer 的进展情况,强调⾃⼰对⽬标公司的兴趣。 | ⽬前,我确实在考虑⼏个其他的 offer,但我对贵公司的机会特别感兴趣,因为它符合我的职业发展⽬标和个⼈价值观。我希望能进⼀步了解这个职位的具体细节,以便做出最合适的决定。 |
| 你目前的级别 | 详细说明当前职位的级别和主要职责,并解释如何与⽬标职位相匹配。 | 我⽬前在 X 公司担任资深前端⼯程师,主要负责项⽬的技术架构设计、团队协作以及技术创新。我的职责包括从技术⽅案的制定到团队的⽇常管理。我希望在贵公司找到⼀个能够继续发挥我技术和管理能⼒的职位,以匹配我的经验和职业⽬标。 |
| 你的绩效考核依据 | 描述绩效考核的主要标准和如何与公司⽬标⼀致,解释⾃⼰如何达成这些标准。 | 在我⽬前的公司,绩效考核主要依据项⽬交付质量、Bug率,团队协作效果和技术创新能⼒。这些标准确保了我们不仅达成了项⽬⽬标,⽽且在团队和技术⽅⾯都有所提升。我通常会通过制定明确的⽬标和持续的⾃我评估来确保我能够满⾜这些考核标准。 |